11. Big Data Processing
본 강의에서는 빅데이터 처리의 필요성과 Hadoop, Spark의 기본 개념을 이해하고 Spark를 이용한 간단한 실습을 진행한다.
- 강의자료 다운로드: click me
학습 목표
-
빅데이터가 왜 필요해졌는지 설명할 수 있다.
-
Hadoop의 등장 배경 및 핵심 구성요소를 설명할 수 있다.
-
Spark가 Hadoop 이후 중요한 이유를 이해한다.
-
Spark SQL을 사용하여 간단한 분석을 수행할 수 있다.
빅데이터 처리 배경
빅데이터의 역사와 발전, 그리고 중요성
빅데이터라는 개념은 2000년대 중반부터 본격적으로 언급되기 시작했으며, 데이터 생성량이 기하급수적으로 증가하면서 산업 전반에서 핵심 기술로 자리 잡았다. 초기에는 기업 내부 시스템(ERP, CRM 등)에서 발생하는 정형 데이터 중심의 관리가 이루어졌으나, 2010년 전후를 기점으로 인터넷과 모바일 생태계가 급성장하면서 데이터 환경은 급격히 변화하였다.
2007년 이후 스마트폰 보급 확대와 SNS(페이스북, 트위터, 인스타그램)의 폭발적 성장, 웹 서비스의 대중화는 사용자가 생성하는 데이터(User-Generated Content)의 양을 급격히 증가시켰다. 이와 더불어 IoT(사물인터넷) 센서의 등장, CCTV 영상, GPS 로그, 음성·이미지·영상 데이터 등 다양한 형태의 데이터가 생산되면서 기존 RDBMS 중심의 처리 방식만으로는 데이터의 규모, 속도, 다양성을 감당하기 어려워졌다. 이러한 환경 변화는 분산 시스템 기반의 기술 발전을 이끌었고, Google의 논문을 바탕으로 개발된 오픈소스 프레임워크인 Hadoop이 등장하여 빅데이터 처리 생태계의 기반이 마련되었다.
빅데이터의 핵심 가치는 단순히 데이터가 많다는 데 있지 않다. 데이터를 효과적으로 수집·저장·처리하고 분석하여 의미 있는 정보를 도출하는 과정이 중요하며, 이를 통해 조직은 직관이나 경험이 아닌 데이터에 근거한 의사결정(Data-Driven Decision Making) 을 수행할 수 있게 되었다. 예를 들어, 넷플릭스와 유튜브의 콘텐츠 추천 시스템, 아마존의 상품 추천, 구글 검색 랭킹, 금융기관의 이상 거래 탐지, 제조 공정의 품질 예측, 의료 분야의 진단 보조 등 다양한 산업에서 빅데이터 분석은 경쟁력 확보 요소가 되었다.
최근 빅데이터는 AI 기술과 결합하며 활용 범위가 더욱 확장되고 있다. 초기에는 단순 통계 기반 분석이 주류였으나, 현재는 머신러닝과 딥러닝 기술이 적용되면서 데이터 분석의 정확도와 자동화 수준이 크게 향상되었다. 특히, 실시간 데이터 처리 기술의 발전과 함께 데이터 기반 의사결정 시스템은 실시간 모니터링, 예측 분석, 자동 제어 및 최적화 단계로 진화하고 있다. 앞으로 빅데이터는 단순 분석을 넘어, 지능형 의사결정, 자율형 시스템, 초개인화 서비스, 디지털 트윈 기반 산업 혁신 등 데이터 융합 지능화 시대로 발전할 것으로 예상된다.
이처럼 빅데이터는 더 이상 선택이 아닌 필수 역량이며, 데이터 분석과 AI를 활용할 수 있는 기업과 개인만이 미래 경쟁력을 갖출 수 있다.
빅데이터와 AI의 상호 발전 관계
빅데이터와 인공지능(특히 머신러닝)은 서로를 성장시키는 상호 보완적 관계에 있다. 머신러닝 모델이 높은 성능을 발휘하기 위해서는 대규모의 양질의 데이터가 필요하며, 반대로 방대한 데이터를 효과적으로 분석하고 의미를 도출하는 가장 강력한 도구가 머신러닝이기 때문이다. 즉, 빅데이터는 AI의 학습 재료가 되고, AI는 빅데이터의 가치를 극대화하는 역할을 한다.
초기 데이터 분석은 통계 기법 중심이었으나, 데이터의 양과 종류가 폭발적으로 증가하면서 기존 방식으로는 패턴 분석이나 예측 모델링에 한계가 있었다. 이를 해결한 것이 머신러닝이며, 대규모 데이터를 처리·학습할 수 있는 기술이 발전하면서 AI가 빠르게 성장하기 시작했다. 특히, 딥러닝 모델의 등장 이후 데이터가 많을수록 모델 성능이 향상되는 특성이 확인되면서, 기업과 기관은 더 많은 데이터를 확보·저장·관리하려는 방향으로 전략이 이동하였다.
최근에는 빅데이터 기술(Hadoop, Spark, 데이터 파이프라인, 클라우드 스토리지)과 AI 기술이 결합된 형태가 일반화되었다. 데이터 수집, 저장, 전처리, 모델 학습, 예측, 피드백까지 이어지는 데이터 기반 AI 사이클(Data-AI Cycle) 이 구축되면서, AI는 단순 분석을 넘어 자동화와 지능화의 핵심 기술로 자리 잡고 있다. 앞으로도 빅데이터는 AI 발전에 필수적인 연료 역할을 하며, AI는 빅데이터 활용의 지능화를 촉진하는 방향으로 함께 진화해 나갈 것이다.
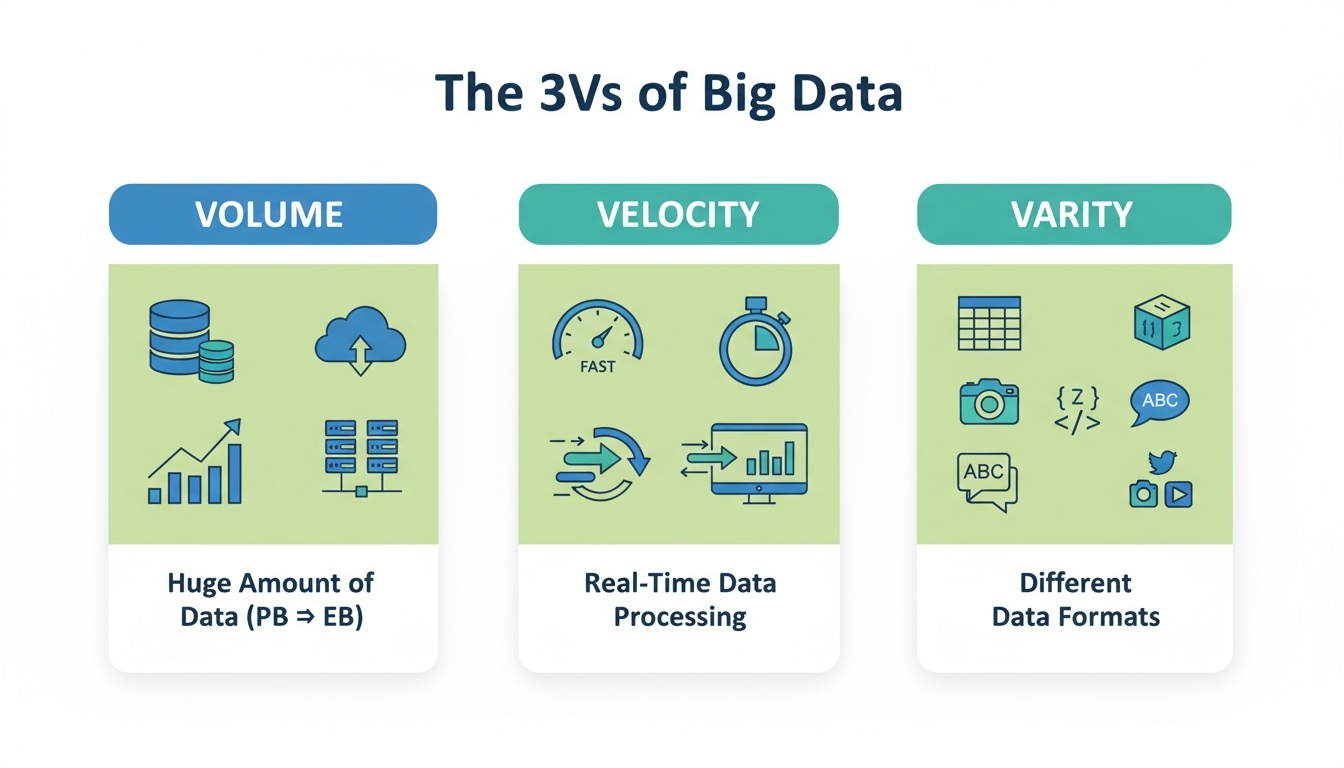
3V of Big Data
빅데이터는 기존 데이터 처리 방식으로는 감당하기 어려운 특성을 지닌 데이터 환경을 의미한다.
이를 설명하기 위해 3V 개념에서 확장된 3V 모델이 널리 사용되며, 아래 세 가지 특성을 통해 빅데이터의 본질을 이해할 수 있다.
-
Volume(데이터 양)데이터의 규모는 과거와 비교할 수 없을 만큼 폭발적으로 증가하고 있다.
기업과 기관은 이제 페타바이트(PB), 엑사바이트(EB) 단위의 데이터를 다루는 시대에 들어섰다.
예시
-
유튜브에는 매분 수백 시간 이상의 영상이 업로드된다.
-
삼성/TSMC 반도체 공정 라인에서 수집되는 센서 데이터는 하루 수 TB를 넘는다.
-
-
Velocity(데이터 생성 및 처리 속도)데이터는 매우 빠른 속도로 생성되고, 처리 또한 실시간에 가깝게 이루어져야 한다.
저장 후 분석하는 배치(Batch) 방식만으로는 한계가 있어 실시간(Real-Time) 처리 기술의 중요성이 커지고 있다.
예시
-
금융권의 이상 거래 탐지 시스템은 거래 발생 즉시 분석하고 승인 여부를 판단해야 한다.
-
자율주행차는 센서 데이터를 실시간 분석하여 주변 상황을 즉각적으로 판단해야 한다.
-
-
Variety(데이터 형태의 다양성)데이터는 정형 데이터뿐 아니라 반정형, 비정형 데이터 등 다양한 형태로 존재한다.
이질적인 데이터들을 통합하여 처리할 수 있는 기술이 필요하다.
예시
-
카카오톡 대화 내용(텍스트), 사진·영상 파일, 위치 정보(GPS)는 서로 형태가 다른 데이터이다.
-
웹 서버 로그, 소셜미디어 댓글, IoT 온습도 센서 데이터는 모두 분석 대상이지만 형식이 다르다.
-
전통 RDBMS의 한계와 Hadoop 등장 배경
전통적인 RDBMS(Relational Database Management System)는 오랫동안 기업 데이터 관리의 핵심 기술로 사용되어 왔다. 데이터의 정합성 유지, 트랜잭션 관리(ACID), SQL을 이용한 편리한 질의 처리 등 강력한 기능을 제공하며 현재도 중요한 역할을 담당하고 있다. 하지만 데이터 환경이 급격히 변화하면서 기존 RDBMS 중심의 구조만으로는 대규모 데이터를 처리하는 데 한계가 발생하였다.
-
RDBMS 소개
RDBMS는 정형 데이터를 표 형태로 저장하고, SQL 기반으로 데이터를 처리하는 전통적인 데이터베이스 관리 시스템이다.
대표적인 예로 Oracle, MySQL, PostgreSQL, MS-SQL 등이 있으며, 금융, 공공, 제조, 의료 등 다양한 산업 분야에서 사용되어 왔다.
