Advanced Visualization
- 강의자료 다운로드: click me
학습 목표
-
시각화에 대한 기본 지식
-
대시보드 설계 원칙
-
언어별 시각화 도구
-
Plotly소개 -
Dash소개 -
Plotly와Dash연동 -
대시보드 구현을 위한 다양한 선택
-
대시보드 구현
시각화에 대한 기본 지식
분석 결과를 효과적으로 전달하는 커뮤니케이션 도구
데이터 시각화는 복잡한 수치, 표, 모델 결과를 한눈에 이해할 수 있도록 돕는 핵심 커뮤니케이션 도구이다. 분석가의 역할은 데이터를 해석하는 것에서 끝나는 것이 아니라, 이해관계자가 빠르고 정확하게 판단할 수 있도록 돕는 것이다.
좋은 시각화는 별도의 설명이 없어도 핵심 메시지가 자연스럽게 전달된다. 숫자의 나열을 이해에서 공감으로 전환시키며, 시각적 설득력을 높여준다.
효과적인 시각화는 리포트, 프레젠테이션, 대시보드에서 핵심 정보의 요약, 강조, 경고를 시각적 신호로 전달할 수 있게 한다.

스토리텔링을 통한 인사이트 전달
시각화는 차트를 나열하는 것이 아니라, 데이터가 전달하고자 하는 메시지를 이야기 흐름으로 구성하는 과정이다. 따라서 단순히 보여주는 것이 아니라 이해와 행동을 이끌어내는 스토리라인이 필요하다.
| 단계 | 핵심 질문 | 역할 |
|---|---|---|
| Context (배경) | 무엇을 왜 분석했는가? | 문제 정의와 관심 유도 |
| Insight (발견) | 데이터가 어떤 사실을 보여주는가? | 핵심 메시지 전달 |
| Action (행동) | 그래서 무엇을 해야 하는가? | 의사결정 및 실행 유도 |
Context 단계에서는 배경과 가설을 제시하며 시각화의 목적과 분석의 방향성을 알려준다.
Insight 단계에서는 차트를 통해 데이터가 말하는 핵심 결과를 전달한다.
Action 단계에서는 분석을 통해 도출된 실행 방안 또는 개선 방향을 제시한다.
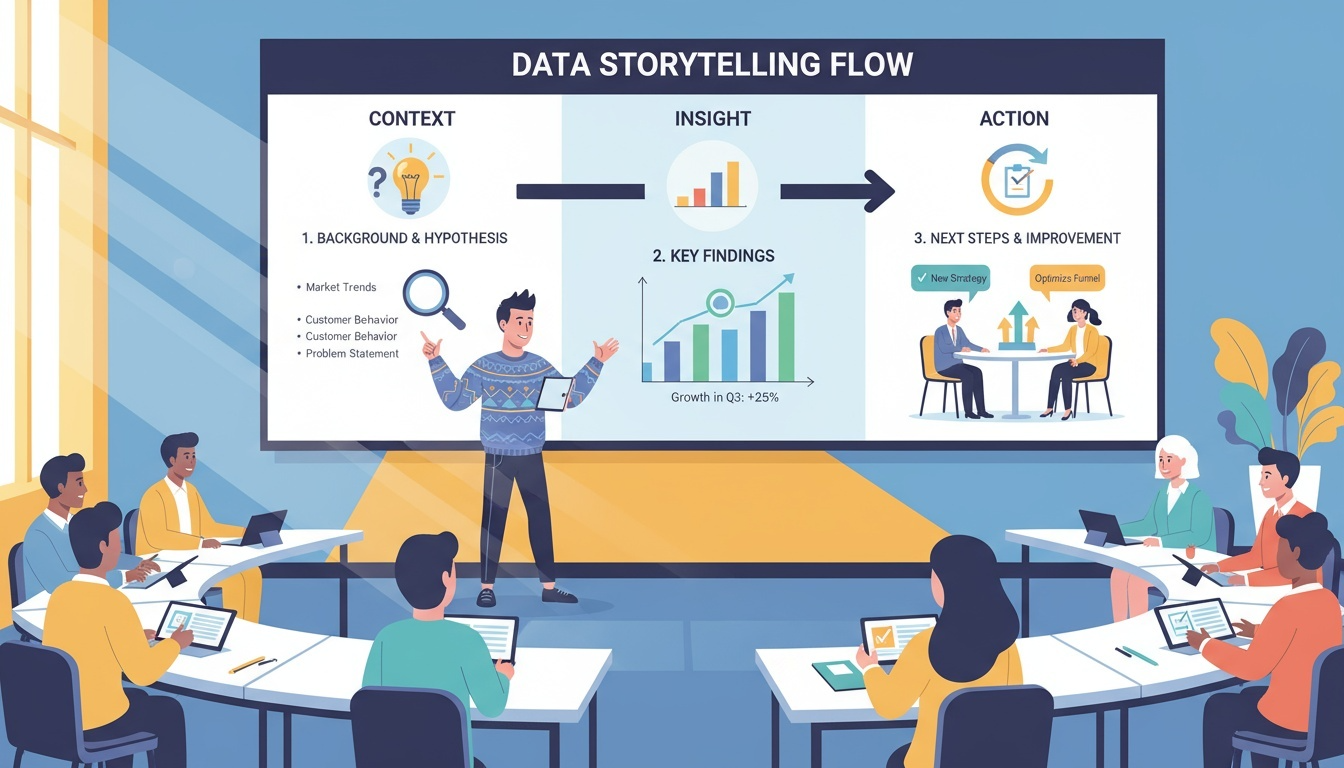
"왜 이 차트를 선택했는가?"의 중요성
시각화는 데이터를 전달하기 위한 의도적 선택의 결과이며, 목적에 따라 차트는 달라져야 한다. 데이터의 구조, 분석 목표, 강조 포인트를 고려하여 가장 적합한 시각화를 선택해야 한다.
차트 선택 기준 체크리스트
| 고려 요소 | 핵심 질문 | 예시 |
|---|---|---|
| 데이터 유형 | 데이터는 수치형인가, 범주형인가? | 연속형 vs 범주형 |
| 분석 목표 | 비교, 분포, 추세, 상관, 구성 중 무엇인가? | 추세 파악, 상관 분석 등 |
| 강조 포인트 | 무엇을 가장 강조할 것인가? | 이상치, 변화율, 상관구조 |
| 대상의 문해력 | 독자의 데이터 이해 수준은 어떤가? | 단순 vs 고급 차트 |
| 맥락/제약 | 어떤 환경에서 사용되는가? | 보고용, 인쇄용, 모바일 등 |
적절한 차트를 선택할 때는 시각화 자체뿐 아니라 대상 독자의 배경지식과 해석 능력도 고려해야 한다. 전달 목적과 상황에 맞지 않는 차트는 정보 해석의 왜곡을 초래할 수 있다.
목적에 따른 차트 선택
| 목적 | 흔한 실수(부적절) | 권장 차트(적절) |
|---|---|---|
| 시간 추세 | 막대 그래프 | 선(line), 영역(area) |
| 두 변수 관계 | 막대 그래프 | 산점도(scatter), 회귀선 |
| 분포 파악 | 선 또는 막대 그래프 | 히스토그램, KDE, 바이올린 |
| 구성비 비교 | 선 그래프 | 파이/도넛, 스택형 막대 |
| 순위 비교 | 파이 차트 | 가로 막대 |
| 다변량 상관 | 다중 선 그래프 | 히트맵, 페어플롯, 평행좌표 |
핵심: “
왜 이 차트를 사용했는가?”를 한 문장으로 설명할 수 있어야 한다.
체크리스트: 좋은 시각화 vs 나쁜 시각화
좋은 시각화는 정보를 명확하게 전달하며, 관찰자가 올바르게 해석할 수 있도록 설계된다. 반면, 나쁜 시각화는 데이터의 의미를 흐리거나 왜곡할 수 있다.
좋은 시각화의 특징
-
축, 단위, 범례가 명확하게 표시된다.
-
불필요한 시각적 요소를 줄이고 데이터에 집중할 수 있도록 설계된다.
-
색상은 의미를 전달하기 위해 사용되며 색약·색맹을 고려한다.
-
핵심 메시지를 주석(Annotation)으로 강조한다.
-
관찰자가 다음 행동을 떠올릴 수 있도록 방향성을 제시한다.
나쁜 시각화의 특징
-
3D 효과나 과도한 장식으로 정보 전달이 방해된다.
-
파이 차트 조각이 많아 비교가 어려워진다.
-
y축 절단 등으로 시각적 왜곡을 유발한다.
-
메시지 없이 차트만 나열되어 해석이 어렵다.
대시보드 설계 원칙
대시보드(Dashboard)?
대시보드는 다양한 데이터를 한눈에 파악할 수 있도록 핵심 정보를 시각적으로 정리해 제공하는 화면이다. 사용자가 빠르게 현재 상황을 이해하고, 필요한 의사결정을 내릴 수 있도록 돕는 것이 대시보드의 목적이다.
대시보드의 중요성
대시보드는 단순히 여러 차트를 나열해놓은 페이지가 아니라, 문제 해결과 의사결정에 최적화된 정보 구조를 제공하는 데이터 커뮤니케이션 도구이다. 따라서 어떤 지표를 보여줄지, 어떤 시각화 형태를 사용할지, 어떤 흐름으로 배치할지에 대한 설계가 매우 중요하다.
대시보드의 활용
대시보드는 주로 경영, 마케팅, 운영 관리, 제조, 교육, IT 서비스 모니터링 등 다양한 분야에서 활용되며 사용자 역할에 따라 구성 방식이 달라질 수 있다. 예를 들어, 경영진은 요약된 KPI 중심의 전략적 대시보드를 사용하고, 실무자는 세부 지표와 실행 기반의 운영형 대시보드를 필요로 한다.
좋은 대시보드 사례
한 글로벌 제조기업의 운영팀 대시보드에서는 핵심 KPI(생산속도, 불량률, 다운타임)를 한 화면에 배치했다. 시계열 그래프, 게이지, 원형 요약 차트를 활용하여 현재 상태, 추세, 목표 대비 현황을 자연스럽게 파악할 수 있도록 설계했다.
사용자는 대시보드를 통해 5초 이내에 전체 상황을 이해할 수 있었고, 이상 상황 발생 시 색상 강조와 시각적 알림으로 즉각 대응이 가능했다. 그 결과 리포트 작성 시간이 단축되고, 실시간 모니터링과 의사결정 속도가 향상되었다.
참고 링크
나쁜 대시보드 사례
한 IT기업의 사내 대시보드에서는 KPI 20~30개가 화면에 빽빽하게 배치되어 있었다. 3D 차트, 과도한 색상, 장식 요소가 많아 가독성이 떨어졌고, 필수 정보조차 찾기 어려웠다.
사용자들은 대시보드를 제대로 활용하지 못해 데이터를 다운로드해 다시 가공해 사용하게 되었고, 실시간 모니터링 기능이 무의미해지면서 대시보드의 목적을 달성하지 못했다.
참고 링크
비교 요약
| 항목 | 좋은 대시보드 | 나쁜 대시보드 |
|---|---|---|
| 정보 우선순위 | 핵심 지표 위주, 시선 흐름 설계 | 너무 많은 지표가 동시에 노출 |
| 시각적 복잡성 | 단순, 가독성 중심, 여백 활용 | 장식 과다, 3D, 시각적 피로 유발 |
| 해석 용이성 | 축/단위/범례 명확, 직관적 | 정보 해석 난해, 혼란 초래 |
| 의사결정 연결성 | 인사이트 → 행동으로 연결 | 보여주기용, 실행 방향 제시 없음 |
| 사용자 경험 | 빠른 이해 및 즉시 대응 가능 | 사용자가 외부로 데이터 추출해 재가공 |
레이아웃 구성 원칙 (3-Panel Layout / F-Pattern / Z-Pattern)
대시보드는 화면을 어떻게 구성하느냐에 따라 정보 전달력과 사용자의 해석 속도가 달라진다. 효과적인 레이아웃은 사용자의 시선 흐름을 고려하여 핵심 정보 → 세부 정보 → 인사이트 확인으로 이어지는 자연스러운 구조를 만든다.
레이아웃 설계 시에는 시각적 우선순위와 정보 배치를 전략적으로 구성해야 하며, 대표적으로 3-Panel Layout, F-Pattern, Z-Pattern이 활용된다.
3-Panel Layout

-
화면을 상단, 좌측, 우측으로 나누어 정보 계층을 명확하게 구조화하는 방식이다.
-
상단에는 핵심 KPI와 전체 상황 요약을 배치하여 첫눈에 현황을 파악할 수 있도록 한다.
-
좌측에는 세부 지표, 추세 그래프, 상세 분석 정보를 배치하여 사용자가 원할 때 더 깊이 들어가 확인할 수 있게 한다.
-
우측에는 알림, 인사이트, 액션 아이템, 필터 또는 컨트롤 패널을 구성해 해석 이후 행동으로 이어지도록 설계한다.