-
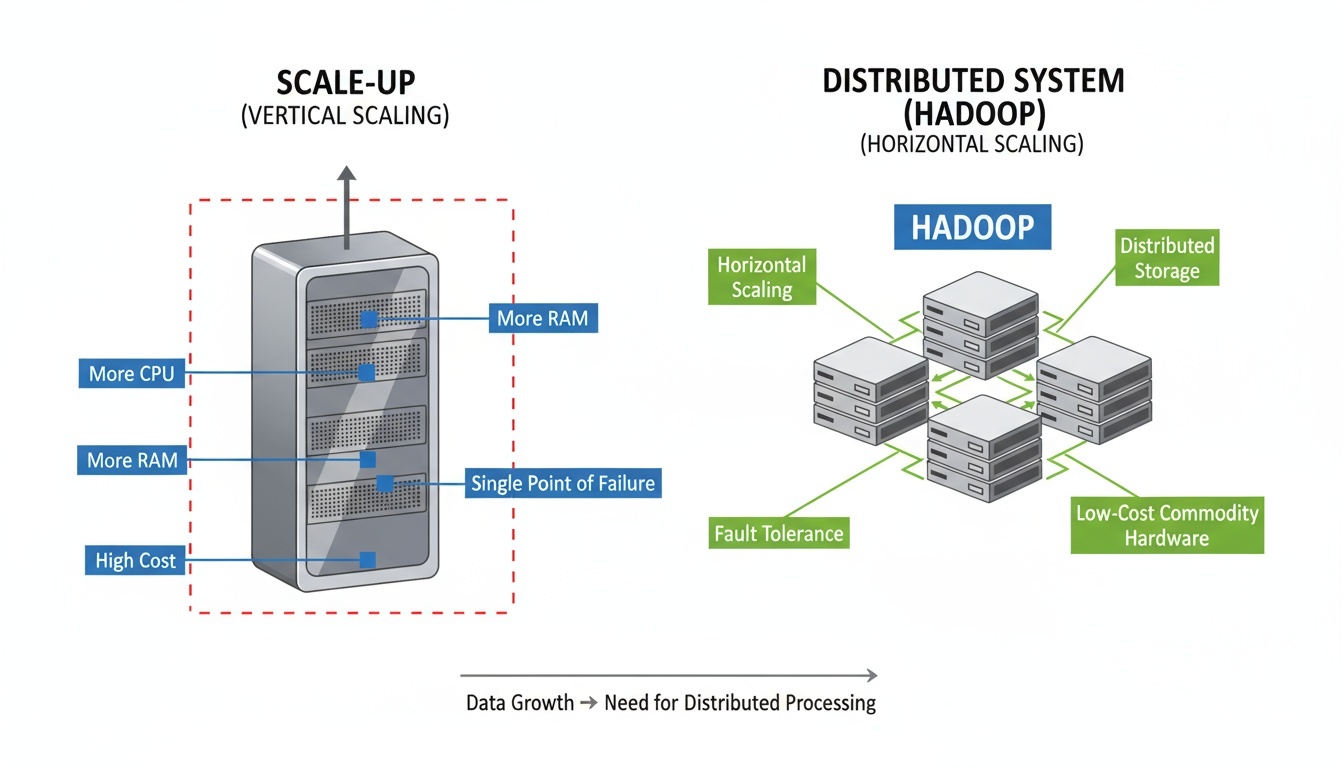
Scale-Up 방식의 한계
기존 RDBMS는 서버의 성능(CPU, 메모리, 저장장치)을 수직적으로 확장하는 Scale-Up 방식에 의존한다.
하지만 일정 수준 이상부터는 서버 성능 증가 대비 비용이 급격히 높아지고, 단일 장비 장애 시 시스템 전체가 영향을 받는 문제가 발생한다.
즉, “좋은 서버로 바꾸는 방식”만으로는 폭발적으로 증가하는 데이터 요구를 감당하기 어렵다.
-
분산 저장 및 분산 처리 필요
데이터가 폭발적으로 증가하고, 실시간 처리 요구가 커지면서 여러 대의 서버에 데이터를 저장하고 동시에 처리할 수 있는 분산 시스템이 필요해졌다.
이러한 요구를 해결하기 위해 구글은 GFS(Google File System)과 MapReduce 모델을 제안했고, 이를 기반으로 오픈소스 프로젝트인 Hadoop이 탄생하게 되었다.
Hadoop은 저렴한 서버 여러 대를 묶어 하나의 시스템처럼 동작시켜, 대규모 데이터를 안정적으로 저장하고 처리할 수 있도록 설계되었다.
SQL Basics for Big Data
빅데이터 환경에서도 SQL은 여전히 가장 널리 사용되는 데이터 처리 언어이다. 데이터 엔지니어, 데이터 과학자, 분석가 모두가 공통적으로 사용할 수 있는 표준 언어이며, NoSQL, Hadoop, Spark 환경에서도 SQL 기반 처리 방식이 확장되고 있다.
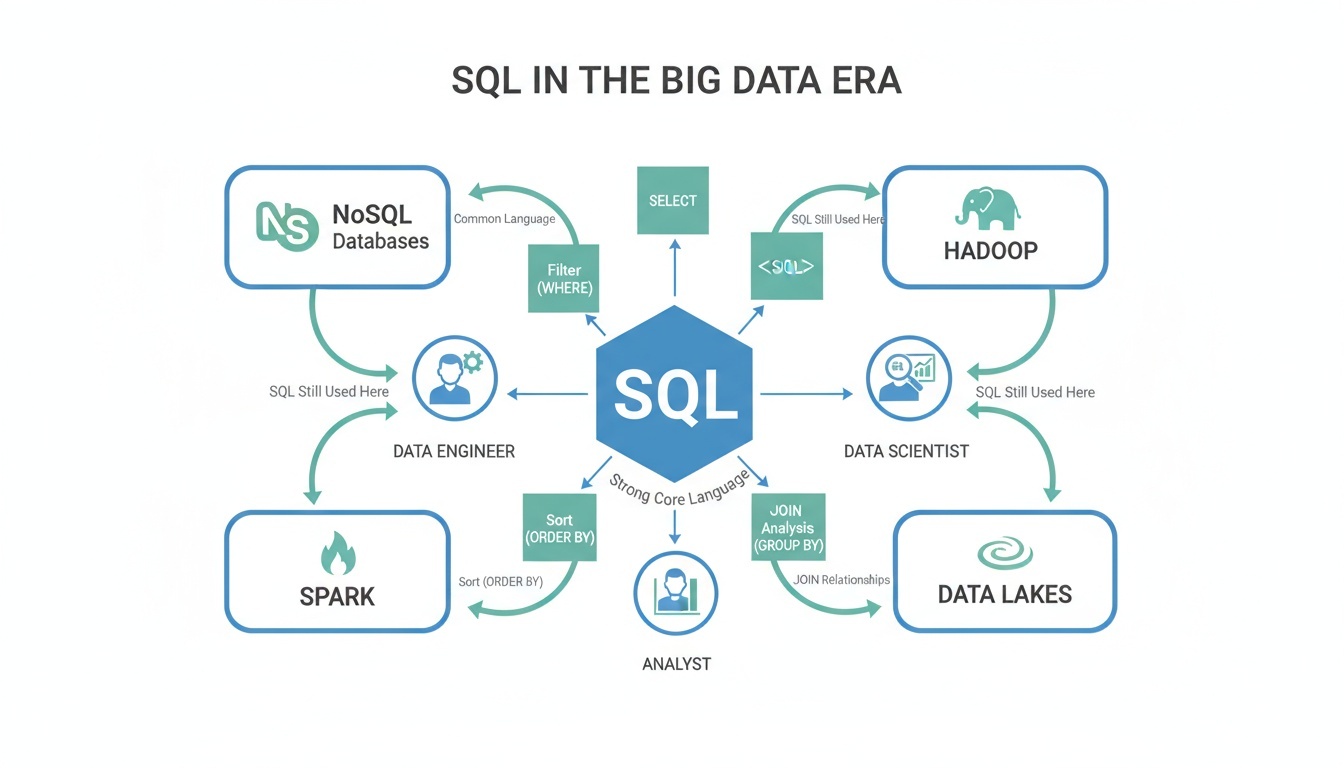
SQL은 데이터를 조회(SELECT), 조건 필터링, 정렬, 그룹 분석, 조인 등 다양한 기능을 제공한다.
다음 코드는 기초적인 SQL 문법 예시이다.
데이터 테이블: users
| name | age | city |
|---|---|---|
| Tom | 25 | Seoul |
| Alice | 32 | Busan |
| David | 41 | Incheon |
| Hannah | 30 | Daegu |
1. 데이터 조회 (SELECT)
-- users 테이블에서 name과 age 컬럼을 조회
SELECT name, age
FROM users;
실행 결과
| name | age |
|--------|-----|
| Tom | 25 |
| Alice | 32 |
| David | 41 |
| Hannah | 30 |
2. 조건 조회 (WHERE)
-- 나이가 30 이상인 사용자만 조회
SELECT name, age
FROM users
WHERE age >= 30;
실행 결과
| name | age |
|--------|-----|
| Alice | 32 |
| David | 41 |
| Hannah | 30 |
3. 정렬 (ORDER BY)
-- 나이를 기준으로 내림차순(DESC) 정렬
SELECT name, age
FROM users
ORDER BY age DESC;
실행 결과
| name | age |
|--------|-----|
| David | 41 |
| Alice | 32 |
| Hannah | 30 |
| Tom | 25 |
4. 그룹 분석 (GROUP BY + 집계함수)
-
데이터 테이블:
employeesemployee_name department salary Tom HR 4200 Alice HR 4600 David Sales 5100 Hannah Sales 4900 Chris Sales 5300 Emily IT 6000 John IT 6200 Sarah IT 5800
-- 부서별 평균 급여를 계산하여 출력
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department;
실행 결과
| department | avg_salary |
|------------|------------|
| HR | 4400 |
| Sales | 5100 |
| IT | 6000 |
5. 테이블 조인 (JOIN)
-
데이터 테이블:
customerscustomer_id customer_name city 1 Tom Seoul 2 Alice Busan 3 David Incheon 4 Hannah Daegu -
데이터 테이블:
ordersorder_id customer_id product amount 101 1 Keyboard 50 102 1 Monitor 200 103 2 Mouse 25 104 3 Laptop 1200 105 3 Headset 80 106 4 Webcam 70
-- 주문 테이블과 고객 테이블을 customer_id 기준으로 조인하여
-- 주문 번호, 고객 이름, 주문 금액을 함께 조회
SELECT o.order_id, c.customer_name, o.amount
FROM orders AS o
JOIN customers AS c
ON o.customer_id = c.customer_id;
실행 결과
| order_id | customer_name | amount |
|----------|----------------|--------|
| 101 | Tom | 50 |
| 102 | Tom | 200 |
| 103 | Alice | 25 |
| 104 | David | 1200 |
| 105 | David | 80 |
| 106 | Hannah | 70 |
6. 데이터 제한 (LIMIT)
-
데이터 테이블:
productsproduct_id product_name category price 1 Keyboard Electronics 50 2 Mouse Electronics 25 3 Monitor Electronics 200 4 Laptop Electronics 1200 5 Headset Electronics 80 6 Webcam Electronics 70 7 Desk Furniture 150 8 Chair Furniture 130 9 Notebook Stationery 5 10 Pencil Set Stationery 3 11 Coffee Mug Kitchen 15 12 Water Bottle Kitchen 18
-- products 테이블에서 가격이 가장 높은 상품 3개 조회
SELECT product_id, product_name, category, price
FROM products
ORDER BY price DESC
LIMIT 3;
실행 결과
| product_id | product_name | category | price |
|------------|--------------|--------------|-------|
| 4 | Laptop | Electronics | 1200 |
| 7 | Desk | Furniture | 150 |
| 8 | Chair | Furniture | 130 |
Traditional SQL vs Big Data SQL
-
왜 SQL은 여전히 중요한가?
SQL은 배우기 쉽고, 선언적 언어로서 복잡한 데이터 처리 과정을 단순한 질의 형태로 표현할 수 있다.
또한 다양한 데이터베이스와 빅데이터 엔진이 SQL 인터페이스를 채택하면서, SQL은 데이터 분석의 범용 언어로 자리 잡았다.
-
전통 SQL과 빅데이터 SQL의 차이
전통 SQL은 하나의 서버(단일 머신)에서 동작하는 데이터베이스(RDBMS)를 기반으로 한다. 이 방식은 데이터 크기가 상대적으로 작고, 정해진 스키마(표 형태의 정형 데이터)를 가진 데이터를 처리하는 데 매우 효율적이다. 예를 들어, 회사 내부 고객 DB나 쇼핑몰 회원/주문 데이터처럼 테이블 형태로 저장된 데이터를 빠르게 조회하고 관리하는 데 적합하다.
그러나 데이터가 기하급수적으로 증가하고, 로그, 이미지, 센서, 텍스트 등 다양한 형태의 데이터가 등장하면서 단일 서버 방식은 한계에 부딪혔다. 서버를 업그레이드(Scale-Up)해도 처리 가능한 데이터량과 성능 향상에는 한계가 있으며, 비용 대비 효율이 떨어지게 된다.
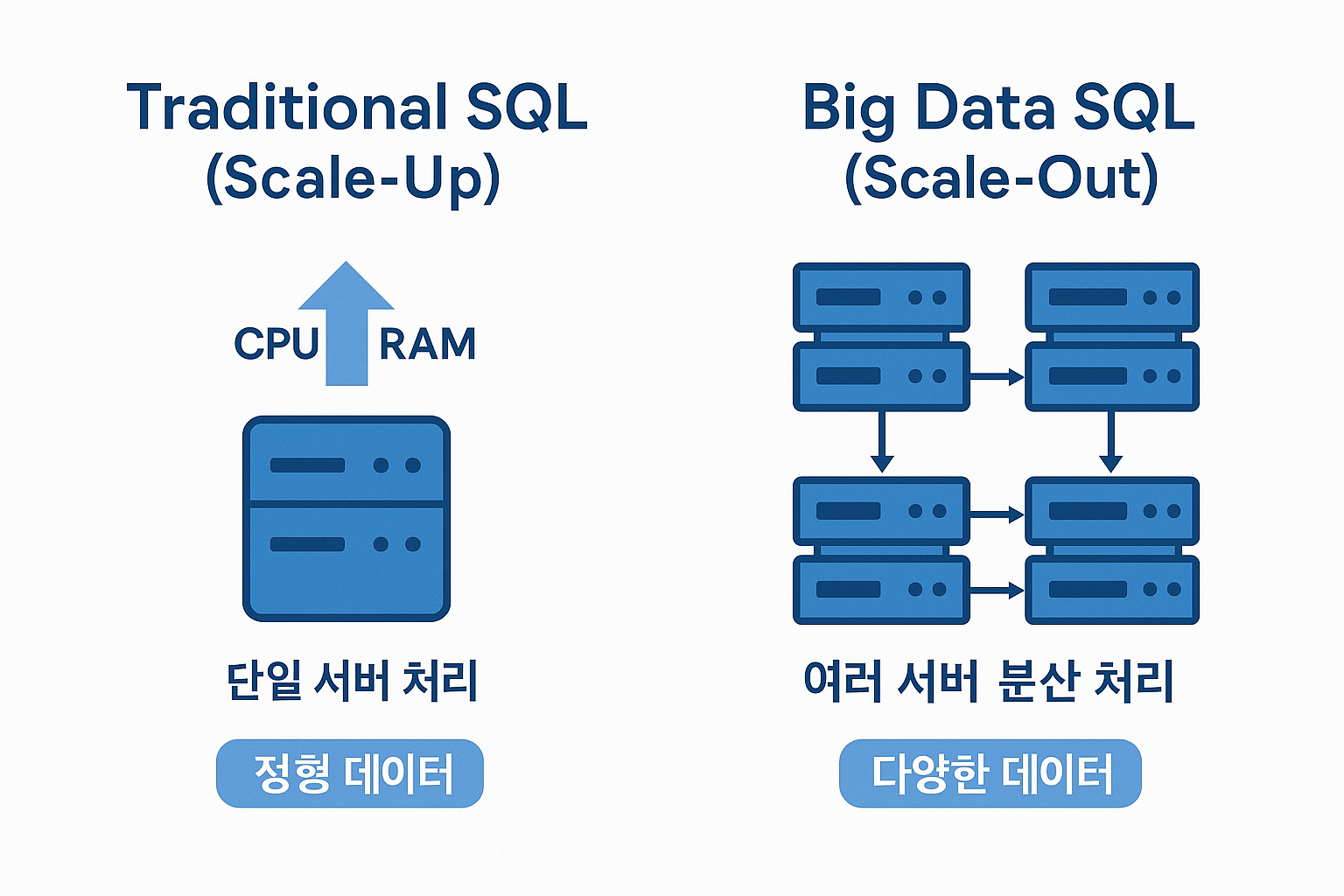
이러한 한계를 해결하기 위해 등장한 개념이 빅데이터 SQL이다. 빅데이터 SQL 엔진은 데이터를 여러 서버에 분산 저장하고, 작업을 병렬로 나누어 동시에 처리하는 Scale-Out 방식을 사용한다. 즉, 1대의 강력한 서버보다, 일반 성능의 서버 10대가 동시에 처리하도록 설계된 구조이다.
또한 스키마가 없는 텍스트 로그, JSON, IoT 센서 데이터 같은 반정형/비정형 데이터까지 SQL로 처리할 수 있도록 기능이 확장되었다. 대표적인 기술로는 Hive, Presto, Trino, Spark SQL 등이 있으며, Hadoop/HDFS 또는 클라우드 기반 데이터 레이크 위에서 작동한다.
-
요약 정리
항목 전통 SQL 빅데이터 SQL 처리 방식 단일 서버 처리 다수 서버 분산 처리 확장 방식 Scale-Up (서버 성능 증가) Scale-Out (서버 수 증가) 데이터 형태 정형 데이터 중심 정형 + 반정형 + 비정형 대표 기술 Oracle, MySQL, PostgreSQL Hive, Presto, Trino, Spark 데이터 저장 위치 로컬 DB 서버 HDFS, Data Lake, Cloud -
Lakehouse 시대의 SQL
최근에는 데이터 레이크와 웨어하우스를 결합한 Lakehouse 아키텍처가 확산되고 있다.
-
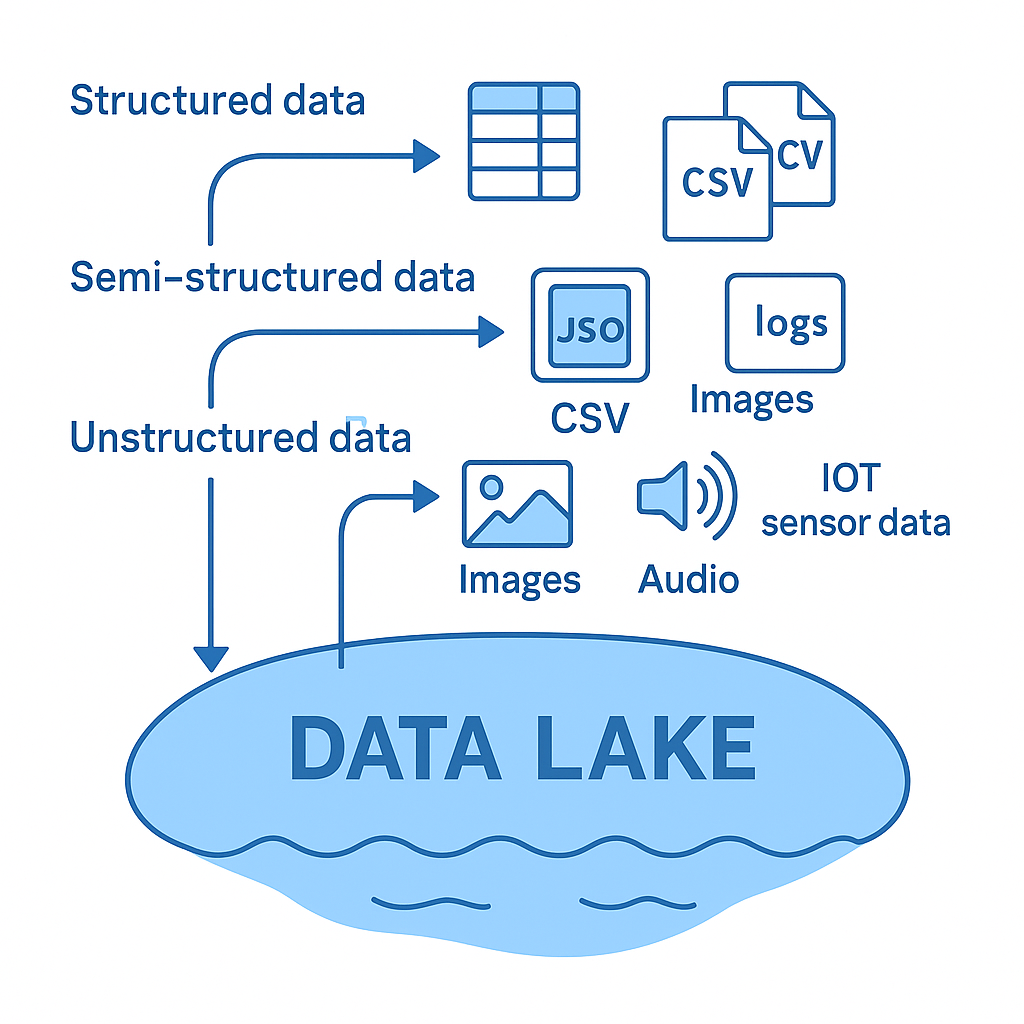
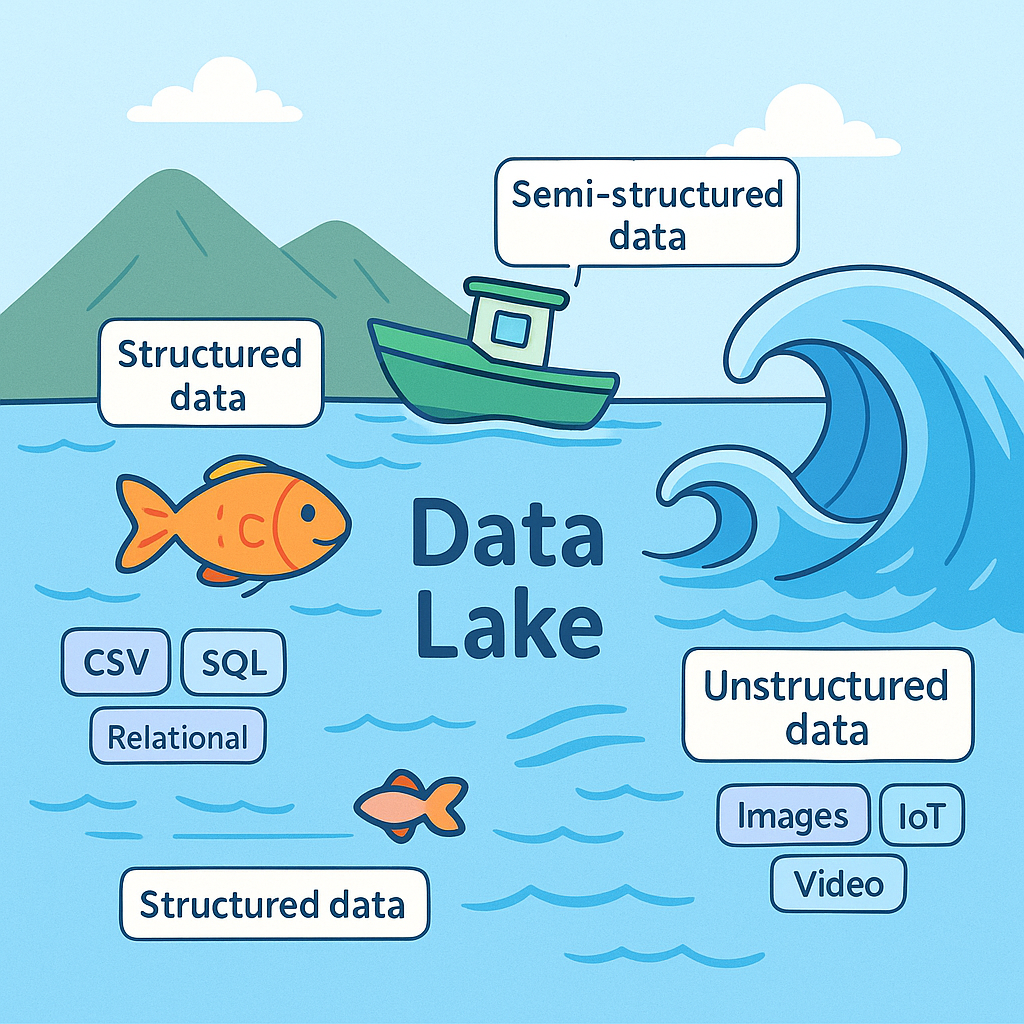
Data Lake
데이터 레이크(Data Lake)는 기업이나 조직이 수집하는 다양한 형태의 데이터를 가공하지 않은 원천(raw) 상태 그대로 저장할 수 있는 대규모 저장소이다.
정형 데이터뿐 아니라, 반정형·비정형 데이터를 모두 담아둘 수 있으며, 필요할 때 꺼내서 처리·분석하는 방식으로 활용된다.
데이터 레이크는 말 그대로 “큰 호수”에 비유할 수 있다. 여러 하천에서 물이 흘러 들어오듯, 여러 데이터 소스의 데이터가 하나의 레이크에 모여 저장된다.