F-Pattern Layout
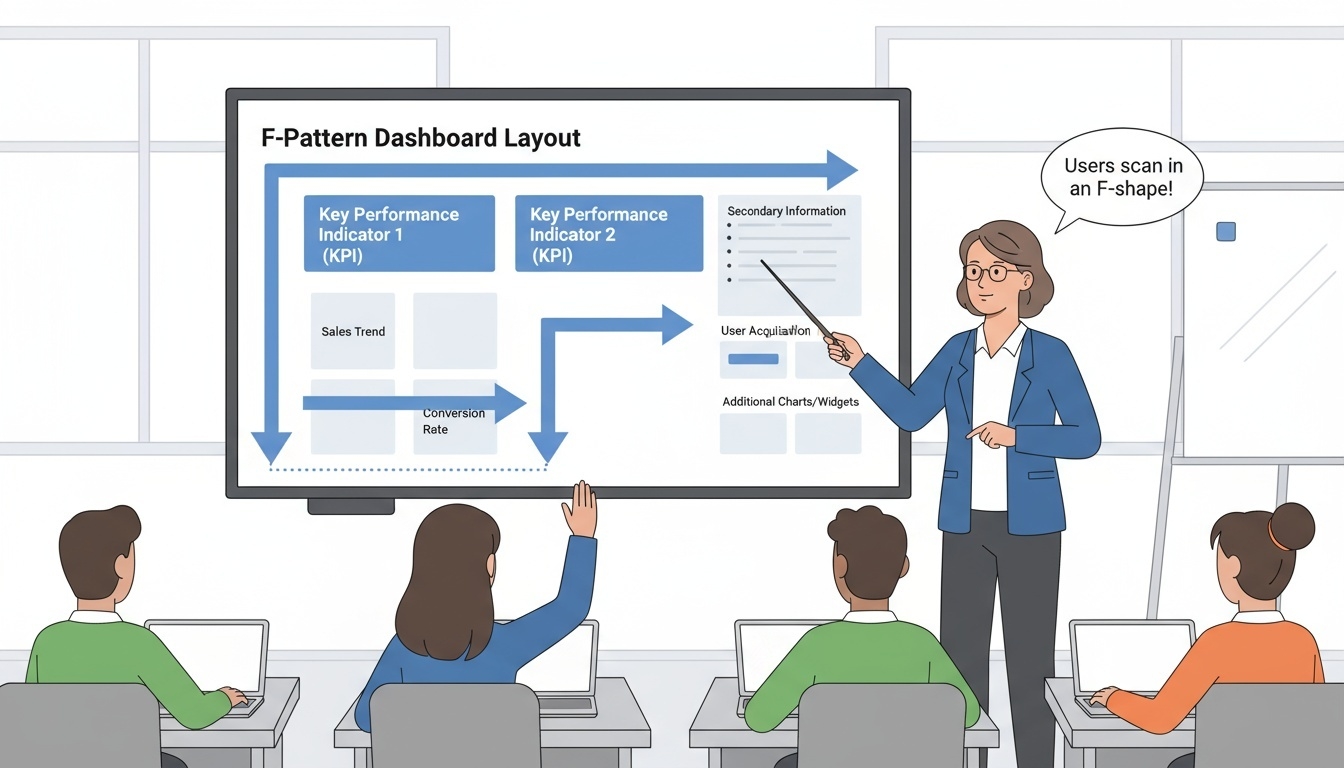
-
사용자의 시선 흐름이 “F” 형태로 움직인다는 웹·UI 연구 결과에 기반한 배치 방식이다.
-
사용자는 화면의 상단 왼쪽에서 시작해 오른쪽으로 시선을 이동한 뒤, 다시 왼쪽으로 내려오며 중요한 요소를 스캔한다.
-
핵심 KPI와 제목, 중요한 메시지를 상단 왼쪽에 배치하고, 그 옆에 보조 정보 또는 필터를 배치하면 인식 속도가 향상된다.
-
중간 영역에는 주요 차트와 비교 분석 정보를 배치하여 자연스럽게 시선이 집중되도록 한다.
Z-Pattern Layout

-
시선이 “Z” 형태로 상단 왼쪽 → 상단 오른쪽 → 하단 왼쪽 → 하단 오른쪽으로 이동하는 흐름을 기반으로 한다.
-
콘텐츠 양이 적고 메시지 전달이 명확해야 하는 발표형 대시보드나 단일 화면 요약 보고서에 적합하다.
-
상단에는 제목, 기간, 필터, 핵심 메시지를 배치하고, 중앙에는 주요 시각 정보를 배치하여 인사이트를 전달한다.
-
하단에는 결론, 다음 행동(Action Items), 또는 CTA(Call to Action)를 배치하여 행동 유도 효과를 높인다.
색상, 시선 흐름, 데이터 강조 기법
대시보드에서 색상, 시선 흐름, 강조 기법은 사용자가 정보를 빠르고 정확하게 해석하도록 돕는 핵심 시각화 요소이다. 이 세 요소를 적절히 활용하면 데이터 전달력이 높아지고, 사용자의 인지 부담이 줄어들며, 인사이트 전달 효과가 극대화된다.
색상(Color)의 활용

-
색상은 의미를 전달하기 위한 도구이며 장식용이 아니다.
-
데이터의 상태나 중요도에 따라 색상을 일관성 있게 사용해야 한다. (예: 초록=좋음, 노랑=주의, 빨강=위험)
-
색상 수는 최소화하여 시각적 복잡성을 줄이고, 색각 이상 사용자를 고려한 팔레트를 선택한다.
-
강조해야 할 데이터를 다른 색상으로 처리해 사용자의 눈이 자연스럽게 해당 요소에 집중되도록 한다.
시선 흐름(Eye Flow) 설계
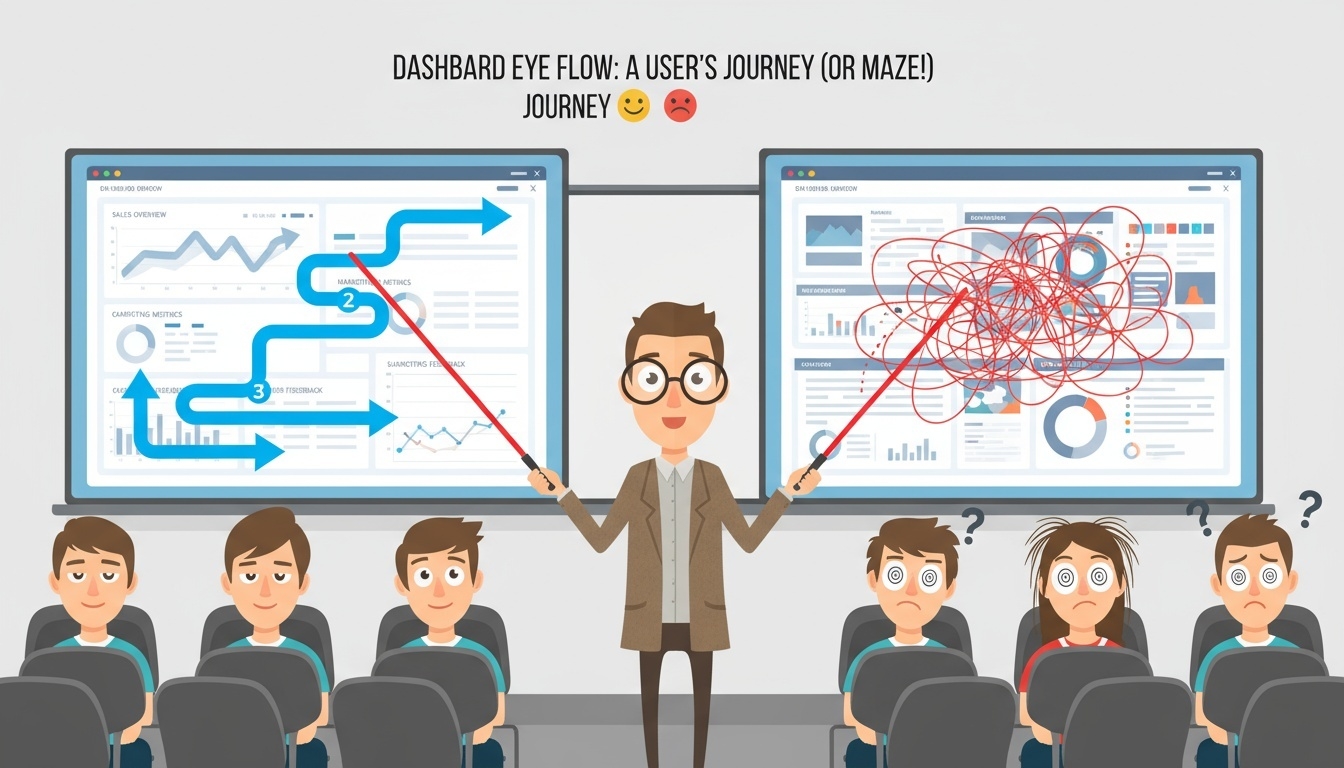
-
사용자의 시선 이동 경로를 고려하여 정보 배치를 설계해야 한다.
-
일반적으로 시선은 왼쪽 상단에서 시작해 오른쪽과 아래 방향으로 이동한다.
-
중요한 정보는 시선이 가장 먼저 닿는 위치에 배치하고, 세부 정보는 그 다음 순서에 배치해 계층 구조를 형성한다.
-
여백(Whitespace)과 정렬을 활용해 자연스러운 시선 흐름을 유도한다.
데이터 강조(Highlighting) 기법

-
차트나 지표에서 핵심 데이터 포인트를 색상, 굵기, 크기 변화, 주석(Annotation)으로 명확하게 강조한다.
-
트렌드 변화나 이상치 등 사용자가 주목해야 하는 요소는 시각적 신호를 통해 부각시키도록 처리한다.
-
불필요한 요소는 최소화하여 데이터 자체가 강조될 수 있는 환경을 만들어야 한다.
-
강조는 한 화면에 한두 개만 사용해 과도한 강조로 인한 혼란을 방지한다.
KPI 선정 전략
KPI(Key Performance Indicator, 핵심 성과 지표)?
조직이나 팀이 달성해야 할 목표의 성과를 측정하고 평가하기 위한 핵심 지표이다. 단순한 데이터 지표가 아니라, 전략과 실행을 연결하는 나침반 역할을 한다.
KPI는 무엇을 달성해야 하는지 방향성을 제시하며, 조직 구성원이 동일한 목표를 향해 움직일 수 있도록 기준을 제공한다.
따라서 KPI는 “성과가 좋다” 또는 “나쁘다”를 확인하는 수준을 넘어, 목표 달성 과정에서 필요한 행동을 이끌어내는 실행 중심의 지표라고 할 수 있다.
KPI의 활용 분야
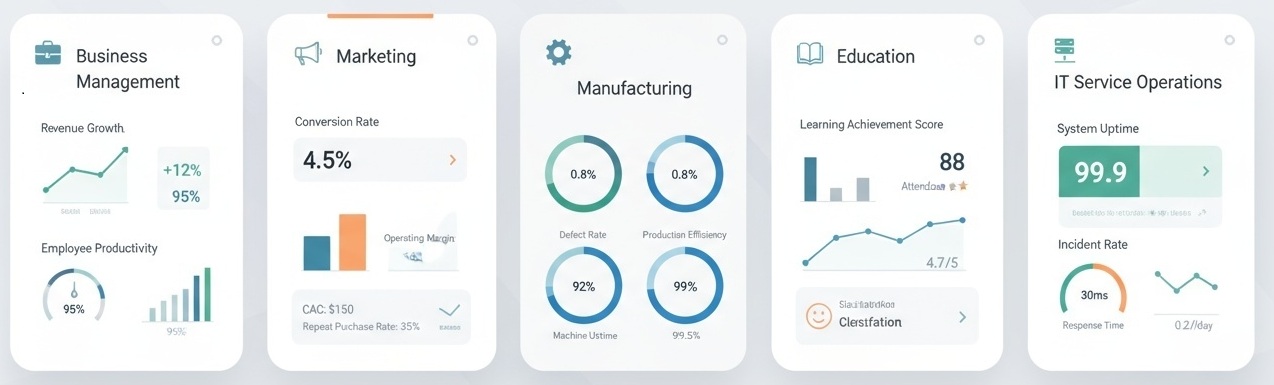
-
기업 경영, 마케팅, 영업, 재무, 인사, 교육, IT 서비스 운영, 제조 등 다양한 분야에서 활용된다.
-
마케팅에서는 전환율, 고객 획득 비용, 재구매율 등을 통해 캠페인의 성과를 측정한다.
-
제조 현장에서는 불량률, 생산성, 장비 가동률 등으로 운영 효율성과 품질을 관리한다.
-
교육에서는 학습 성취도, 출석률, 수업 만족도 등을 기반으로 교육의 효과성과 개선 방향을 판단한다.
-
IT 서비스에서는 시스템 가용성, 응답 속도, 장애 발생률 등으로 서비스 품질과 사용자 경험을 관리한다.