-
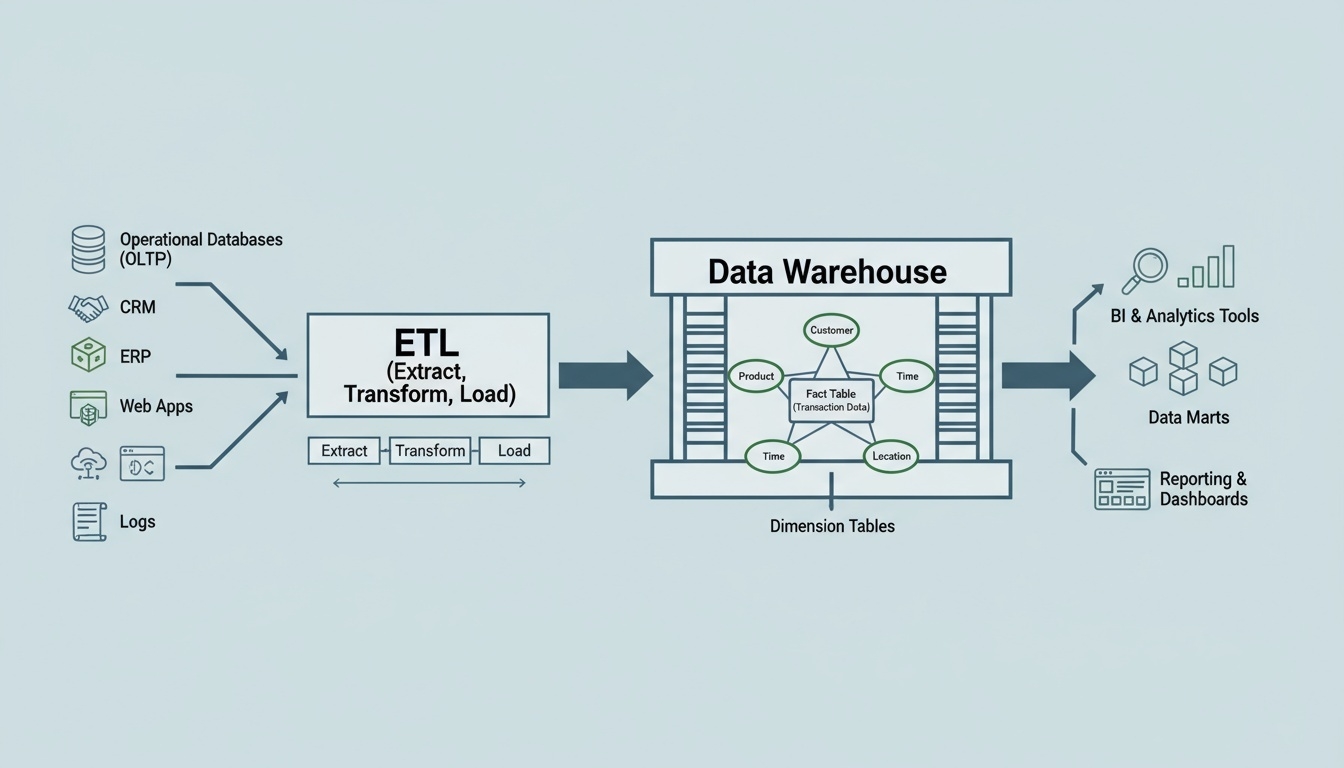
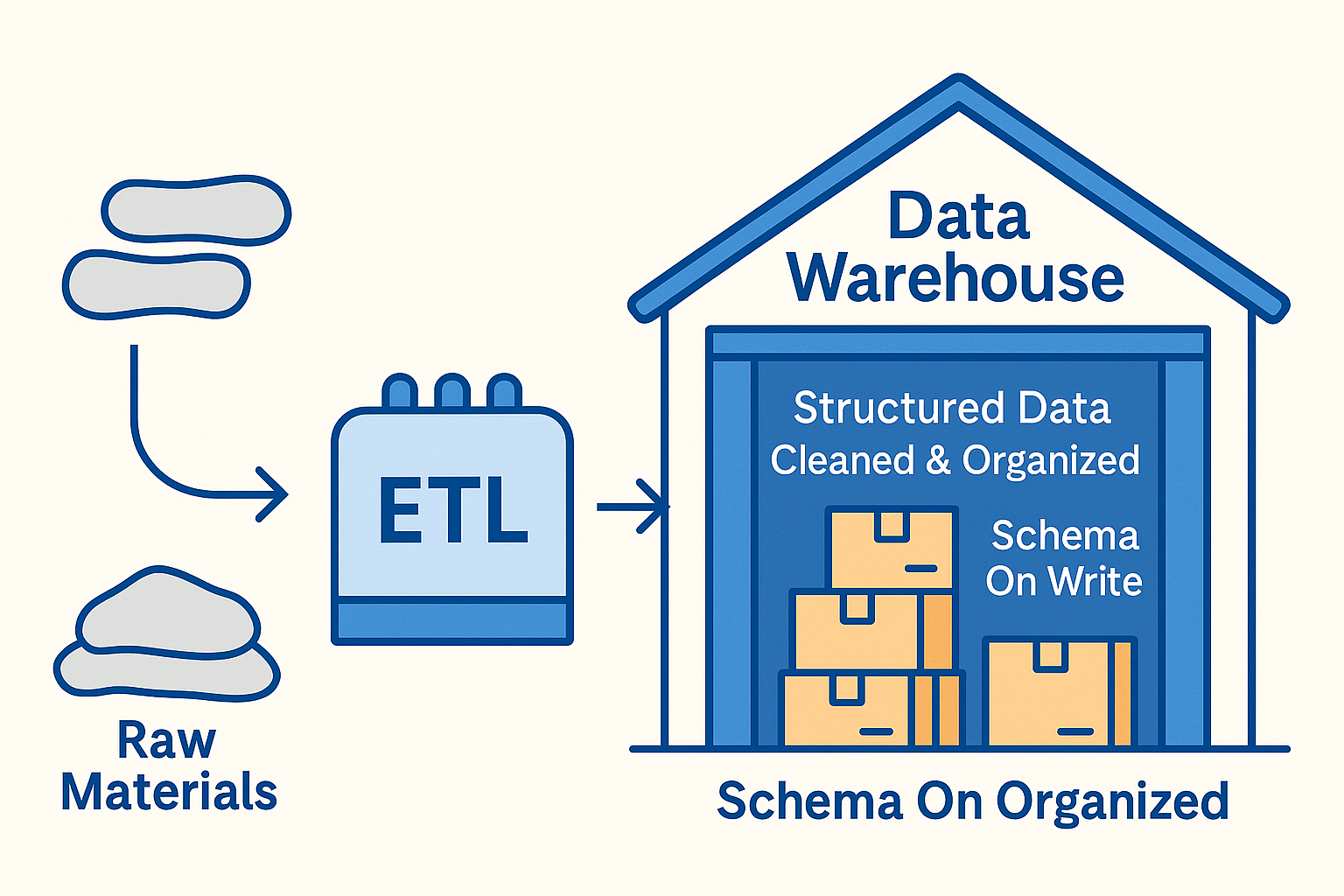
Data Warehouse
데이터 웨어하우스(Data Warehouse)는 기업의 의사결정과 분석 업무를 지원하기 위해, 정제되고 구조화된 데이터를 저장하는 중앙 집중형 데이터 저장소이다.
업무 시스템에서 수집된 데이터를 ETL(추출·변환·적재) 과정을 거쳐 품질을 보장한 뒤 저장하며, 경영 분석, BI 리포트, 통계 분석 등에 활용된다.
데이터 웨어하우스는 “잘 정리된 창고”에 비유할 수 있다. 필요한 물건이 종류별로 정리되어 있어, 누구든지 쉽게 찾아서 사용할 수 있는 구조를 가진다.
-
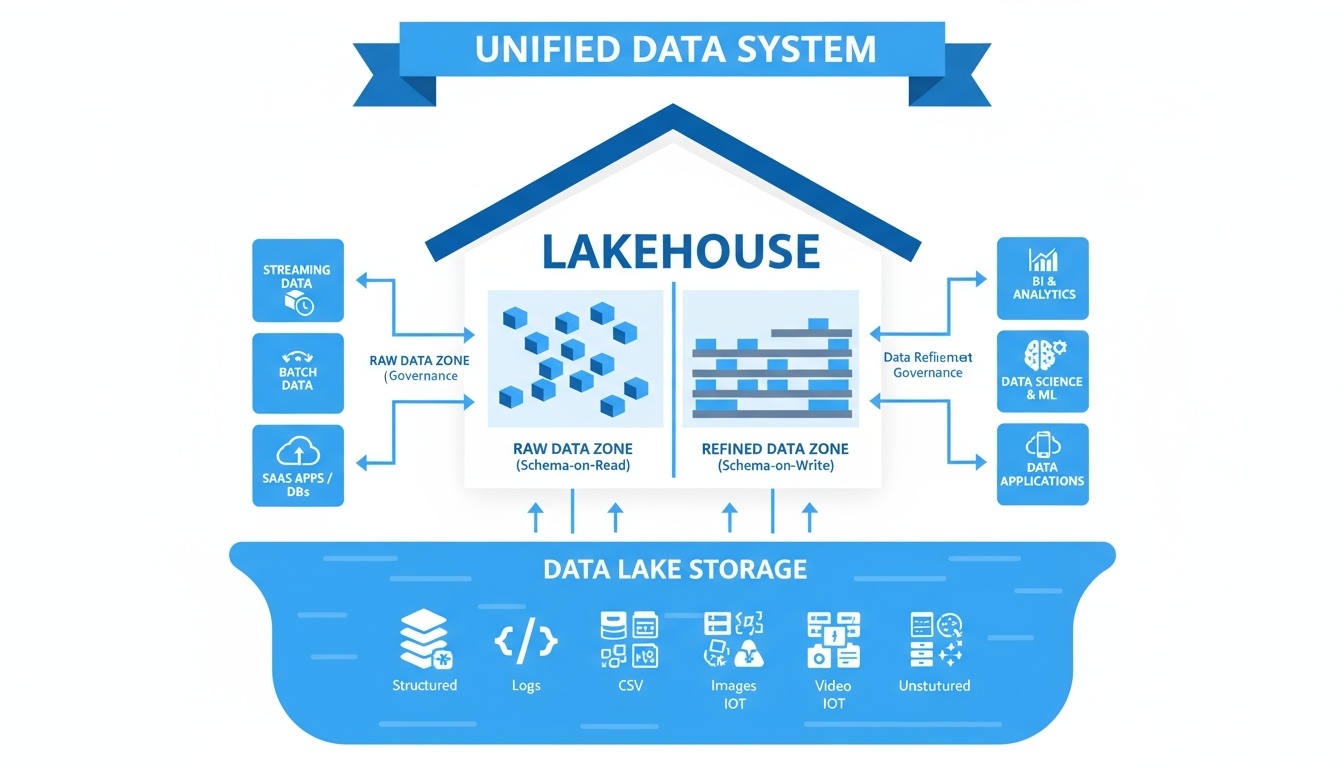
Lakehouse
Lakehouse(레이크하우스)는 Data Lake의 유연성과 Data Warehouse의 구조적 분석 능력을 결합한 통합 데이터 아키텍처이다.
원본 데이터를 저장하면서도, 동시에 정제·가공된 데이터 분석 환경을 제공하여 AI/ML 분석과 BI 분석을 모두 처리할 수 있는 통합형 플랫폼이다.
Lakehouse는 이름처럼 “Lake + Warehouse” 의 합성 개념으로, 데이터 레이크의 확장성과 다양한 데이터 저장 능력, 데이터 웨어하우스의 데이터 품질·관리·분석 성능을 동시에 제공한다.
-
왜 Lakehouse가 필요한가
기존 데이터 레이크는 파일 중심 저장으로 유연하지만, 스키마·ACID 미보장 문제로 신뢰성 있는 분석이 어려웠다.
반대로 데이터 웨어하우스는 품질과 SQL 분석에 강하지만, 비용이 높고 반정형·비정형 처리 유연성이 떨어졌다.
Lakehouse는 이 두 영역의 장점을 통합해, 한 번 저장한 데이터를 다양한 워크로드에서 일관되게 활용한다.
-
Hadoop 개요
Hadoop은 대규모 데이터를 분산 환경에서 저장하고 처리하기 위해 개발된 오픈소스 프레임워크로, 저렴한 범용 서버 여러 대를 묶어 하나의 대형 시스템처럼 동작하도록 한다. 특히 대용량(Volume)·고속 생성(Velocity)·다양성(Variety) 으로 대표되는 빅데이터 처리의 태동기에 핵심 기술로 자리 잡았다.
Hadoop이 등장한 배경
인터넷과 디지털 서비스의 확산으로 데이터 규모가 폭발적으로 증가하면서, 기존 RDBMS 기반의 데이터 처리 방식만으로는 대응하기 어려운 상황이 발생했다. 또한 정형 데이터뿐 아니라 로그, 센서 데이터, 이미지, 영상 등 다양한 형태의 비정형 데이터가 등장하며 새로운 데이터 처리 패러다임이 요구되었다.
-
데이터 폭증과 기존 RDBMS의 한계
기업과 서비스에서 생성되는 데이터가 TB → PB 단위로 증가하였고, 단일 서버 성능을 올리는 Scale-Up 방식은 비용과 구조적 한계를 드러냈다.
-
정형 중심 처리 구조의 한계
RDBMS는 스키마가 고정된 정형 데이터 처리에 최적화되어 있었지만, 웹 로그, 클릭스트림, SNS, IoT 데이터 등 반정형·비정형 데이터 처리에는 한계가 있었다.
-
분산 파일 시스템과 병렬 처리에 대한 필요성 대두
여러 서버에 데이터를 나누어 저장하고 동시에 처리할 수 있는 분산 저장 + 병렬 처리 기술이 요구되었다. “데이터가 있는 곳에서 처리(Data Locality)”하는 방식이 주목받기 시작했다.
-
구글의 분산 기술 논문 공개가 전환점
Google의 GFS(Google File System), MapReduce 논문이 발표되며 새로운 확장이 열렸다. 이를 바탕으로 오픈소스 형태의 Hadoop 프로젝트가 개발되며 누구나 분산 데이터 처리를 구현할 수 있게 되었다.
-
저비용·고확장성 데이터 처리 패러다임 수요 증가
비싼 장비 대신 여러 대의 값싼 범용 서버(Commodity Hardware) 를 묶어 대규모 데이터 처리를 수행하는 기술이 업계 표준으로 자리 잡았다.
결과적으로, Hadoop은 “저렴한 비용으로 대용량 데이터를 분산 환경에서 안정적으로 저장하고 처리하기 위해 탄생한 기술”이다.
Hadoop의 특징
-
저비용 분산 처리
범용 하드웨어(Commodity Hardware)를 여러 대 연결하여 대규모 데이터를 저장·처리할 수 있다. 고가 장비 없이도 수평 확장이 가능해 비용 효율적이다.
-
고장 허용(Fault Tolerance)
일부 노드 장애가 발생해도 자동 복제 및 재처리 메커니즘을 통해 작업이 지속된다. 데이터 복제(Replication)로 안정성을 확보한다.

-
수평 확장성(Scale-Out)
노드(저렴한 서버 등)를 추가하는 것만으로 성능과 저장 용량을 증가시킬 수 있다. 데이터 증가에 유연하게 대응 가능하다.
-
대용량 데이터 처리에 최적화
대규모 데이터셋을 여러 노드에 분산 저장하고, 병렬로 작업을 수행하여 처리 속도를 높인다.

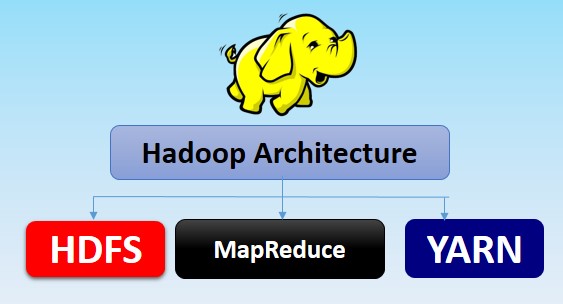
Hadoop의 핵심 구성 요소
-
HDFS (Hadoop Distributed File System)
대규모 데이터를 여러 노드에 분산 저장하는 파일 시스템이다. 한 번 기록된 대규모 데이터를 빠르게 읽는 데 최적화되어 있다.
-
MapReduce
데이터를 분산 처리하기 위한 프로그래밍 모델이다. 작업을 쪼개어 여러 노드에서 병렬 처리하고 결과를 합산한다.
-
YARN (Yet Another Resource Negotiator)
클러스터 자원(CPU, 메모리 등)을 관리하고, 다양한 응용 프로그램 실행을 조정한다.
-
Hadoop Ecosystem
Hive,Pig,HBase,Sqoop,Flume,Oozie,Zookeeper등 다양한 데이터 처리/관리 도구로 확장된 Hadoop 기반 생태계가 존재한다.
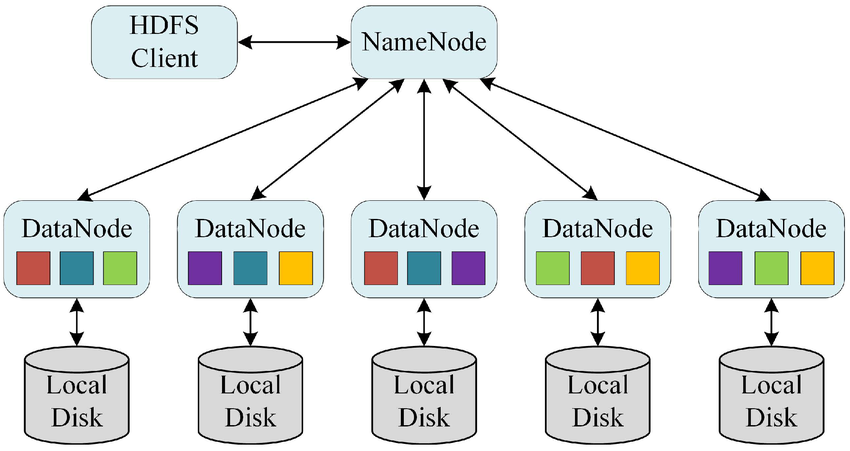
HDFS
HDFS(Hadoop Distributed File System)는 대용량 데이터를 여러 노드에 분산 저장하는 Hadoop의 핵심 분산 파일 시스템으로, 장애 발생 시에도 데이터 유실 없이 안정적으로 운영될 수 있도록 설계되었다.
비유로 이해하는 HDFS (학교 버전)
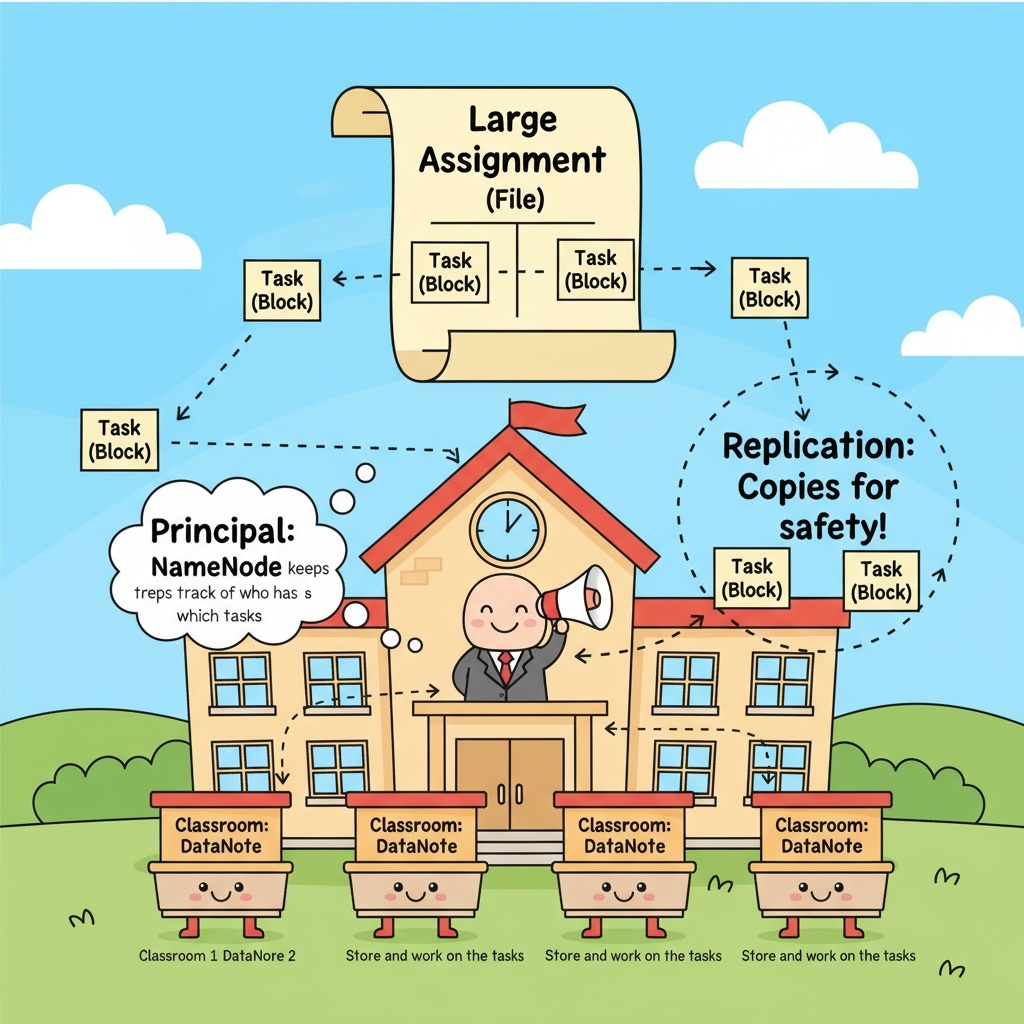
HDFS를 학교에 비유해보면 이해가 훨씬 쉬워진다.
학교에는 교장(NameNode) 이 있고, 여러 개의 반(DataNode) 이 있으며, 학생들에게 나눠줄 과제(Block) 가 있다고 생각해보자.
-
교장 = NameNode
교장은 직접 과제를 보관하거나 해결하지 않는다. 대신 어떤 과제(Block)가 어떤 반(DataNode)에 배정되었는지 기록하고 관리하는 역할을 한다. 즉, NameNode는 데이터의 위치 정보를 관리하는 “메타데이터 관리자” 이다.
-
각 반 = DataNode
실제로 과제를 수행하고 보관하는 곳은 반(DataNode)이다. 각 반은 자신에게 배정된 과제(Block)를 가지고 있고, 정상적으로 보관 중인지 교장에게 주기적으로 보고(Heartbeat) 한다.
-
과제를 쪼개서 나누어 주기 = 블록 단위 저장
한 명에게 주기엔 너무 큰 과제라면, 과제를 여러 조각(Block)으로 나누어 여러 반에 나누어 줄 수 있다. HDFS도 큰 파일을 블록 단위로 쪼개 여러 DataNode에 저장한다.
-
여러 반에 같은 과제 복사본 주기 = 복제(Replication)
혹시 어떤 반에서 사고가 나서 과제를 잃어버릴 수 있기 때문에 같은 과제 블록을 여러 반에 복사(기본 3개) 해서 나누어 준다. 이렇게 하면 한 반이 망가져도 다른 반에서 과제를 다시 가져올 수 있다.
요약 정리
| 학교 비유 | HDFS 개념 | 역할 |
|---|---|---|
| 교장 | NameNode | 데이터 위치·메타데이터 관리 |
| 반 | DataNode | 데이터 블록 저장 |
| 과제 조각 | Block | 파일을 나눈 저장 단위 |
| 같은 과제 여러 반에 배정 | Replication | 데이터 유실 방지 |
HDFS 기술적 이해
-
분산 저장 방식
하나의 대용량 파일을 작은 블록(Block) 단위로 나누어 여러 노드에 저장한다. 이를 통해 대규모 데이터를 효율적으로 저장하고 병렬로 읽기/처리가 가능해진다.
-
데이터 관리 시스템: NameNode / DataNode
HDFS는 마스터-슬레이브 구조로 동작하며, 크게 두 종류의 노드로 구성된다.
NameNode
파일 시스템의 메타데이터를 관리하는 핵심 노드이다. 어떤 파일이 어떤 블록으로 나뉘어 있으며, 각 블록이 어떤 DataNode에 저장되었는지에 대한 정보를 저장하고 관리한다. (예: 파일 이름, 블록 위치, 접근 권한 등)
DataNode
실제 데이터 블록을 저장하고 관리하는 노드이다. NameNode의 지시에 따라 블록을 저장·전송하며, 주기적으로 상태 정보를 NameNode에 보고한다. (예: “정상 동작 중”, “블록 저장 완료” 등)
-
데이터 저장 방식: 블록(Block)
HDFS에서는 대용량 파일을 일정 크기의 블록(Block) 단위로 나누어 저장한다. 기본 블록 크기는 보통 128MB 또는 256MB이며, 일반 파일 시스템보다 훨씬 크다.
블록 단위 저장 방식의 장점은 다음과 같다:
-
대용량 파일 처리 효율성
하나의 큰 파일도 여러 노드에 나누어 저장할 수 있어 저장 한계를 극복할 수 있다.
-
병렬 처리 가능
나뉜 블록을 여러 DataNode에서 동시에 읽고 처리할 수 있어 작업 속도가 빨라진다.
-
-
데이터 신뢰성 확보: 복제(Replication)
파일 블록(Block)은 기본적으로 여러 노드에 복제(기본값: 3개) 되어 저장된다. 한 노드가 장애가 나더라도 다른 노드에 복제본이 존재하기 때문에 데이터 유실 없이 안정적으로 서비스할 수 있다.