KPI의 중요성
-
KPI는 조직이 어디로 가야 하는지 명확한 방향성을 제시하여 목표 분산을 방지한다.
-
구성원들이 동일한 목표를 공유하도록 도와 팀 전체의 정렬(Alignment)을 강화한다.
-
KPI를 통해 현재 성과 수준을 진단하고, 필요한 개선 행동을 도출할 수 있다.
-
측정 가능한 결과를 기반으로 객관적인 평가와 의사결정을 가능하게 만든다.
-
적절한 KPI 설정은 조직의 성장 속도를 높이며, 잘못된 KPI는 잘못된 전략과 행동을 초래할 수 있다.
조직 목표와 직접 연결된 KPI 선택

-
KPI는 회사 또는 팀의 핵심 목표와 직접적으로 연관되어야 한다.
-
“왜 이 지표를 측정하는가?”라는 질문에 명확히 답할 수 있어야 한다.
-
조직의 전략 방향성과 일치하지 않는 지표는 과감히 제외한다.
성과에 영향을 미치는 선행지표와 후행지표 균형

-
KPI는 결과를 보여주는 후행지표(Lagging KPI)와 성과를 촉진하는 선행지표(Leading KPI)를 함께 고려해야 한다.
-
후행지표는 성과 확인용이라면, 선행지표는 개선 행동을 이끌어내는 역할을 한다.
-
예를 들어, 매출은 후행지표이고, 리드 전환율 또는 상담 응답 속도는 선행지표가 될 수 있다.
정량적 지표 중심, 필요 시 정성적 지표 보완
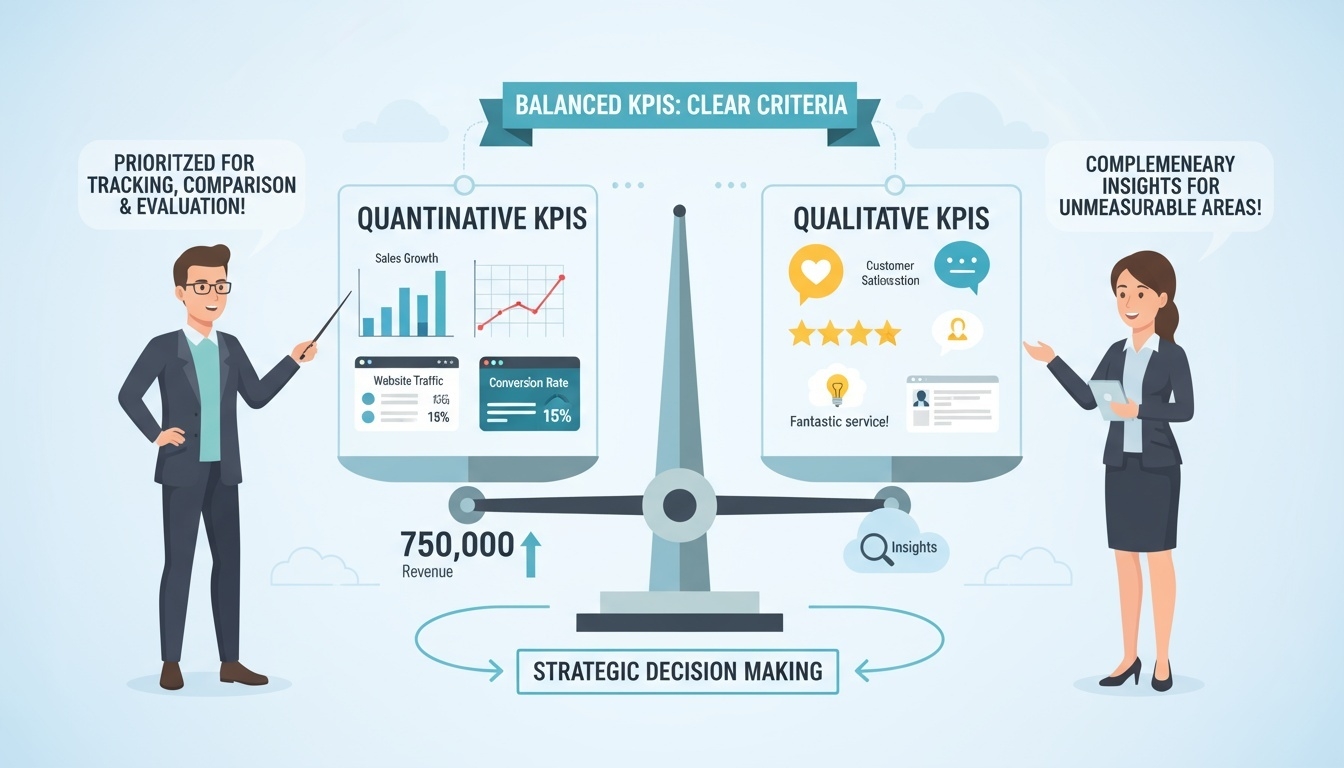
-
정량 지표는 비교·추적·평가가 용이하므로 KPI 선정 시 우선 고려한다.
-
정성 지표는 수치화가 어려운 영역(고객 만족도, 브랜드 이미지 등)에 한해 보완적으로 사용한다.
-
정성 지표 사용 시 측정 기준과 평가 방식을 명확히 정의해야 한다.
측정 가능성과 데이터 수집 용이성 확인

-
KPI는 반드시 지속적으로 측정 가능해야 하며, 데이터 수집·갱신 비용이 과도해서는 안 된다.
-
측정이 불가능하거나 일관된 데이터 확보가 어려운 지표는 KPI에서 제외한다.
-
자동 수집·자동 업데이트가 가능한 지표를 우선 고려하면 운영 효율성이 높아진다.
KPI 개수 최소화
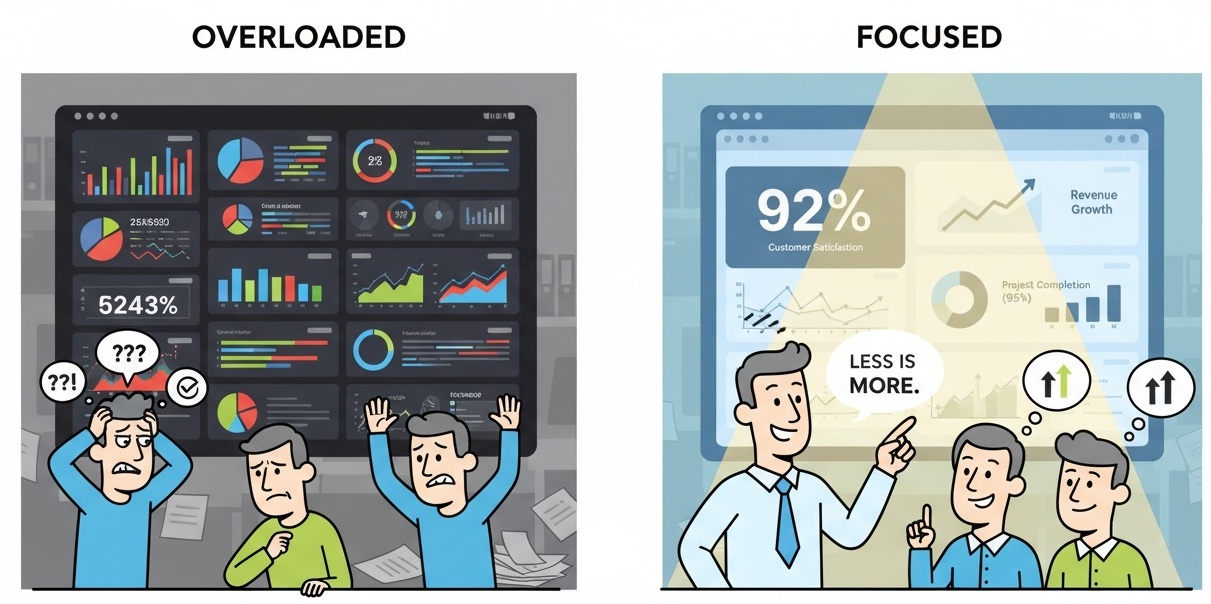
-
KPI는 적을수록 명확해진다.
-
일반적으로 조직 단위 KPI는 3~5개, 팀 단위 KPI는 5~7개 이내가 적정하다.
-
지표가 많아질수록 초점이 흐려지고 구성원들이 무엇을 중요하게 봐야 하는지 혼란이 생긴다.
언어별 시각화 도구
데이터 시각화 도구는 복잡한 데이터를 차트, 그래프, 지도, 대시보드 등의 시각적 형태로 표현하여 한눈에 이해할 수 있도록 돕는 소프트웨어 또는 라이브러리이다. 데이터를 숫자, 표 형태 그대로 전달하는 대신, 시각적으로 구조화해 정보의 흐름과 패턴, 인사이트를 빠르게 파악할 수 있도록 지원한다.
시각화 도구는 단순히 “예쁘게 차트를 그리는 기능”을 넘어, 데이터 분석 과정 전반에서 의사결정을 지원하는 핵심 도구로 활용된다. 사용 목적에 따라 통계 그래프, 인터랙티브 차트, BI 대시보드, 지도 기반 시각화 등 다양한 형태의 시각 표현을 제공한다.
언어별 대표적인 시각화 라이브러리/프레임워크
| 언어 | 대표 도구 | 주요 활용 | 제약/비고 |
|---|---|---|---|
| Python | Matplotlib / Seaborn | 통계 차트, 과학적 시각화, 이미지 저장 |
기본은 정적 출력, 복잡한 인터랙션 한계 |
| R | ggplot2 / Shiny | 통계 분석, 리포트, 대화형 웹앱 |
Shiny는 서버 구성 필요, 성능 튜닝 요구 |
| JavaScript | D3.js / ECharts | 맞춤형 웹 시각화, 대화형 대시보드 |
초기 학습 부담 큼, DOM 성능 고려 필요 |
| Java | JFreeChart | 엔터프라이즈 리포트, 데스크톱 앱 |
디자인 커스터마이즈 제약, 웹 통합 추가 작업 |
| C# (.NET) | Power BI | BI 대시보드, 데스크톱/모바일 리포트 |
라이선스 비용 발생, 복잡 커스터마이징 시 추가 개발 필요 |
대시보드 도구
각 프로그래밍 언어는 데이터 시각화뿐 아니라 대시보드 제작을 위한 대표 도구가 존재한다. 언어별 생태계를 이해하면, 목적과 상황에 따라 적합한 기술을 선택할 수 있다.
| 언어 | 대표 대시보드 도구 | 주요 활용 | 제약/비고 |
|---|---|---|---|
| Python | Dash, Streamlit |
데이터 분석·AI 모델 결과를 공유하는 웹 대시보드 개발 |
커스텀 UI 한계(특히 Streamlit), 복잡 서비스 확장 시 추가 개발 필요 |
| R | Shiny | 통계 분석 리포트, 연구용 인터랙티브 앱 |
서버 구성 필요, 사용자 증가 시 성능 튜닝 필수 |
| JavaScript | Dash for JS, Looker, Apache Superset |
프로덕션급 웹 대시보드, 맞춤형 UI/UX, BI 환경 구축 |
JS 기술 스택 학습 필요, 유지보수 비용 증가 |
| Java | Tableau 연동, JSP 기반 Custom Dashboard |
엔터프라이즈 데이터 리포트 및 BI 시스템 연계 |
직접 대시보드 구성보다 외부 BI 솔루션과 연계가 일반적 |
| C# (.NET) | Power BI | 기업 BI 대시보드, 실시간 매출/운영 모니터링 |
라이선스 비용 발생, 고도 커스터마이징 시 추가 개발 필요 |
| No-Code/Low-Code | Looker Studio, Tableau |
빠른 리포트 제작, 마케팅/운영 지표 공유, 비개발자 친화적 |
복잡한 로직 및 커스텀 기능 구현에 한계 |
Plotly 소개
Plotly는 대화형(Interactive) 데이터 시각화 라이브러리로, 웹 기반 차트를 손쉽게 만들 수 있도록 지원하는 파이썬 도구이다.
정적인 matplotlib 기반 그래프와 달리, Plotly는 줌 확대, 마우스 오버 툴팁, 범례 제어, 필터링 등 사용자 상호작용 기능을 기본 제공한다.