MapReduce
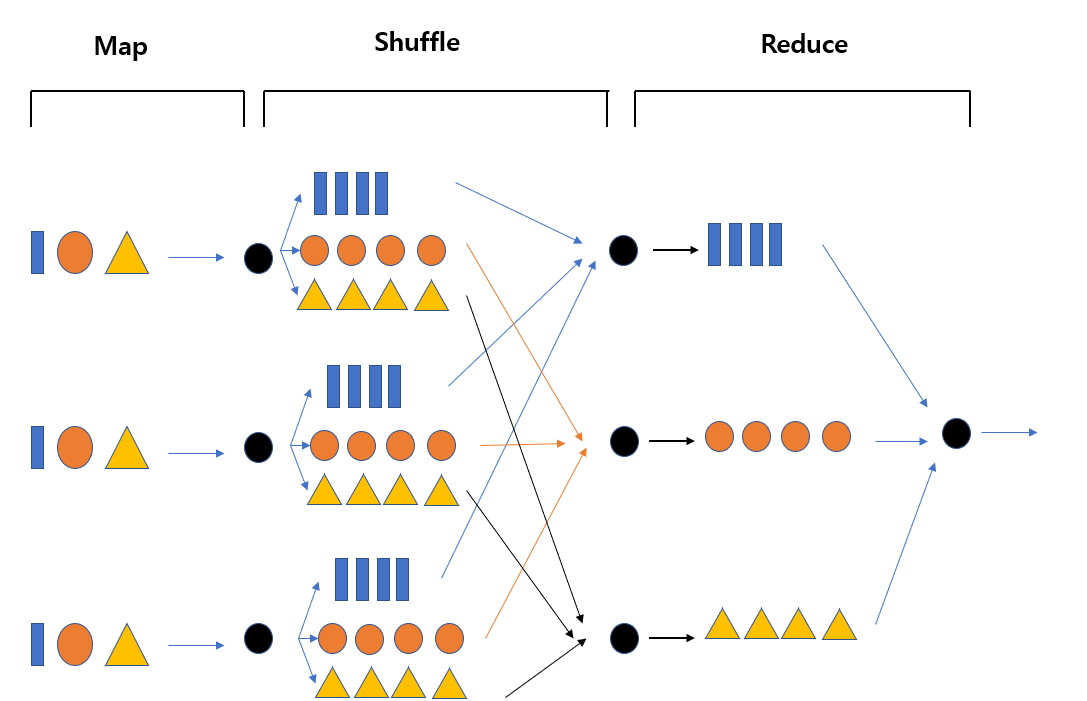
MapReduce는 대용량 데이터를 분산 환경에서 병렬 처리하기 위한 프로그래밍 모델이다. 복잡한 데이터 처리 작업을 두 단계(Map 단계와 Reduce 단계)로 나누어 여러 노드에서 동시에 실행함으로써 처리 속도를 높인다.
아래 그림은 MapReduce가 대용량 데이터를 나누어 처리하고 다시 합쳐 결과를 만드는 전체 흐름을 시각화한 것이다. MapReduce는 크게 Map → Shuffle → Reduce의 세 단계로 이루어진다.
-
Map 단계 — 데이터를 “쪼개서 가공”하는 단계
Map 단계에서는 입력 데이터를 여러 조각으로 나누어 여러 작업자(Map Task)가 병렬 처리한다. 각 Map Task는 데이터를 처리하여 (Key, Value) 형태의 중간 결과를 생성한다.
-
입력 데이터가 여러 Map 작업자로 분배된다.
-
각 Map 작업자는 데이터에서 필요 정보만 추출하고 Key-Value 형태로 변환한다.
-
동일한 Key를 가진 데이터가 여러 Map Task에서 생성될 수 있다.
Map 단계는 “
데이터를 나누어 동시에 처리하고 Key-Value 결과를 만드는 단계”이다. -
-
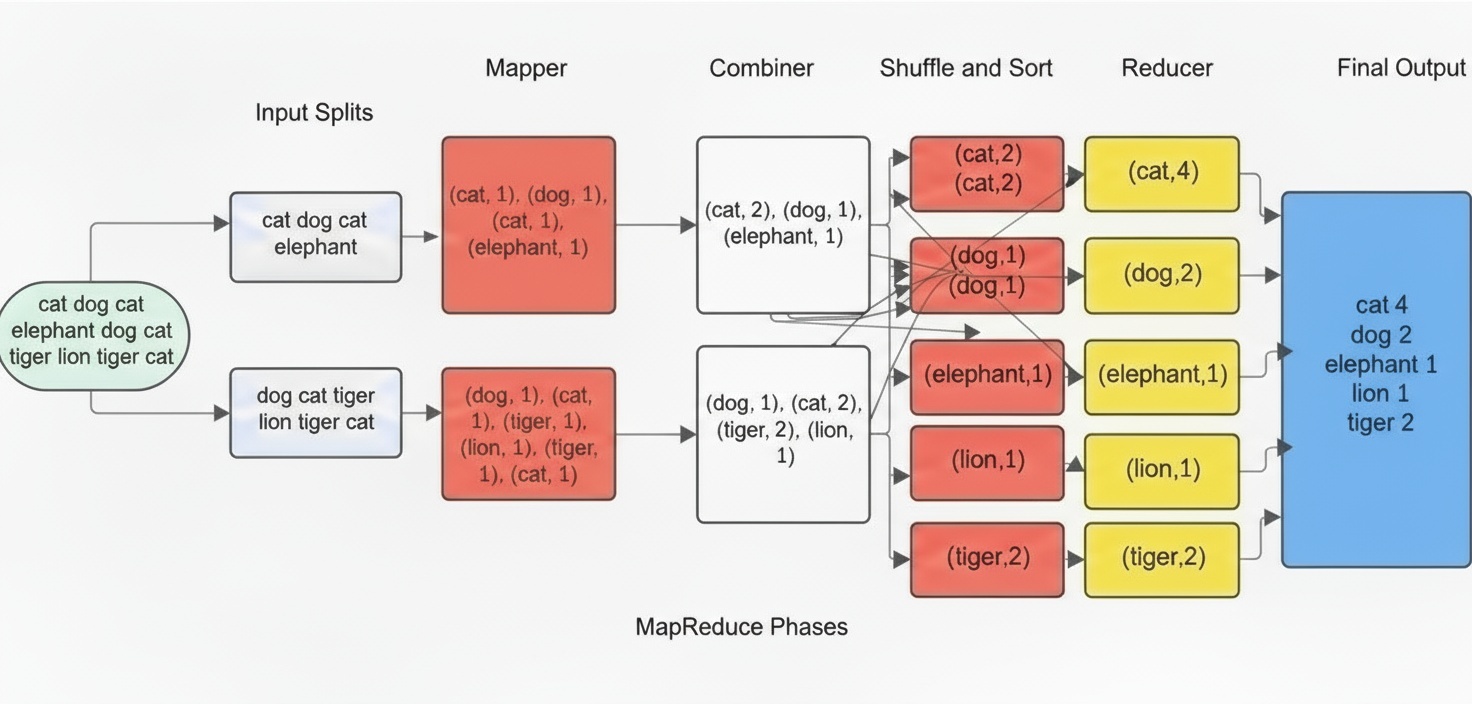
Combiner 단계 (Optional)
MapReduce에서 Combiner는 선택적으로 사용되는 단계로, Map 단계에서 생성된 중간 결과를 로컬에서 한 번 더 간단히 합쳐주는 역할을 한다.
Map 작업이 끝나면 보통 (Key, Value) 형태의 결과가 많이 생성되는데, 이 값을 그대로 Shuffle 단계로 보내면 네트워크 전송량이 매우 커질 수 있다. Combiner는 이러한 문제를 줄이기 위해 같은 Map 작업 내에서 동일한 Key를 가진 값들을 미리 합산하여 데이터 양을 줄여 준다.
예를 들어, 한 Map 작업에서 “cat”이라는 단어가 5번 등장했다면, 원래는 (cat, 1)을 5번 보내야 하지만, Combiner가 있다면 이를 미리 (cat, 5)로 묶어서 Shuffle로 넘길 수 있게 된다.
즉, Combiner는 Reduce 과정과 비슷한 “미니-Reduce” 역할을 Map 단계 바로 뒤에서 수행함으로써, 네트워크 사용량을 줄이고 전체 처리 속도를 향상시키는 효과가 있다.
단, Combiner는 항상 실행된다는 보장이 없고, 상황에 따라 생략될 수 있는 선택적 단계라는 점도 기억해야 한다. 따라서 Combiner를 사용할 때는 순서가 바뀌어도 결과가 동일하게 유지되는 연산(예: 합계, 개수 세기)에서만 안전하게 사용할 수 있다.
-
Shuffle 단계 — “같은 Key끼리 모으는 과정”
Map 단계에서 만들어진 중간 결과는 Key 값이 섞여 있으므로, 같은 Key를 가진 값들끼리 모아서 그룹화하는 과정이 필요하다. 이 단계가 Shuffle이다.
-
서로 다른 Map Task에서 생성된 결과 중 같은 Key끼리 재분배된다.
-
Key 기준으로 정렬 및 그룹화가 이루어진다.
-
이후 Reduce Task로 전달할 준비가 완료된다.
Shuffle 단계는 “
여러 Map 결과에서 같은 Key들을 한 곳으로 모아주는 정리 단계”이다. -
-
Reduce 단계 — “Key별로 최종 결과 생성”
Shuffle 단계에서 Key별로 모인 데이터가 Reduce 단계로 전달되면, Reduce Task는 집계, 계산, 요약 작업을 수행하여 최종 결과를 생성한다.
-
같은 Key에 대한 Value들을 하나로 합치는 작업 수행 (예: 합계, 평균, 최대/최소, 개수 세기 등)
-
Key별 최종 결과 출력
Reduce 단계는 “
같은 Key 데이터를 합쳐 최종 결과를 도출하는 단계”이다. -
-
Final Output \(\to\) Data Block
Hadoop(HDFS)에서는 모든 파일은 자동으로 일정 크기의 블록 단위로 저장된다.
즉, 최종 결과 파일도 예외가 아니다.기본 블록 크기: 128MB 또는 256MB (클러스터 설정에 따라 다름)
예를 들어, Reduce 단계에서 만들어진 최종 결과 파일 크기가 350MB라고 가정해보자.
블록 번호 저장 크기 Block 1 128MB Block 2 128MB Block 3 94MB
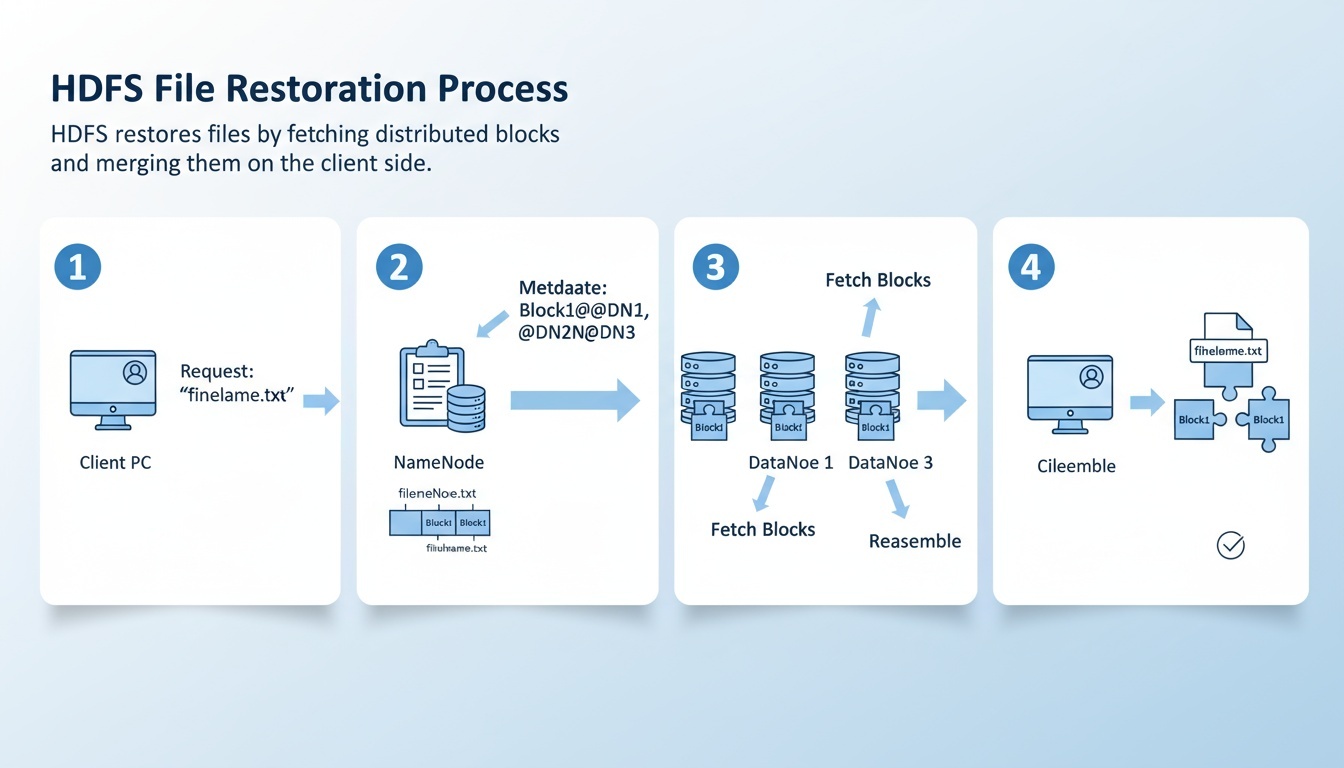
나뉜 블록들은 어떻게 원래 데이터로 복원될까?
HDFS에서는 파일이 여러 블록으로 나뉘어 저장되지만, 사용자가 파일을 읽을 때는 HDFS가 이를 자동으로 복원해 하나의 파일처럼 제공한다.
이는 NameNode가 블록의 위치 및 순서 정보를 관리하고, HDFS 클라이언트가 이를 기반으로 블록을 연결하여 원본 파일을 복원하기 때문이다.