Plotly의 특징
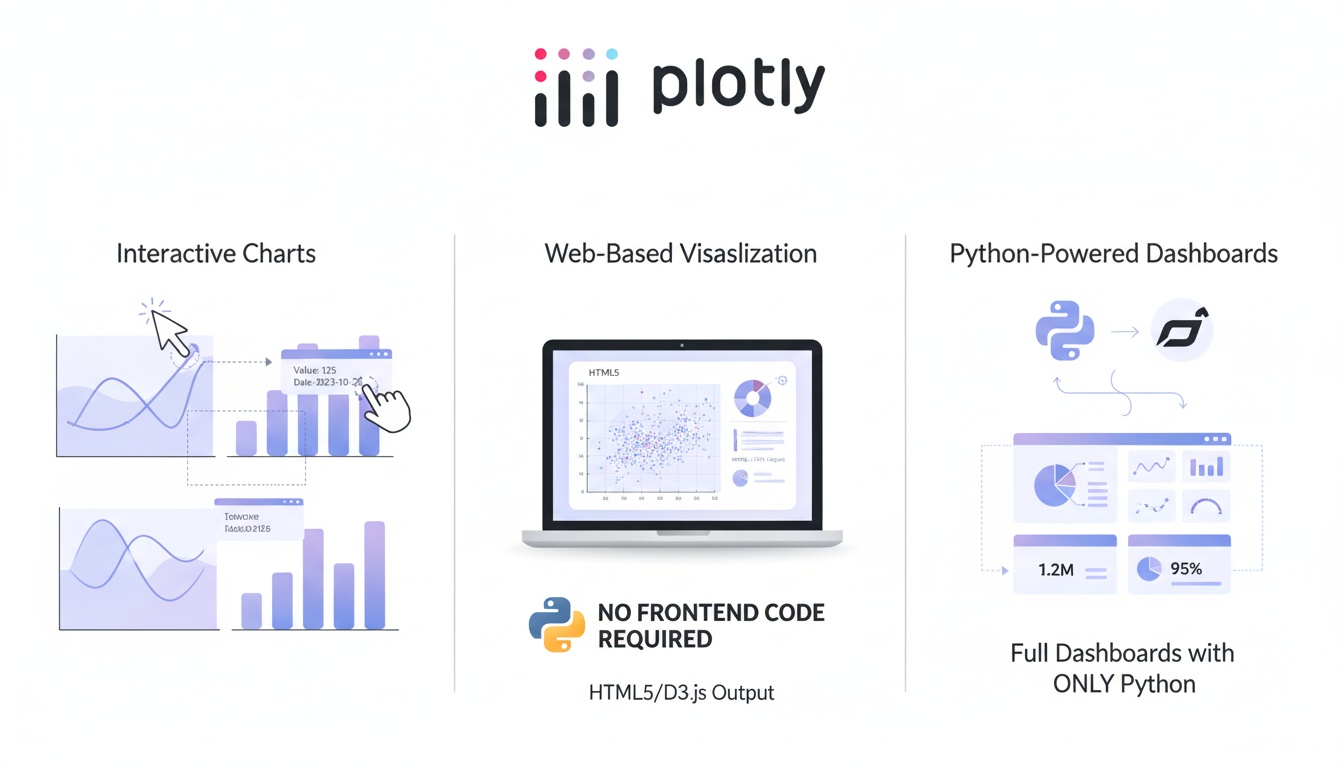
-
대화형 시각화 지원
마우스로 차트를 클릭, 이동, 확대, 축소하고 세부 데이터를 확인할 수 있어 데이터 탐색과 인사이트 도출에 유리하다.
-
웹 기술 기반
HTML, CSS, JavaScript 코드를 작성하지 않아도 Python 코드만으로 웹용 인터랙티브 시각화를 제작할 수 있다.
-
Dash 프레임워크와 강력한 연계
Plotly와 Dash를 함께 사용하면 프론트엔드 기술 없이도 웹 대시보드 및 데이터 분석 서비스를 Python만으로 개발할 수 있다.
-
다양한 차트 유형 제공
Line, Bar, Scatter, Pie와 같은 기본 차트는 물론, 지도(Choropleth), 3D Surface, Treemap, Sankey, Funnel, Network Graph 등 고급 시각화까지 폭넓게 제공한다.
-
연구·산업·교육 전반에서 활용
데이터 분석, 비즈니스 인텔리전스(BI), AI 서비스 개발, 연구 데이터 시각화, 교육용 시각화 등 다양한 영역에서 활발히 사용되고 있다.
참고 자료
장단점 요약
| 장점 | 단점 |
|---|---|
| 대화형 시각화 기본 지원, 마우스 오버·줌·패닝 탐색 용이 | 대규모 데이터·복잡 상호작용 시 렌더링 지연 |
| Python 기반 웹 차트 구현, 보고서·대시보드·발표 활용 | 고급 커스터마이징·콜백 설계 시 학습 곡선 존재 |
| 기본 차트부터 3D·트리맵·지도 등 고급 시각화 제공 | 라이브러리 용량 큼, 브라우저·모바일 로드 부담 |
| Dash 연동으로 웹 대시보드 신속 구축 | 고급 기능 일부 유료, 엔터프라이즈 비용 발생 |
Dash 소개
Dash는 Python 기반의 웹 대시보드 프레임워크로, Plotly를 활용하여 대화형 웹 애플리케이션을 손쉽게 개발할 수 있도록 지원한다. HTML, CSS, JavaScript와 같은 프론트엔드 기술을 몰라도 Python 코드만으로 웹 서비스 형태의 데이터 분석 대시보드를 제작할 수 있다는 것이 큰 장점이다.
Dash는 Plotly 그래프를 중심으로 다양한 UI 컴포넌트(입력창, 버튼, 슬라이더, 드롭다운 등)를 조합하여 상호작용형(Interactive) 데이터 분석 환경을 구축하는 데 특화되어 있다.
Dash의 특징
-
프론트엔드 기술 없이 웹앱 개발 가능
Python 코드만으로 웹 UI 구성, 그래프 출력, 사용자 입력 처리, 반응형 업데이트 등을 구현할 수 있다.
-
상태 변화에 따른 인터랙티브 동작 지원
콜백 함수(Callback)를 활용하여 사용자의 선택, 입력값 변화, 이벤트 발생 등에 따라 화면 요소가 자동으로 갱신된다.
-
Plotly 그래프와 자연스러운 통합
Dash는 Plotly와 동일한 개발사(Plotly Inc.)가 제공하며, Plotly 차트를 대시보드에 삽입하고 상호작용 기능과 연동하기에 최적화되어 있다.
-
데이터 기반 의사결정 환경 구축에 최적화
실시간 데이터 모니터링, BI 대시보드, AI/ML 모델 시각화, 실험 결과 분석용 웹앱 등 다양한 데이터 활용 시나리오에 적용된다.
-
배포 및 확장 용이
로컬 개발 환경에서 시작하여, Flask 기반 서버로 배포하거나 클라우드 환경(AWS, Azure, GCP) 또는 Docker와 연계해 확장할 수 있다.
참고 자료
-
공식 문서: Dash for Python
-
Dash 컴포넌트 모음: Dash Core Components
-
Dash 레이아웃 & 콜백 가이드: Dash Callbacks
-
Dash 예시 앱 갤러리: Plotly Dash App Examples
장단점 요약
| 장점 | 단점 |
|---|---|
| Python만으로 웹 대시보드 구축 가능, 프론트엔드 불필요 | 복잡한 UI/UX 구성 시 코드 길어질 수 있음 |
| 콜백 기반 인터랙션 구현으로 사용자 입력 반응형 웹앱 제작 용이 | 대규모 사용자 트래픽 대응 시 서버 성능 및 확장 고려 필요 |
| Plotly 연동 최적화, 분석·시각화·서비스 통합 개발 가능 | 컴포넌트 디자인 제한적, 고급 커스텀 시 CSS/JS 필요 |
| Flask 기반 구조로 배포, Docker, 클라우드 연계 용이 | Streamlit 대비 초기 학습 진입 장벽 다소 존재 |
Plotly와 Dash 연동
Plotly와 Dash는 각각의 강점을 결합하여 데이터 시각화와 대시보드 개발을 하나의 파이썬 생태계에서 완성할 수 있게 해준다. Plotly가 그래프 시각화를 담당한다면, Dash는 이를 웹 환경에서 인터랙티브하게 활용할 수 있도록 도와주는 역할을 한다.
Plotly → 그래프 그리는 도구 (Visualization Library)
-
Python, R, JavaScript 모두 지원
-
인터랙티브 차트: zoom, pan, hover, tooltip
-
Jupyter Notebook이나 HTML에서 바로 사용 가능
Dash → 웹앱·대시보드 만드는 프레임워크 (Framework)
-
Dash는 웹페이지의 UI 구조(레이아웃, 버튼, 입력창 등)를 만든다.
-
Dash는 Plotly 그래프를 웹 UI에 넣고
-
버튼, 드롭다운, 슬라이더 같은 UI와 연결
-
Dash는 사용자 입력에 따라 Plotly 차트가 자동 업데이트되도록 연동
-
-
Dash는 웹 서버 + 콜백 시스템 제공
두 도구는 동일한 개발사(Plotly社)에서 제공하며 자연스럽게 연계된다.
Plotly와 Dash 연동은 데이터 분석 결과를 시각화 → 공유 → 대시보드화 → 서비스화로 확장하는 과정이 매우 효율적이다.
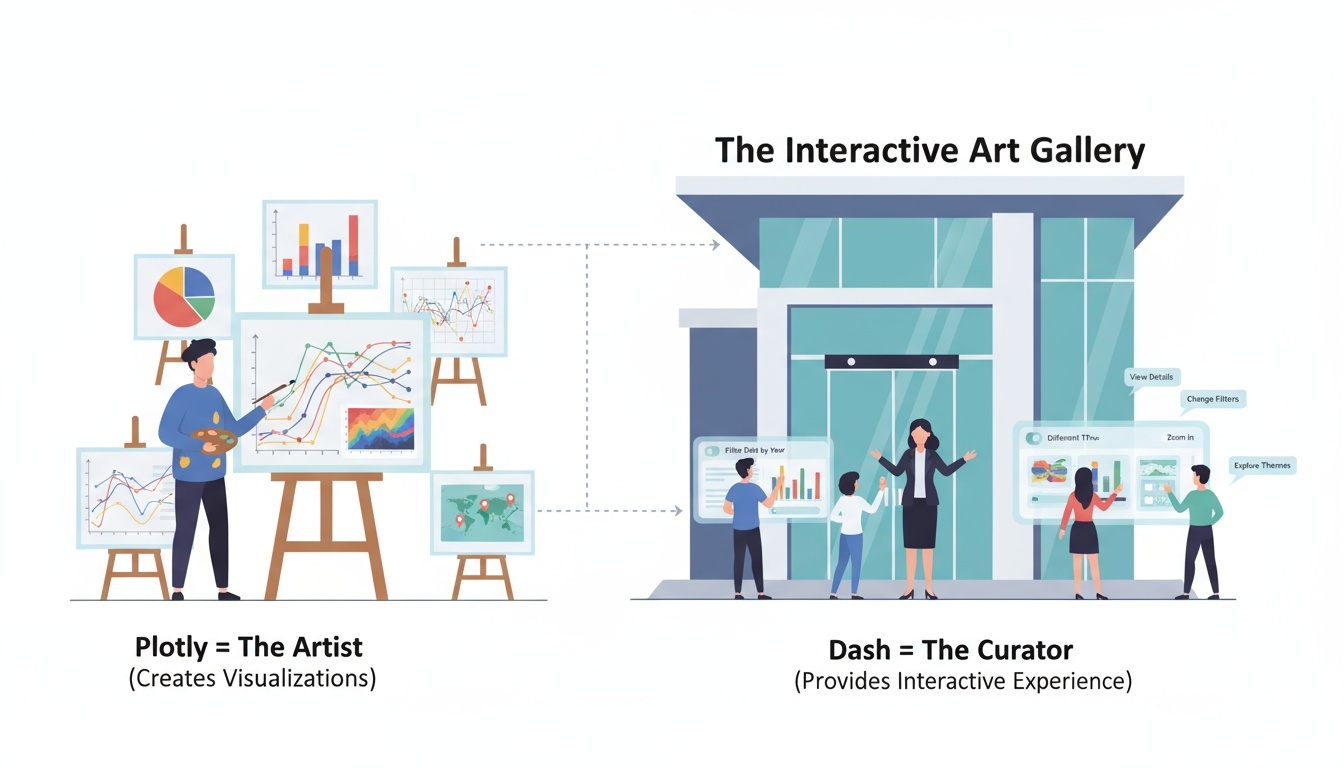
왜 Plotly와 Dash를 함께 사용하는가?
-
시각화와 웹 서비스 개발을 Python 하나로 해결
데이터 분석, 그래프 생성, 웹 대시보드 구축까지 별도의 언어 학습 없이 Python만으로 구현할 수 있다.
-
대화형 시각화 + 사용자 인터랙션 결합
Plotly의 대화형 그래프에 Dash의 입력 컴포넌트(드롭다운, 슬라이더, 버튼 등)를 조합하여 사용자 맞춤형 데이터 탐색 경험을 제공한다.
-
데이터 기반 의사결정 환경 제공
정적인 보고서 대신, 사용자가 직접 데이터를 선택·조작·필터링할 수 있는 상호작용형 분석 환경을 구축할 수 있다.
-
연구·교육·산업 현장에서의 높은 활용성
실험 결과 시각화, AI 모델 성능 비교, BI 모니터링, 실시간 운영 지표 대시보드 등 다양한 영역에 적용 가능하다.
-
배포 및 확장성 용이
Dash는 Flask 기반으로 동작하기 때문에, 로컬 개발 후 서버·Docker·클라우드 환경으로 손쉽게 배포할 수 있다.
요약
Plotly는 “그래프 그리는 도구”, Dash는 “그래프를 웹으로 서비스화하는 도구”라고 이해할 수 있다.
두 도구를 함께 활용하면 데이터 분석 → 시각화 → 대시보드 개발 → 서비스 배포까지 하나의 파이썬 워크플로우로 완성할 수 있다.
대시보드 구현을 위한 다양한 선택
데이터 시각화 및 대시보드 구축은 사용하는 개발 언어 생태계에 따라 적합한 도구가 달라진다.
※ BI(Business Intelligence) 는 기업 내부·외부의 데이터를 수집·정리·시각화하여 의사결정을 지원하는 활동과 그에 필요한 도구 생태계를 의미한다. 리포트 자동화, 권한·공유, 스케줄 배포, 실시간 모니터링 등 조직 운영에 특화된 기능을 제공한다.
Python 생태계
-
데이터 분석 결과를 대화형 웹 대시보드로 빠르게 구현할 수 있다.
콜백 기반 인터랙션과 풍부한 그래프 타입을 제공한다.
-
가장 빠르게 프로토타입과 모델 데모를 만들 수 있다.
위젯 중심이라 학습 곡선이 완만하지만, 복잡 UI 커스터마이징은 제한된다.
-
Panel / Bokeh / HoloViews / Datashader
대용량 시계열·과학 시각화에 강하며, 다운샘플링과 타일 기반 렌더링으로 성능을 확보한다.
세밀한 제어가 가능하지만 학습 난이도는 높은 편이다.
-
백엔드 API와 프론트엔드를 분리해 제품형 대시보드를 구축할 때 적합하다.
인증·권한·캐시·라우팅 등 서비스 요구를 유연하게 반영할 수 있다.
JavaScript / Node.js 생태계
-
React + D3.js / Recharts / Chart.js
정교한 커스텀 인터랙션과 애니메이션, 복잡한 상태관리가 필요한 대규모 프론트엔드에서 강력하다.
프론트 전문 역량이 요구된다.
-
SEO와 라우팅, 서버 컴포넌트를 결합해 웹앱과 대시보드를 동시에 구축할 수 있다.
데이터 패칭과 스트리밍 UI에 유리하다.
-
인터랙티브 차트를 쉽게 만들고, 대용량 렌더링 최적화가 잘 되어 있다.
기업형 대시보드에서도 널리 쓰인다.
-
브라우저 기반 데이터 노트북 플랫폼으로, JS로 데이터를 탐색하고 공유형 보고서를 만들 수 있다.
빠른 실험과 협업에 적합하다.
Java 생태계
-
엔터프라이즈 리포팅 표준 도구로 공공·대기업 SI 프로젝트에서 자주 사용된다.
정형 리포트와 인쇄물 품질에 강하다.
-
Java 기반 서버 사이드 웹 UI 프레임워크와 차트를 결합해 생산성을 높일 수 있다.
순수 Java 스택을 선호하는 조직에 적합하다.
-
Spring Boot + 프론트엔드(React/ECharts/D3)
Java 백엔드와 현대적 프론트엔드를 결합해 대시보드와 운영 서비스를 통합 구축한다.
성숙한 운영·보안 체계를 재사용할 수 있다.
C# (.NET) 생태계
-
기업용 BI 대시보드의 사실상 표준으로, 데이터 연결·권한·공유·자동화에 강하다.
조직 전반 리포팅과 경영 지표 모니터링에 적합하다.
-
Blazor + 차트 라이브러리
C# 풀스택으로 웹 대시보드를 구현할 수 있다.
.NET 조직에서 생산성이 높다.
-
Excel + PowerPivot + Power Query
분석 자동화와 간단한 시각화에서 여전히 강력한 워크플로우를 제공한다.
비개발자 협업 환경에서 유효하다.
R 생태계
-
R 분석 결과를 웹 대시보드로 직접 제공할 수 있다.
통계 기반 연구·학계에서 매우 인기 있다.
-
리포트형 대시보드 제작에 적합하며, 문서·코드·결과를 일관되게 관리할 수 있다.
선택 기준 요약
| 선택 기준 | 추천 기술 스택 | 특징 |
|---|---|---|
| 빠른 프로토타입 개발 | Streamlit, Shiny |
설치 즉시 실행 가능, 코드 몇 줄로 데모/시제품 제작에 최적 |
| 교육 · 연구 · AI 모델 시각화 | Plotly + Dash | Python만으로 대화형 시각화 및 대시보드 제작, 실습/강의용에 적합 |
| 엔터프라이즈 확장성 · 운영성 | Power BI, React + D3.js/ECharts, Spring Boot + Frontend |
보안·권한·배포·대규모 사용자 운영에 최적화 |
| 정교한 커스텀 UI/UX | JavaScript 생태계 (React + D3.js / ECharts) |
자유도와 표현력이 가장 뛰어난 맞춤형 대시보드 구축 가능 |
| 리포트 중심 · 문서화 기반 | Power BI, R Markdown, JasperReports |
정형 리포트, 자동 보고서 생성, 문서 기반 분석 공유에 강점 |
대시보드를 구현하는 방법은 하나가 아니며, 개발 목적, 난이도, 배포 방식, 확장성, 협업 환경에 따라 다양한 접근 방식이 존재한다. 아래는 교육, 연구, 실무 관점에서 활용할 수 있는 대시보드 구현 옵션의 상세 비교이다.
대시보드 구현
드디어 대시보드를 시작합니다 ^^
-
프로젝트 리소스:
-
전체 구현 코드를 제공합니다.
-
가급적이면 스스로 개발한 이후에 확인하기 바랍니다.
-
전체 소스코드 다운로드: plotly_project.zip
-
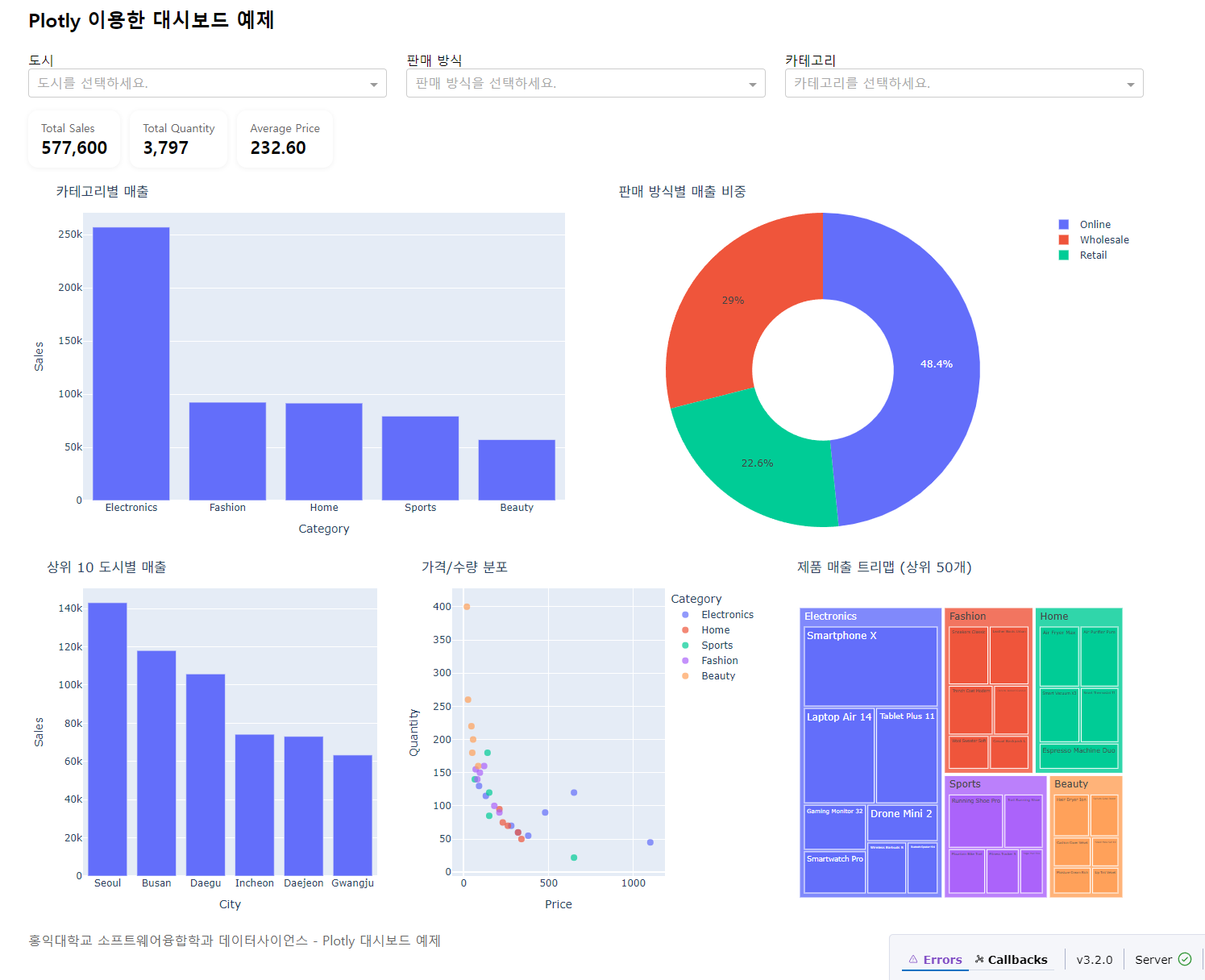
구현할 대시보드 UI는 다음과 같습니다.
실습 환경
-
VS Code또는Jupyter Notebook(본인이 익숙한 IDE 사용) -
Dataset 확보: 바로 다운로드 (click me)
-
필요한 패키지 설치
pip install dash plotly pandas
-
로컬 서버-클라이언트 구조
-
실무환경:
사용자 (users, clients)
\(\to\) 웹서버(
nginx,apache)\(\to\) 미들웨어
-
wsgi (gunicorn, uwsgi,\(\cdots\))-
asgi (uvicorn, fastapi,\(\cdots\))\(\to\) 애플리케이션 (개발 언어에 따라 선택)
- Python Apps:
Flask,Django,FastAPI, \(\cdots\)- Java Apps:
Spring Boot,Jakarta EE,Micronaut, \(\cdots\)- Node.js Apps:
Express,NestJS,Fastify, \(\cdots\)- C++ Apps:
Drogon,Pistache,cpprestsdk, \(\cdots\) -
우리의 실습 환경
-
Nginx, 리버스 프록시, 배포형 구조는 제외하고, 완전 단순하게 로컬 PC에서 바로 실행되는 서버-클라이언트 구조 사용
-
실제로는 Python App (
Flask)에서 제공하는 개발용 웹서버 (dev-webserver) 사용하는 것임- Dash는
Plotly+Flask+React를묶어 만든 웹앱 프레임워크
- Dash는
"웹 브라우저로 접속 (아래 주소 중 하나로 접속)" -> http://127.0.0.1:8050 -> http://localhost:8050 -
-
프로젝트 구조 잡기
권장 폴더 구조
your-workspace/
├─ app.py
├─ requirements.txt
├─ config.py
├─ services/
│ ├─ data_loader.py
│ ├─ figures.py
│ ├─ layout.py
│ └─ callbacks.py
└─ files/
└─ sales_data.csv
패키지 설치
- 직접 패키지 설치
pip install dash plotly pandas
requirements.txt로 설치하는 경우 (requirements.txt)
pip install -r requirements.txt
Dash 엔트리 포인트 모듈 (app.py)
app.py는 Dash 애플리케이션의 시작점(Entry Point) 으로, 대시보드를 실행하기 위한 필수 구성 요소들을 초기화하고 연결하는 역할을 한다. 특히 프로젝트 규모가 커질수록 기능을 여러 모듈로 분리하게 되는데, 이때 app.py는 이러한 모듈들을 조립하고 실행하는 중심 허브가 된다.
위 코드 구조를 기준으로 app.py가 필요한 이유는 다음과 같다.
-
애플리케이션 초기화 및 인스턴스 생성 역할
create_app()함수에서 Dash 인스턴스가 생성되고 앱의 제목 및 설정이 적용된다. 이는 대시보드를 실행하기 위한 기본 토대를 마련하는 단계이며, 애플리케이션의 “시동 버튼”에 해당한다. -
분리된 기능 모듈을 하나로 연결하는 허브 역할
데이터 로딩(
services.data_loader), 레이아웃 구성(services.layout), 콜백 등록(services.callbacks)과 같이 기능은 모듈별로 나누어 구현되지만, 이를 한 곳에서 묶어 하나의 대시보드 애플리케이션으로 동작시키는 곳이app.py이다. -
실행 진입점(Entry Point) 제공
if __name__ == "__main__":블록을 통해 로컬 개발 환경에서 서버를 실행할 수 있다. 이는 대시보드를 테스트하고 검증하는 과정에 필수적이며, 배포 시에도 WSGI/ASGI 서버(gunicorn, uvicorn 등)는app.py내 애플리케이션 객체를 기준으로 서비스 실행을 시작한다.