-
복원 과정은 다음과 같다.
-
사용자가 파일 읽기 요청을 보낸다.
사용자가 명령어(
hdfs dfs -cat <파일명>) 또는 프로그램 API를 통해 파일을 읽으려는 요청을 한다. -
NameNode가 블록 메타데이터를 전달한다.
NameNode는 해당 파일이 어떤 블록(Block 1, Block 2, Block 3 등)으로 구성되어 있으며,
각 블록이 어느 DataNode에 저장되어 있는지를 클라이언트에게 알려준다. -
클라이언트가 각 DataNode에 직접 연결하여 블록을 가져온다.
NameNode는 파일 데이터를 직접 전달하지 않는다.
클라이언트는 전달받은 위치 정보를 바탕으로 여러 DataNode에 접속해
필요한 블록들을 순서대로 가져온다. -
클라이언트가 블록을 자동으로 병합하여 원본 파일로 복원한다.
HDFS 클라이언트 라이브러리가 블록들을 원래 순서대로 이어붙여 하나의 파일로 완성한다.
이 과정은 내부적으로 자동 수행되므로, 사용자는 마치 단일 파일을 읽는 것처럼 이용할 수 있다.
-
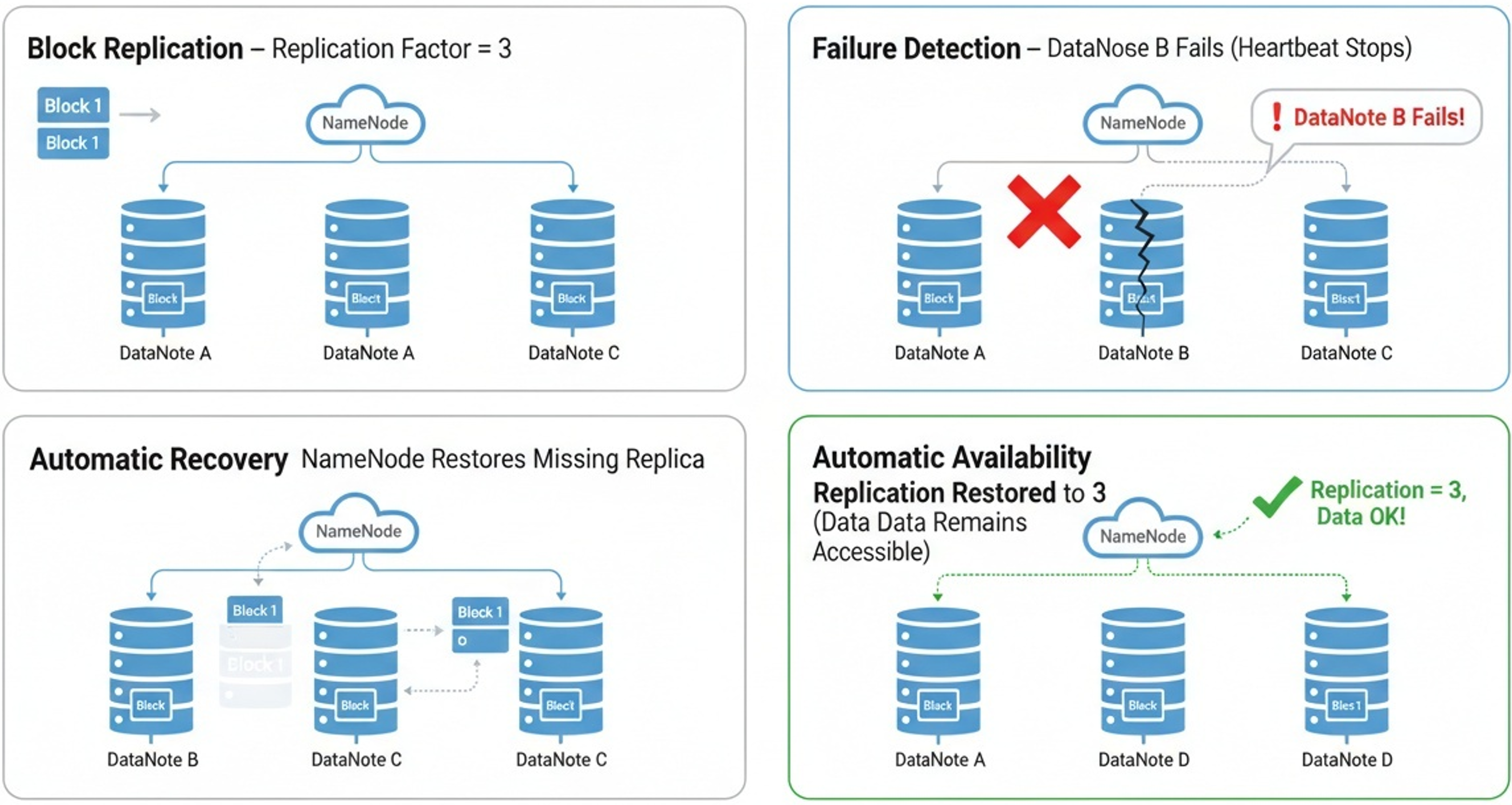
블록 복제와 장애 복구 과정
HDFS는 대규모 분산 환경에서 안정성과 신뢰성을 보장하기 위해 블록 복제(Replication) 방식을 사용한다.
즉, 하나의 블록을 여러 개의 DataNode에 복사하여 저장함으로써, 특정 노드에 장애가 발생하더라도 데이터를 안전하게 보호할 수 있도록 설계되어 있다.
-
블록 복제와 장애 복구 과정은 다음과 같다.
-
블록 복제 저장
기본적으로 HDFS는 각 블록을 여러 노드에 복제하여 저장한다.
일반적인 복제 계수(Replication Factor)는 3이며,
예를 들어 Block 1은 서로 다른 세 개의 DataNode에 나누어 저장된다.
이를 통해 하나의 노드가 고장나도 다른 노드에서 동일한 블록을 가져올 수 있다. -
노드 장애 감지
NameNode는 DataNode로부터 주기적으로 상태 보고(Heartbeat)를 받는다.
만약 특정 DataNode의 응답이 일정 시간 동안 도착하지 않으면,
해당 노드가 장애가 발생했다고 판단한다. -
자동 복구(재복제) 수행
장애가 발생한 노드에 저장된 블록 중, 복제 개수가 기준 이하로 떨어진 블록이 있을 경우
NameNode는 다른 정상 DataNode들에 명령하여 부족한 블록 복제본을 자동으로 생성하도록 지시한다.
이를 통해 복제 개수를 다시 정상 수준으로 회복시켜 데이터 안정성을 보장한다. -
사용자는 장애를 체감하지 않는다.
블록 복구 과정은 내부적으로 자동 진행되며, 사용자는 장애 발생 여부와 관계없이
동일한 파일을 정상적으로 읽고 사용할 수 있다.
즉, HDFS는 노드 장애 상황에서도 지속적인 데이터 접근성을 유지하는 분산 파일 시스템이다.
-
Hadoop Ecosystem
Hadoop Ecosystem은 단순히 Hadoop(HDFS + MapReduce)만을 의미하는 것이 아니라, 대규모 데이터의 수집 → 저장 → 처리 → 분석 → 관리 전 과정을 지원하기 위해 함께 동작하는 다양한 오픈소스 도구들의 통합 생태계(Ecosystem) 를 말한다.
즉, Hadoop을 중심으로 서로 다른 역할을 가진 여러 컴포넌트들이 모여 빅데이터 인프라를 하나의 완성된 플랫폼처럼 사용할 수 있도록 만들어주는 환경이다.
| 컴포넌트 | 역할 | 쉬운 설명 |
|---|---|---|
| HFDS | 데이터 파일 시스템 | 데이터 저장 창고 |
| YARN | 리소스/작업 관리 | 작업 스케줄링 & 자원 관리하는 교통/도로망 |
| Hive | 데이터 웨어하우스 | 데이터를 정리해 검색·분석하는 도서관/검색 시스템 |
| HBase | 분산 Key-Value Store | 빠른 조회가 가능한 NoSQL 데이터 창고 |
| Zookeeper | Coordination Service | 동물원 사육사는 사자, 호랑이, 원숭이 등 다양한 동물이 멋대로 움직이지 않도록 조율 |
| Kafka (선택) | 스트리밍 처리 | 실시간 데이터 전달을 위한 우편 배송 서비스 |
Spark 개요
Spark 등장 이유
Hadoop 시대에는 대용량 데이터를 처리하기 위해 주로 MapReduce 방식이 사용되었다. MapReduce는 분산 환경에서 안정적으로 데이터를 처리할 수 있다는 장점이 있었지만, 실제 데이터 분석 및 머신러닝 분야에서는 여러 한계를 드러냈다.
- 처리 속도의 한계 MapReduce는 각 단계마다 디스크(HDFS)에 결과를 저장하는 구조를 가지고 있다. 즉, 연산 과정에서 매번 디스크 읽기/쓰기(I/O)가 발생하여 처리 속도가 느려질 수밖에 없었다. 특히, 반복 연산이 많은 작업에서는 성능 저하가 더욱 크게 나타났다.
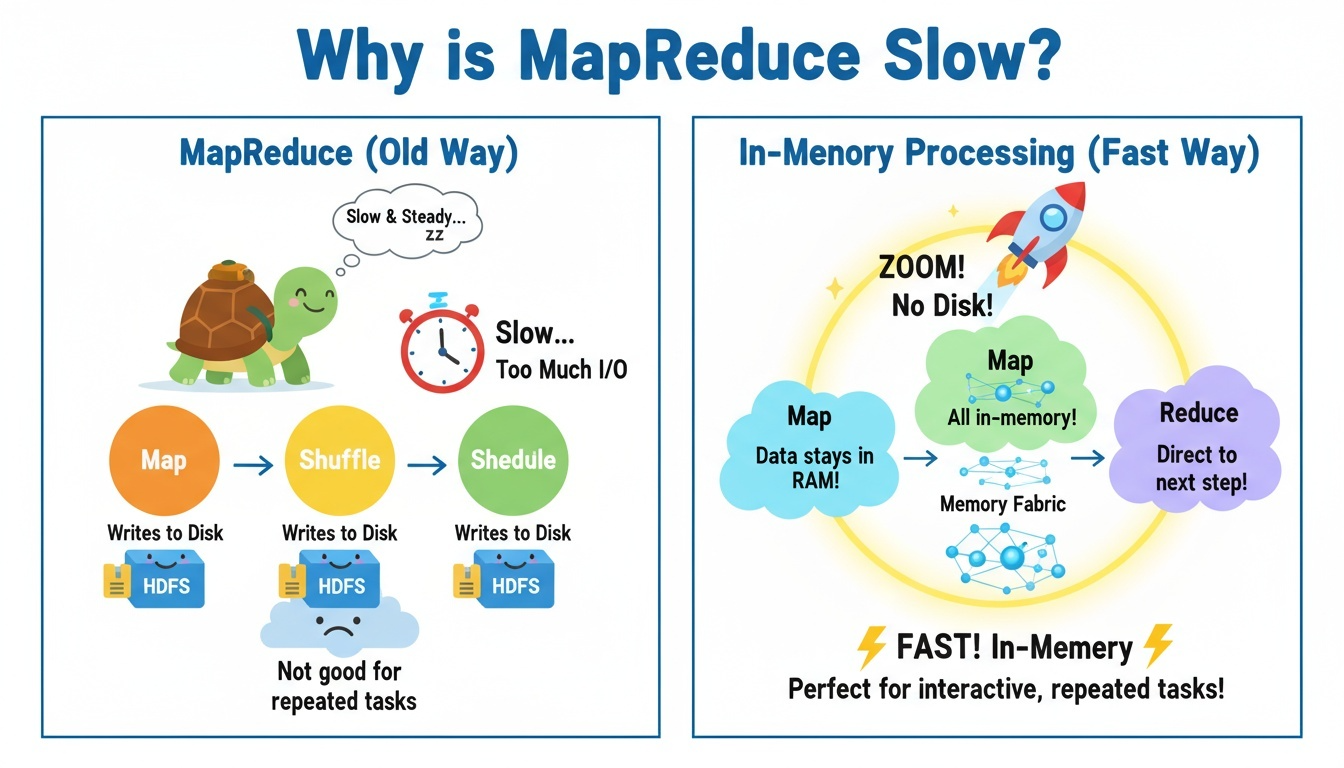
- 반복·탐색형 연산(Iterative Computation)에 취약 머신러닝 학습, 그래프 분석, 실시간 데이터 처리와 같은 작업은 동일한 데이터를 여러 번 반복적으로 연산하는 경우가 많다. 하지만 MapReduce는 반복 시마다 데이터를 다시 디스크에서 읽어야 하므로 효율적이지 않았다.