요약하면, app.py는 Dash 애플리케이션의 시작, 조립, 실행을 담당하는 핵심 모듈이다.
여러 파일로 기능을 분리하여 구조를 깔끔하게 유지하더라도, 그 모든 요소를 결합하여 웹 서비스로 구동시키는 “최종 통합 지점”이 필요하며, 그 역할을 수행하는 것이 바로 app.py이다.
# File: your-workspace/app.py
"""
Dash 애플리케이션의 엔트리 포인트 모듈.
이 모듈은 서버 실행만 담당한다.
실제 비즈니스 로직(데이터 로딩, 레이아웃 구성, 콜백 등록)은 services/ 하위 모듈로 분리되어 있다.
학습 포인트:
- 엔트리 레벨에서는 "조립"만 담당하고, 기능은 모듈로 위임하면 유지보수가 쉬워진다.
"""
from dash import Dash
from config import DATA_PATH, HOST, PORT, DEBUG
from services.data_loader import load_sales_csv
from services.layout import build_layout
from services.callbacks import register_callbacks
def create_app() -> Dash:
"""
Dash 애플리케이션 인스턴스를 생성하고 구성한다.
Returns
-------
Dash
레이아웃과 콜백이 모두 세팅된 Dash 앱 인스턴스.
"""
data_frame = load_sales_csv(DATA_PATH)
app = Dash(__name__)
app.title = "Hongik Dashboard"
# 레이아웃/콜백은 services 모듈로 분리하여 가독성을 높인다.
app.layout = build_layout(data_frame)
register_callbacks(app, data_frame)
return app
if __name__ == "__main__":
# 개발 모드 실행
application = create_app()
application.run(host=HOST, port=PORT, debug=DEBUG)
전역 설정 모듈 (config.py)
config.py는 애플리케이션 전반에서 공통으로 사용되는 설정 정보를 한 곳에 모아 관리하는 모듈이다.
대시보드 개발 과정에서 데이터 경로, 서버 실행 환경, 공통 스타일과 같은 설정 값이 여러 파일에 중복 작성되면 유지보수가 어려워진다.
이를 방지하고 환경 변화에 유연하게 대응하기 위해 전역 설정을 중앙에서 관리하는 것이 중요하다.
-
설정 값 관리의 일원화
데이터 경로, 서버 HOST·PORT 정보와 같이 프로젝트 전체에 영향을 주는 설정을 한 파일에 모아두면 변경이 필요할 때 해당 값만 수정하면 되어 유지보수가 훨씬 쉽다.
-
환경 변화에 대한 유연한 대응
로컬 개발 환경과 실제 운영 환경의 설정 값은 다른 경우가 많다. 예를 들어 개발 시에는
DEBUG=True, 배포 시에는DEBUG=False가 일반적이다.config.py로 설정을 통합하면 환경 전환이 간단해진다. -
코드 가독성 및 역할 분리 개선
설정과 로직이 뒤섞이면 코드가 복잡해지고 흐름 파악이 어려워진다. 설정은
config.py, 기능은 각 서비스 모듈에 분리함으로써 코드 구조가 명확해지고 읽기 쉬워진다. -
스타일 재사용과 UI 일관성 확보
공통 UI 스타일(
APP_STYLES)을 전역으로 관리하면 페이지 전반에 일관된 디자인을 적용할 수 있고, 불필요한 중복 스타일 정의를 줄일 수 있다.
# File: your-workspace/config.py
"""
애플리케이션 전역 설정 모듈.
데이터 경로, 서버 바인딩, 공통 스타일 등을 한 곳에서 관리한다.
학습 포인트:
- 하드코딩을 피하고 설정을 중앙집중화하면 환경 변경에 유연해진다.
"""
from pathlib import Path
# CSV 데이터 경로 (프로젝트 루트 기준)
DATA_PATH: Path = Path("./files/sales_data.csv")
# 서버 설정
HOST: str = "127.0.0.1"
PORT: int = 8050
DEBUG: bool = True
# 간단 공통 스타일 (Dash 인라인 스타일로 재사용)
APP_STYLES: dict[str, dict[str, str]] = {
"container": {
# maxWidth: 전체 레이아웃의 최대 너비(px 단위).
# -> 큰 화면에서 콘텐츠가 너무 넓게 퍼지는 것을 방지.
"maxWidth": "1400px",
# margin: 상하/좌우 여백.
# -> "0 auto": 위/아래 0, 좌우 자동(가운데 정렬)입니다.
"margin": "0 auto",
# fontFamily: 페이지 전반에 적용할 기본 폰트 패밀리
# (우선순위가 앞쪽에 있는 폰트부터 사용).
"fontFamily": "ui-sans-serif, system-ui"
},
"h2": {
# h2 헤딩에 적용할 여백(상하 우/좌).
# -> "16px 8px"은 상하 16px, 좌우 8px
"margin": "16px 8px"
},
"row": {
# display: 행 컨테이너의 레이아웃 방식.
# flex로 열 내부 아이템을 유연하게 배치
"display": "flex",
# gap: 행 내부 항목들 사이의 간격(수평/수직 모두 적용).
"gap": "12px",
# padding: 행 내부의 여백(컨텐츠와 테두리 사이 공간).
"padding": "8px",
# flexWrap: 항목이 한 줄에 다 들어가지 않을 때 줄바꿈 여부.
# -> 'wrap': 꽉 차면 다음 줄로 이동
"flexWrap": "wrap"
},
"card": {
# background: 카드 컴포넌트의 배경색
# (예: 밝은 테마에서는 #fff).
"background": "#fff",
# padding: 카드 내부 콘텐츠와 테두리 간의 여백(상하 좌우).
"padding": "12px 16px",
# borderRadius: 카드 모서리의 둥글기(단위 px).
"borderRadius": "12px",
# boxShadow: 카드의 그림자 효과
# (수평오프셋, 수직오프셋, 블러, 색상).
"boxShadow": "0 1px 6px rgba(0,0,0,0.06)",
},
}
데이터 로딩 및 전처리 모듈 (services/data_loader.py)
data_loader.py는 대시보드에서 사용할 원본 데이터를 불러오고, 시각화에 적합한 형태로 정규화하는 역할을 수행하는 모듈이다.
데이터는 다양한 소스와 형식으로 들어올 수 있으며, 결측값, 잘못된 타입, 파생 지표 미정의 등 분석에 방해가 되는 요소를 포함하고 있는 경우가 많다. 이러한 문제를 한 곳에서 처리하여 깨끗하고 일관된 형태의 데이터를 제공하는 것이 data_loader.py의 핵심 목적이다.
-
데이터 정규화의 중앙 관리
CSV 파일을 불러온 뒤 숫자형 데이터는 수치 변환, 텍스트 데이터는 결측값 보정 등 모든 전처리 과정을 이 모듈에서 수행함으로써 데이터 품질을 일정하게 유지할 수 있다.
-
데이터 품질 확보 및 오류 예방
타입 변환 오류, 결측값, 0으로 나누는 계산 오류 등 시각화와 분석 과정에서 발생할 수 있는 대표적인 문제들을 사전에 처리하여 안정적인 데이터 흐름을 보장한다.
-
파생 지표 생성으로 분석 가치 향상
예를 들어 평균 단가(
AvgPrice_calc)와 같은 파생 변수를 자동으로 만들어줌으로써 추가 분석과 시각화에 사용할 수 있는 의미 있는 정보를 확보할 수 있다. -
데이터 스키마 변경에 대한 유지보수 용이성
데이터 컬럼이 변경되더라도 이 모듈만 수정하면 나머지 애플리케이션 로직은 그대로 유지된다. 데이터 처리 로직을 한 곳에 모아두면 유지보수성과 확장성이 높아진다.
# File: your-workspace/services/data_loader.py
"""
데이터 로딩 및 전처리 모듈.
- CSV를 읽어와 타입을 정규화한다.
- 결측값을 안전하게 보정한다.
- 학습을 위해 평균 단가 같은 파생 지표를 생성한다.
학습 포인트:
- "입력 데이터 정규화"는 시각화/모델링 품질에 직결된다.
- 데이터 스키마가 바뀌면 이 파일만 수정하면 된다.
"""
from pathlib import Path
import pandas as pd
# 프로젝트에서 기대하는 기본 컬럼 세트
NUMERIC_COLUMNS: list[str] = ["Price", "Quantity", "Sales"]
TEXT_COLUMNS: list[str] = ["City", "Channel", "Category", "Product"]
def load_sales_csv(csv_path: Path) -> pd.DataFrame:
"""
sales_data.csv를 로드하고 기본 정규화를 수행한다.
Parameters
----------
csv_path : Path
CSV 파일 경로.
Returns
-------
pandas.DataFrame
정규화된 데이터프레임. 다음을 보장한다:
- 숫자형: Price, Quantity, Sales → 수치 변환 및 결측 0 대체
- 텍스트: City, Channel, Category, Product → 결측 "Unknown"
- 파생: AvgPrice_calc (Sales / Quantity, 0-division 안전 처리)
"""
data_frame = pd.read_csv(csv_path)
# 숫자형 컬럼: 안전한 수치 변환
for column_name in NUMERIC_COLUMNS:
if column_name in data_frame.columns:
data_frame[column_name] = pd.to_numeric(data_frame[column_name], errors="coerce").fillna(0)
# 텍스트 컬럼: 결측은 "Unknown"으로 보정
for column_name in TEXT_COLUMNS:
if column_name in data_frame.columns:
data_frame[column_name] = data_frame[column_name].fillna("Unknown")
# 평균 단가 파생 지표 (0으로 나누는 상황 방지)
if {"Sales", "Quantity"}.issubset(data_frame.columns):
data_frame["AvgPrice_calc"] = (data_frame["Sales"] / data_frame["Quantity"]).replace([float("inf")], 0).fillna(0)
else:
# Sales/Quantity가 없으면 Price를 대체 지표로 활용
data_frame["AvgPrice_calc"] = data_frame.get("Price", 0)
return data_frame
def unique_sorted(data_frame: pd.DataFrame, column_name: str) -> list[str]:
"""
특정 컬럼의 유니크 값 목록을 정렬하여 반환한다.
Parameters
----------
data_frame : pandas.DataFrame
원본 데이터프레임.
column_name : str
고유값을 구할 컬럼명.
Returns
-------
list[str]
정렬된 고유 문자열 목록. 컬럼이 없으면 빈 리스트.
"""
if column_name not in data_frame.columns:
return []
return sorted(data_frame[column_name].dropna().astype(str).unique())
Plotly 시각화 모듈 (services/figures.py)
figures.py는 데이터프레임을 입력받아 Plotly Figure 객체를 생성하는 역할을 전담하는 모듈이다.
시각화 코드를 별도의 모듈로 분리하면 레이아웃, 콜백, 데이터 처리 로직과 혼합되지 않기 때문에
코드의 책임이 명확해지고 유지보수가 쉬워진다. 특히 여러 종류의 차트를 사용하는 대시보드에서는
시각화 로직을 체계적으로 관리하는 것이 중요하다.
-
시각화 함수의 단일 책임(
Single Responsibility) 원칙 적용각 함수는 “하나의 차트” 생성만 담당하도록 설계되어 있다.
함수별 책임은 다음과 같다.
-
fig_category_sales카테고리(
Category)별 매출 합계를 집계하여 막대 차트(Bar Chart) 로 시각화한다. -
fig_channel_share판매 채널(
Channel)별 매출 비중을 도넛 차트(Donut/Pie Chart) 로 표현하여 전체 비중 비교에 적합하다. -
fig_city_topn도시(
City) 기준으로 상위 N개 지역의 매출을 선별하여 Top-N 막대 차트 로 시각화한다. -
fig_price_qty_scatter가격(
Price)과 판매 수량(Quantity)의 상관관계를 산점도(Scatter Plot) 로 보여주며,점 색상은 카테고리, Hover 정보에는 도시·채널·제품 정보를 포함하여 탐색형 분석에 활용할 수 있다.
-
fig_product_treemap카테고리와 제품별 매출 구성 비중을 트리맵(Treemap) 으로 표현하여
어떤 제품이 매출에 기여하는지 계층적으로 파악할 수 있도록 돕는다.
-
-
대화형 시각화 구성 요소의 재사용성 증가
Plotly 기반의 차트 설정(레이아웃, hover, 색상, 마진 등)이 모듈 안에 캡슐화되어 있어 다른 페이지나 대시보드에서도 동일한 시각화 스타일을 그대로 재사용할 수 있다.
-
시각화 품질과 안정성 향상
grouping, sorting, top-N 추출, hover 데이터 설정, infinity 처리 등 차트 품질과 사용자 경험에 영향을 주는 요소를 함수 내부에서 일관적으로 제어할 수 있다. 이를 통해 시각 오류나 데이터 불일치로 인한 해석 오류를 예방할 수 있다.
-
데이터 변화에 대한 확장성 확보
새로운 차트를 추가해야 할 경우, 해당 기능만 별도 함수로 작성해 모듈에 추가하면 된다. 이 방식은 프로젝트 확장 시 파일 구조를 깔끔하게 유지하며 기능 확장을 용이하게 한다.
# File: your-workspace/services/figures.py
"""
Plotly 시각화 모듈.
각 Figure 함수는 "입력 데이터프레임 → plotly Figure"를 생성한다.
학습 포인트:
- 시각화 함수는 "하나의 책임(한 가지 차트)"만 갖도록 분리한다.
"""
import pandas as pd
import plotly.express as px
from plotly.graph_objs import Figure
def fig_category_sales(filtered_frame: pd.DataFrame) -> Figure:
"""
카테고리별 매출 합계를 막대 차트로 시각화한다.
Parameters
----------
filtered_frame : pandas.DataFrame
필터가 적용된 데이터프레임.
Returns
-------
plotly.graph_objs.Figure
카테고리별 Sales 합계 막대 차트.
"""
summary = (
filtered_frame.groupby("Category", as_index=False)["Sales"]
.sum()
.sort_values("Sales", ascending=False)
)
figure = px.bar(summary, x="Category", y="Sales", title="카테고리별 매출")
figure.update_layout(xaxis={"categoryorder": "total descending"}, margin=dict(l=20, r=20, t=40, b=20))
return figure
def fig_channel_share(filtered_frame: pd.DataFrame) -> Figure:
"""
채널별 매출 비중을 도넛 차트로 시각화한다.
Parameters
----------
filtered_frame : pandas.DataFrame
필터가 적용된 데이터프레임.
Returns
-------
plotly.graph_objs.Figure
채널별 Sales 비중 도넛 차트.
"""
summary = (
filtered_frame.groupby("Channel", as_index=False)["Sales"]
.sum()
.sort_values("Sales", ascending=False)
)
figure = px.pie(summary, names="Channel", values="Sales", title="판매 방식별 매출 비중", hole=0.45)
figure.update_layout(margin=dict(l=20, r=20, t=40, b=20))
return figure
def fig_city_topn(filtered_frame: pd.DataFrame, top_n: int = 10) -> Figure:
"""
도시별 상위 매출 Top-N을 막대 차트로 시각화한다.
Parameters
----------
filtered_frame : pandas.DataFrame
필터가 적용된 데이터프레임.
top_n : int, optional
상위 도시 개수, 기본값 10.
Returns
-------
plotly.graph_objs.Figure
Top-N 도시별 Sales 막대 차트.
"""
summary = (
filtered_frame.groupby("City", as_index=False)["Sales"]
.sum()
.sort_values("Sales", ascending=False)
.head(top_n)
)
figure = px.bar(summary, x="City", y="Sales", title=f"상위 {top_n} 도시별 매출")
figure.update_layout(xaxis={"categoryorder": "total descending"}, margin=dict(l=20, r=20, t=40, b=20))
return figure
def fig_price_qty_scatter(filtered_frame: pd.DataFrame) -> Figure:
"""
가격(Price)과 수량(Quantity)의 관계를 산점도로 표현한다.
- 점 색상: Category
- Hover: City, Channel, Product
Parameters
----------
filtered_frame : pandas.DataFrame
필터가 적용된 데이터프레임.
Returns
-------
plotly.graph_objs.Figure
가격-수량 산점도.
"""
figure = px.scatter(
filtered_frame,
x="Price",
y="Quantity",
color="Category" if "Category" in filtered_frame.columns else None,
hover_data=[c for c in ["City", "Channel", "Product"] if c in filtered_frame.columns],
title="가격/수량 분포",
)
figure.update_traces(mode="markers", marker=dict(size=8, opacity=0.7))
figure.update_layout(margin=dict(l=20, r=20, t=40, b=20))
return figure
def fig_product_treemap(filtered_frame: pd.DataFrame, max_items: int = 5) -> Figure:
"""
제품별 매출을 트리맵으로 시각화한다. (상위 max_items로 제한)
Parameters
----------
filtered_frame : pandas.DataFrame
필터가 적용된 데이터프레임.
max_items : int, optional
트리맵에 표시할 (Sales 기준) 상위 아이템 수, 기본값 50.
Returns
-------
plotly.graph_objs.Figure
제품 트리맵.
"""
summary = (
filtered_frame.groupby(["Category", "Product"], as_index=False)["Sales"]
.sum()
.sort_values("Sales", ascending=False)
.head(max_items)
)
# --- 방어적 변환: narwhals-like 객체를 pandas DataFrame으로 변환하고 인덱스 정리 ---
try:
if hasattr(summary, "to_pandas"):
summary = summary.to_pandas()
else:
summary = pd.DataFrame(summary)
except Exception:
summary = pd.DataFrame(summary)
# Sales 컬럼을 숫자로 강제하고 NaN은 0으로 채움
if "Sales" in summary.columns:
summary["Sales"] = pd.to_numeric(summary["Sales"], errors="coerce").fillna(0)
else:
summary["Sales"] = 0
summary = summary.reset_index(drop=True)
# -------------------------------------------------------------------------------
# px.treemap 호출을 안전하게 감싸서 실패시 빈(플레이스홀더) Figure 반환
try:
figure = px.treemap(
summary,
path=["Category", "Product"],
values="Sales",
title=f"제품 매출 트리맵 (상위 {max_items}개)"
)
figure.update_layout(margin=dict(l=20, r=20, t=40, b=20))
except Exception:
import plotly.graph_objects as go
figure = go.Figure().update_layout(title="데이터 오류 (데이터 없음)")
return figure
레이아웃 생성 모듈 (services/layout.py)
layout.py는 대시보드 화면을 구성하는 UI 골격을 정의하는 모듈이다.
데이터 로직이나 콜백 계산 없이, 무엇을 어디에 배치할지만을 선언적으로 표현한다.
이렇게 레이아웃과 로직을 분리하면 협업, 테스트, 확장 모두가 수월해진다.
-
관심사의 분리(Separation of Concerns)
레이아웃은 화면 구성만 담당하고, 데이터 가공·상호작용은 콜백으로 위임한다. 덕분에 UI 변경이 로직에 파급되지 않아 유지보수가 쉬워진다.
-
컴포넌트 식별자(ID) 체계의 중심
dcc.Dropdown(id="f-city" | "f-channel" | "f-category"),dcc.Graph(id="g-..."),html.Div(id="kpi-row")처럼 콜백에서 참조할 입·출력 컴포넌트의 ID를 단일 장소에서 정의한다. 콜백 의존성을 명확하게 하고, 테스트 대상 컴포넌트를 식별하기 쉽게 만든다. -
반응형(Responsive) 레이아웃과 일관된 스타일
APP_STYLES["row"]와 각 카드/그래프의flex·minWidth를 활용해 작은 화면에서는 줄바꿈, 큰 화면에서는 가로 확장을 자연스럽게 처리한다. 전역 스타일을 공유하므로 페이지 전반의 톤앤매너가 일관된다. -
재사용 가능한 UI 패턴 캡슐화
kpi_card(title_text, value_text)처럼 자주 쓰는 컴포넌트를 함수로 감싼다. 코드를 중복하지 않고, 디자인 변경 시 한 곳만 고치면 전체가 반영된다. -
학습 및 테스트 용이성
레이아웃이 독립되어 있으면 시각적 구조를 코드만으로 쉽게 파악할 수 있다. 콜백을 붙이기 전에도 화면 스켈레톤을 띄워 UI 점검과 단위 테스트가 가능하다.
-
확장성과 모듈화
섹션(필터 행, KPI 행, 상단/하단 차트 영역)을 블록 단위로 구획했다. 새로운 그래프나 필터를 추가할 때 해당 블록에만 코드를 보강하면 된다.
코드 구조와 역할 매핑
-
필터 행(Filters Row)
City,Channel,Category드롭다운을 좌→우로 배치한다.unique_sorted()로 옵션을 데이터에서 자동 생성하고, 다중 선택(multi=True)을 지원한다. -
KPI 행(KPI Row)
html.Div(id="kpi-row")만 미리 배치하고 내용은 콜백으로 주입한다. 이렇게 하면 KPI 계산 로직을 레이아웃과 분리할 수 있다. -
상단 차트 행(Top Charts Row)
g-category(카테고리 매출 바 차트),g-channel(채널 비중 도넛) 두 개의 핵심 요약 차트를 나란히 배치한다. 의사결정자가 한눈에 파악해야 할 지표를 상단에 둔다. -
하단 차트 행(Bottom Charts Row)
g-city(도시 Top-N),g-scatter(가격-수량 산점도),g-treemap(제품 트리맵)을 배치한다. 상단 요약 → 하단 탐색의 정보 위계(Information Hierarchy) 를 구현한다. -
푸터(Footer)
교육용 출처와 맥락을 명시해 학습 자료임을 분명히 한다.
# File: your-workspace/services/layout.py
"""
Dash 레이아웃 생성 모듈.
- 필터 드롭다운, KPI 카드, 그래프 영역을 배치한다.
- 레이아웃은 "화면 구성"만 담당하고 데이터 로직은 다루지 않는다.
학습 포인트:
- 레이아웃(UI)과 로직(콜백/계산)을 분리하면 협업과 테스트가 쉬워진다.
"""
from dash import html, dcc
import pandas as pd
from config import APP_STYLES
from services.data_loader import unique_sorted
def kpi_card(title_text: str, value_text: str) -> html.Div:
"""
간단한 KPI 카드 컴포넌트를 생성한다.
Parameters
----------
title_text : str
KPI 제목(예: 'Total Sales').
value_text : str
KPI 값(서식 적용된 문자열).
Returns
-------
dash.html.Div
스타일이 적용된 KPI 카드 컴포넌트.
"""
return html.Div(
[
html.Div(title_text, style={"fontSize": "14px", "color": "#666"}),
html.Div(value_text, style={"fontSize": "22px", "fontWeight": "600"}),
],
style=APP_STYLES["card"],
)
def build_layout(data_frame: pd.DataFrame) -> html.Div:
"""
대시보드 전체 레이아웃을 구성한다.
Parameters
----------
data_frame : pandas.DataFrame
드롭다운 옵션 생성을 위한 원본 데이터프레임.
Returns
-------
dash.html.Div
Dash 애플리케이션의 루트 레이아웃.
"""
cities = unique_sorted(data_frame, "City")
channels = unique_sorted(data_frame, "Channel")
categories = unique_sorted(data_frame, "Category")
return html.Div(
[
html.H2("Plotly 이용한 대시보드 예제", style=APP_STYLES["h2"]),
# Filters Row
html.Div(
[
html.Div(
[
html.Label("도시"),
dcc.Dropdown(
id="f-city",
options=[{"label": city, "value": city} for city in cities],
value=None,
multi=True,
placeholder="도시를 선택하세요.",
),
],
style={"flex": "1", "minWidth": "200px", "marginRight": "12px"},
),
html.Div(
[
html.Label("판매 방식"),
dcc.Dropdown(
id="f-channel",
options=[{"label": channel, "value": channel} for channel in channels],
value=None,
multi=True,
placeholder="판매 방식을 선택하세요.",
),
],
style={"flex": "1", "minWidth": "200px", "marginRight": "12px"},
),
html.Div(
[
html.Label("카테고리"),
dcc.Dropdown(
id="f-category",
options=[{"label": category, "value": category} for category in categories],
value=None,
multi=True,
placeholder="카테고리를 선택하세요.",
),
],
style={"flex": "1", "minWidth": "200px"},
),
],
style=APP_STYLES["row"],
),
# KPI Row (콜백으로 채워짐)
html.Div(id="kpi-row", style=APP_STYLES["row"]),
# Top Charts Row
html.Div(
[
html.Div([dcc.Graph(id="g-category")], style={"flex": "1", "minWidth": "360px"}),
html.Div([dcc.Graph(id="g-channel")], style={"flex": "1", "minWidth": "360px"}),
],
style=APP_STYLES["row"],
),
# Bottom Charts Row
html.Div(
[
html.Div([dcc.Graph(id="g-city")], style={"flex": "1", "minWidth": "360px"}),
html.Div([dcc.Graph(id="g-scatter")], style={"flex": "1", "minWidth": "360px"}),
html.Div([dcc.Graph(id="g-treemap")], style={"flex": "1", "minWidth": "360px"}),
],
style=APP_STYLES["row"],
),
html.Div(
"홍익대학교 소프트웨어융합학과 데이터사이언스 - Plotly 대시보드 예제",
style={"color": "#666", "padding": "8px"},
),
],
style=APP_STYLES["container"],
)
콜백 관리 모듈 (services/callbacks.py)
callbacks.py는 사용자 입력(필터 변경)을 받아 데이터를 갱신하고, KPI와 모든 차트를 업데이트하는 대시보드의 동적 제어 센터다.
레이아웃이 화면의 뼈대를 정의한다면, 콜백은 사용자 상호작용에 반응하는 데이터 흐름과 출력을 담당한다.
이 모듈은 입력 → 순수 계산 → 출력의 흐름을 일관되게 유지하여 테스트가 쉽고 디버깅이 단순하다.
콜백 함수란?