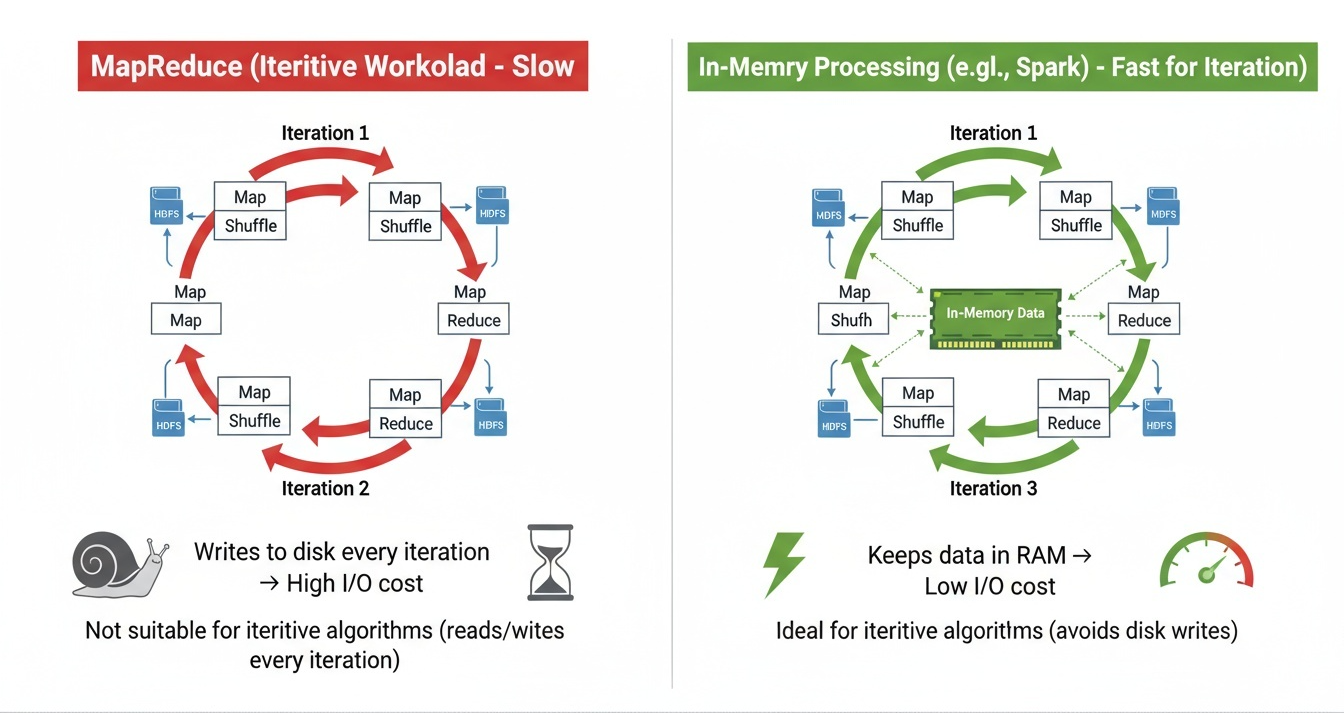
이러한 문제를 해결하기 위해 등장한 것이 Apache Spark이다.
Spark는 In-Memory 기반 처리 엔진으로, 데이터를 메모리(RAM)에 유지한 채 연속된 연산을 수행할 수 있다. Spark는 디스크 I/O 부담이 크게 줄어 MapReduce 대비 10배~100배까지 빠른 속도로 처리할 수 있다.
Spark는 "
빅데이터 시대의 고속 엔진"으로, 속도와 반복 연산 문제를 해결하기 위해 등장한 차세대 분산 처리 프레임워크이다.
Spark 구조
- Driver, Executor, Cluster Manager
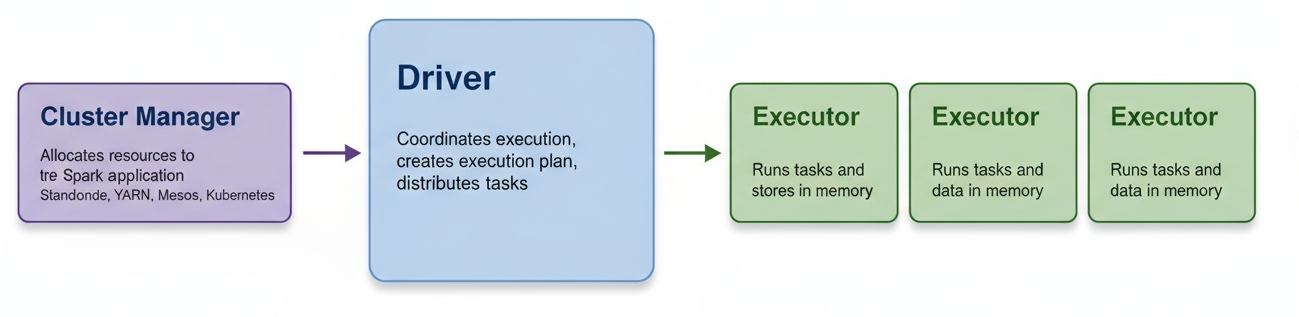
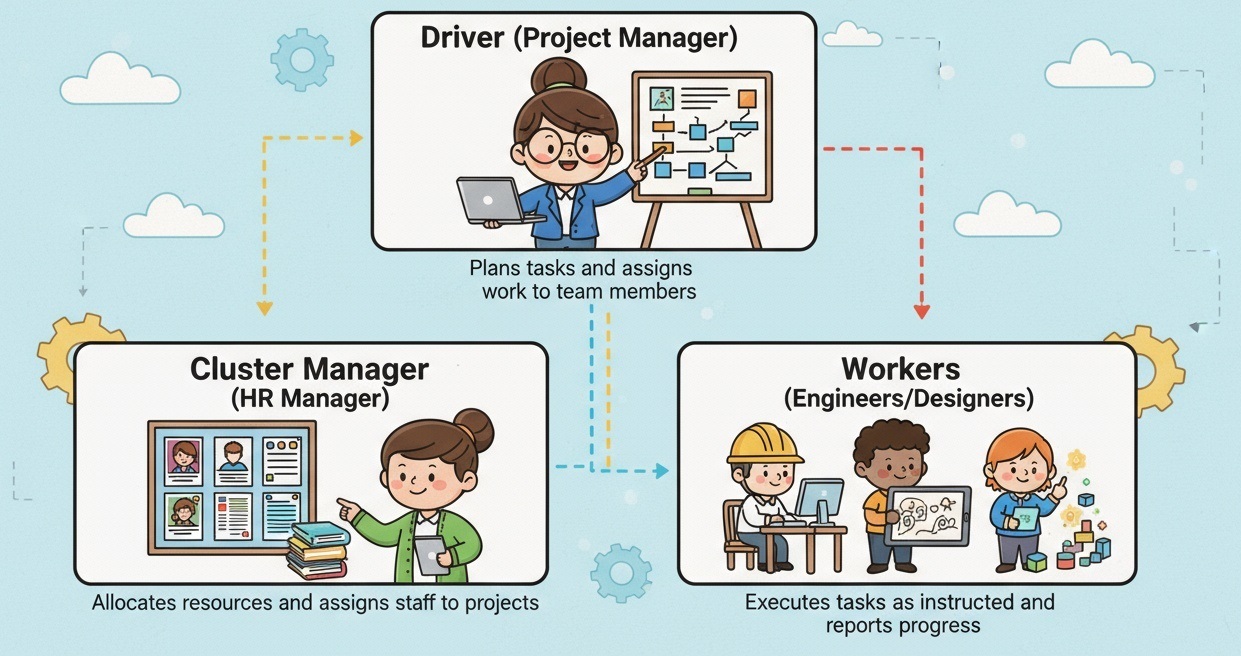
| 구성 요소 | 기술적 설명 | 쉬운 비유 설명 |
|---|---|---|
| Driver | - Spark 애플리케이션의 메인 프로세스 - 실행 계획(Logical/Physical Plan) 수립 및 최적화 - Task를 Executor에 분배하고 결과를 수집 |
프로젝트 매니저(PM) 일정을 계획하고, 팀원들에게 업무를 배정하며 결과를 취합해 보고하는 역할 |
| Executor | - 클러스터 각 노드에서 Task 실행 - 실제 연산, 변환, 집계 수행 - 필요 시 데이터 메모리 캐싱 |
팀원(실무자 개발자) PM이 준 일을 실제로 수행하고 결과물을 만들어내는 사람 |
| Cluster Manager | - 클러스터 자원(CPU, 메모리 등)을 관리 - Executor 실행 위치와 자원 할당 결정 - Standalone, YARN, Mesos, Kubernetes 등 지원 |
인사/자원 배정 담당자(HR 매니저) 누가 어떤 프로젝트에 배정될지, 몇 명이 필요한지, 어떤 장비를 줄지 결정하는 역할 |
Spark vs Hadoop 비교
| 항목 | Hadoop MapReduce | Spark |
|---|---|---|
| 처리 방식 | 디스크 기반 처리(HDFS 활용) | In-Memory 기반 처리(RAM 활용) |
| 속도 | 상대적으로 느림 (디스크 I/O 영향 큼) | 매우 빠름 (메모리 중심 처리) |
| 반복 연산 | 비효율적 (매 반복 시 디스크 읽기/쓰기 발생) | 효율적 (메모리 캐싱으로 반복 연산 최적화) |
| 대화형 처리 | 약함 (Batch 중심) | 강함 (Interactive Notebook/REPL 지원) |
| PC 환경 실습 가능 여부 | 별도 클러스터 필요, 로컬 단독 실습은 제한적 | 로컬 PC, Docker, 단일 노드 환경에서도 실습 용이 |
실습: Spark with Jupyter (Docker)
환경 구성 안내
본 실습은 학생 PC(Windows 기준) 에서 Docker를 이용해 Spark 환경을 준비하고, Jupyter Notebook에서 간단한 Spark 코드를 실행해보는 것을 목표로 한다.
준비물
-
Windows 10/11 PC
-
Docker Desktop 설치
-
인터넷 연결
Docker 설치 및 실행
-
본인의 운영체제에 맞는 Docker Desktop 다운로드 및 설치
-
설치 후 Docker Desktop 실행
-
관리자 권한으로 명령 프롬프트 또는 PowerShell 실행
-
WSL업데이트
wsl --update
- 도커 로그인 (필요 시 수행)
docker login
- 아래 명령어로 Spark + Jupyter 환경 구성 ()
# PySpark + Jupyter Notebook 환경을 도커로 실행하는 명령어
# docker run -it \ # -it : 터미널 상에서 컨테이너와 상호작용 가능하도록 실행
# -p 8888:8888 \ # 로컬PC(왼쪽) 8888 포트를 컨테이너(오른쪽) 8888 포트와 연결
# # → 브라우저에서 Jupyter Notebook 접속 가능
# -p 4040:4040 \ # Spark UI용 포트 연결
# # → http://localhost:4040 에서 Spark 실행 계획/작업 모니터링 가능
# --name spark \ # 컨테이너 이름을 'spark'로 지정
# # → 컨테이너 관리(시작/중지/접속) 시 이름으로 제어 가능
# jupyter/pyspark-notebook # 사용할 도커 이미지 (Jupyter + PySpark 환경이 이미 세팅됨)
docker run -it -p 8888:8888 -p 4040:4040 --name spark jupyter/pyspark-notebook
실행 후 콘솔에 표시되는 URL(ex: http://127.0.0.1:8888/?token=...)을 브라우저에 입력하여 접속한다.
Jupyter Notebook 접속
-
접속 후 새 노트북 생성: New → Python 3 (ipykernel) 클릭
-
첫 셀에 Spark 초기 설정이 되어 있는지 확인 (기본적으로
SparkSession이 포함된 환경)
실습 내용
SparkSession 생성
Notebook 첫 셀에서 SparkSession 생성:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("First Spark App").getOrCreate()
spark
SparkSession은 Spark 사용의 시작점이며, DataFrame, SQL, ML, Streaming 등 모든 기능이 여기에 연결된다.
DataFrame 생성 및 조회
data = [
("Tom", 25, "Seoul"),
("Alice", 32, "Busan"),
("David", 41, "Incheon"),
]
columns = ["name", "age", "city"]
df = spark.createDataFrame(data, columns)
df.show()
출력 예시:
+-----+---+-------+
| name|age| city|
+-----+---+-------+
| Tom| 25| Seoul|
|Alice| 32| Busan|
|David| 41|Incheon|
+-----+---+-------+
Filtering, Aggregation
# 나이 30 이상 필터링
df.filter(df.age >= 30).show()
# 평균 나이 계산
df.groupBy().avg("age").show()
Pandas와 비슷하지만, 내부적으로는 분산 처리로 실행된다는 점이 핵심 차이점이다.
Spark SQL
# DataFrame을 SQL 테이블로 등록
df.createOrReplaceTempView("users")
spark.sql("SELECT name, age FROM users WHERE age >= 30").show()
Python 코드가 아닌 SQL 문법으로도 Spark 데이터를 조회할 수 있다.