“나중에 특정 시점에 호출되도록 다른 함수에 넘겨주는 함수”를 의미
개발자가 직접 부르는 함수가 아니라, 시스템/프레임워크/이벤트가 호출하는 함수
콜백(Callback)의 핵심
| 특징 | 설명 |
|---|---|
| 지연 실행 (Deferred Execution) |
콜백은 즉시 실행되지 않고, 특정 조건이나 이벤트가 발생했을 때 나중에 실행된다. |
| 함수 전달 (Function as Argument) |
함수 자체를 다른 함수의 인자로 전달하여, 실행 흐름을 위임할 수 있다. |
| 이벤트 기반 처리 (Event-Driven) |
버튼 클릭, 데이터 수신, 작업 완료 등 이벤트가 발생할 때 자동 호출되는 방식과 궁합이 좋다. |
| 제어 흐름 역전 (Inversion of Control) |
언제 실행할지 개발자가 직접 결정하지 않고, 시스템 또는 프레임워크에 제어권을 넘긴다. |
일반 콜백 vs Dash 콜백 비교
| 관점 | 콜백 의미 | 누가 호출하는가? | 주요 목적 |
|---|---|---|---|
| 일반 프로그래밍 콜백 |
나중에 실행될 함수를 등록해두고, 실행 시점을 위임하는 함수 |
시스템, 라이브러리, 이벤트 핸들러 |
코드 재사용, 비동기 처리, 이벤트 처리 |
Plotly + Dash콜백 |
UI 컴포넌트(Input) 변경 시 자동 실행되어, 데이터 계산 후 화면 Output을 갱신하는 함수. 사용자가 분석할 데이터를 변경한 경우에 적용됨 (예: 옵션을 매출액 → 지역으로 항목을 바꾼 경우 등) |
Dash 프레임워크 | 대화형 시각화, 반응형 대시보드 구현 |
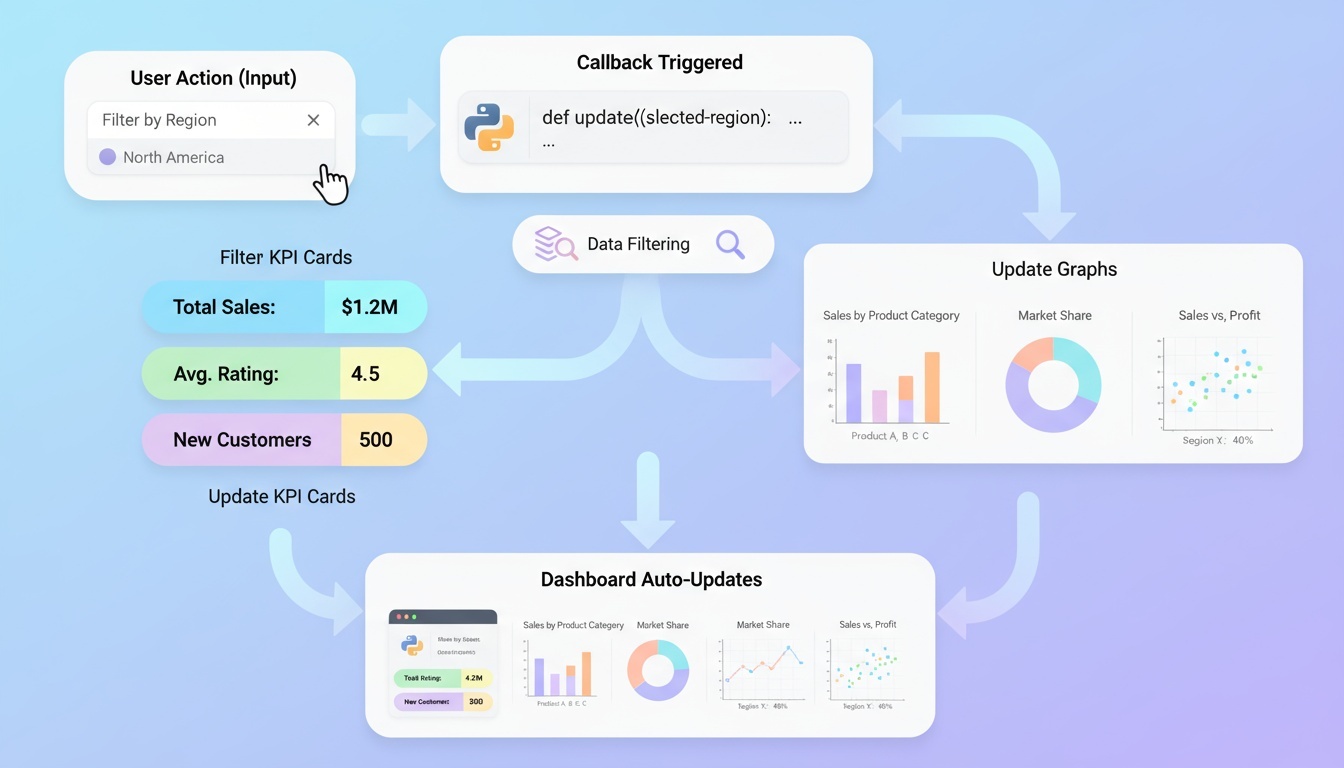
-
입력(Inputs)과 출력(Outputs)의 명시적 연결
@app.callback데코레이터에서 한 번에 KPI 컨테이너와 5개 그래프의 출력을 선언한다. 입력은 3개의 드롭다운(f-city,f-channel,f-category)이며, 콜백은 이 값들에 반응해 전체 대시보드를 갱신한다. -
순수 계산 유지를 위한 보조 함수 분리
apply_filters()와compute_kpis()를 콜백 바깥에 두어 비즈니스 로직을 순수 함수로 관리한다. 이렇게 하면 단위 테스트가 쉬워지고, 다른 곳에서도 재사용 가능하며, 콜백 함수는 얇게 유지된다. -
데이터 필터링의 단일 책임화:
apply_filters()선택된 도시·채널·카테고리에 따라 데이터프레임을 단계적으로 필터링한다. 선택값이 없을 때는 원본을 유지하여 불필요한 연산을 줄이고 예외 케이스를 단순화한다.
-
핵심 KPI 계산의 일관성:
compute_kpis()총매출, 총수량, 평균단가(사전 계산된
AvgPrice_calc평균)를 튜플로 반환한다. 컬럼 유무를 방어적으로 확인하고 기본값을 적용해 안정성을 높인다. -
단일 진입점 콜백:
register_callbacks()애플리케이션 인스턴스와 원본 데이터프레임을 받아 내부에
update_dashboard()콜백을 등록한다. 프레임워크 의존 코드는 여기 묶고, 나머지 로직은 순수 함수로 분리하는 구조가 유지보수를 돕는다. -
대시보드 전체 갱신:
update_dashboard()1) 입력값 수신
2) →
apply_filters()로 데이터 준비3) →
compute_kpis()로 KPI 산출4) → KPI 카드를 보기 좋은 문자열 포맷으로 구성
5) → 각
fig_*함수로 그래프 생성6) → KPI 컴포넌트와 5개 Figure를 정해진 출력 순서대로 반환한다.
# File: your-workspace/services/callbacks.py
"""
Dash 콜백 관리 모듈.
- 필터 변경 시 KPI와 모든 차트를 갱신한다.
- 데이터 필터링과 KPI 계산을 별도 함수로 분리하여 테스트 용이성을 높인다.
학습 포인트:
- 콜백 함수는 '입력 → 순수 계산 → 출력' 흐름으로 작성하면 디버깅이 쉽다.
"""
import pandas as pd
from dash import Dash, Input, Output
from services.layout import kpi_card
from services.figures import (
fig_category_sales,
fig_channel_share,
fig_city_topn,
fig_price_qty_scatter,
fig_product_treemap,
)
def apply_filters(source_frame: pd.DataFrame, selected_cities: list[str] | None,
selected_channels: list[str] | None, selected_categories: list[str] | None) -> pd.DataFrame:
"""
드롭다운에서 선택한 값들로 데이터프레임을 필터링한다.
Parameters
----------
source_frame : pandas.DataFrame
원본 데이터프레임.
selected_cities : list[str] | None
선택된 도시 목록.
selected_channels : list[str] | None
선택된 채널 목록.
selected_categories : list[str] | None
선택된 카테고리 목록.
Returns
-------
pandas.DataFrame
필터가 적용된 새로운 데이터프레임.
"""
filtered_frame = source_frame.copy()
if selected_cities:
filtered_frame = filtered_frame[filtered_frame["City"].isin(selected_cities)]
if selected_channels:
filtered_frame = filtered_frame[filtered_frame["Channel"].isin(selected_channels)]
if selected_categories:
filtered_frame = filtered_frame[filtered_frame["Category"].isin(selected_categories)]
return filtered_frame
def compute_kpis(filtered_frame: pd.DataFrame) -> tuple[float, float, float]:
"""
KPI(총매출, 총수량, 평균단가)를 계산한다.
Parameters
----------
filtered_frame : pandas.DataFrame
필터링된 데이터프레임.
Returns
-------
tuple[float, float, float]
(total_sales, total_quantity, average_price) 의 튜플.
"""
total_sales = float(filtered_frame["Sales"].sum()) if "Sales" in filtered_frame.columns else 0.0
total_quantity = float(filtered_frame["Quantity"].sum()) if "Quantity" in filtered_frame.columns else 0.0
average_price = float(filtered_frame["AvgPrice_calc"].mean()) if "AvgPrice_calc" in filtered_frame.columns else 0.0
return total_sales, total_quantity, average_price
def register_callbacks(app: Dash, source_frame: pd.DataFrame) -> None:
"""
Dash 애플리케이션에 콜백을 등록한다.
Parameters
----------
app : Dash
Dash 애플리케이션 인스턴스.
source_frame : pandas.DataFrame
원본 데이터프레임(필터링의 기준).
"""
@app.callback(
Output("kpi-row", "children"),
Output("g-category", "figure"),
Output("g-channel", "figure"),
Output("g-city", "figure"),
Output("g-scatter", "figure"),
Output("g-treemap", "figure"),
Input("f-city", "value"),
Input("f-channel", "value"),
Input("f-category", "value"),
)
def update_dashboard(selected_cities: list[str] | None,
selected_channels: list[str] | None,
selected_categories: list[str] | None):
"""
드롭다운 선택이 변경될 때마다 전체 대시보드를 갱신한다.
Parameters
----------
selected_cities : list[str] | None
City 드롭다운에서 선택된 값.
selected_channels : list[str] | None
Channel 드롭다운에서 선택된 값.
selected_categories : list[str] | None
Category 드롭다운에서 선택된 값.
Returns
-------
tuple
KPI 카드 리스트와 5개의 그래프 Figure를 순서대로 반환.
"""
filtered_frame = apply_filters(
source_frame,
selected_cities=selected_cities,
selected_channels=selected_channels,
selected_categories=selected_categories,
)
total_sales, total_quantity, average_price = compute_kpis(filtered_frame)
# KPI 카드는 문자열 서식화를 통해 보기 좋게 표현
kpi_components = [
kpi_card("Total Sales", f"{total_sales:,.0f}"),
kpi_card("Total Quantity", f"{total_quantity:,.0f}"),
kpi_card("Average Price", f"{average_price:,.2f}"),
]
return (
kpi_components,
fig_category_sales(filtered_frame),
fig_channel_share(filtered_frame),
fig_city_topn(filtered_frame, top_n=10),
fig_price_qty_scatter(filtered_frame),
fig_product_treemap(filtered_frame, max_items=50),
)
서버 실행 및 접속
# 서버 실행
python app.py
# 브라우저 접속
http://127.0.0.1:8050
http://localhost:8050
Home Works
-
Step 1.
Kaggle데이터셋 다운로드 및 정제-
Kaggle의 Superstore Sales Dataset (Sales by Category & Region)을 활용한다.
-
직접 다운로드: super_store_sales.csv
-
원본 데이터를 정제하여 다음 핵심 컬럼을 남기고
data/폴더에 CSV로 저장한다.-
차원(필터/축):
Order Date(연-월),Region,Category -
측정값:
Sales,Profit,Quantity
-
-
-
Step 2.
Plotly시각화 구현-
선택한 데이터셋을 활용해 Plotly (
Dash또는Plotly Express) 기반 대시보드를 구현한다.co -
최소 3종 이상의 시각화를 포함하되, 각 차트가 전달하는 메시지를 명확히 기술한다. (추세/분포/구성/상관 등)
-
필터 또는 사용자 상호작용(
hover,selection등)을 활용하여 데이터 탐색 기능을 제공한다.
-
-
Step 3. 결과 정리 및 제출
-
완성된 대시보드 화면을 캡처하여 PDF 1페이지 내외로 정리하고, 주요 인사이트를 5문장 내외로 요약한다.
-
프로젝트 전체를 압축(
.zip)하고, 실행 방법(환경 설치, 실행 명령)을README.md에 기재하여 제출한다.
-
-
솔루션을 제공합니다. 가급적이면 솔루션 없이 구현해 볼 것을 추천합니다.
- 솔루션 다운로드: homeworks_resources.zip