Text Data Analysis
- 강의자료 다운로드: click me
학습 목표
-
텍스트 데이터의 특성과 텍스트 마이닝 워크플로(수집→전처리→분석→시각화)를 이해한다.
-
토큰화, 정규화, 불용어 제거, 어간·표제어 추출 등 핵심 전처리 기법을 영어(NLTK)·한국어(KoNLPy) 환경에 맞게 적용한다.
-
Counter와 형태소 분석, 불용어 사전을 활용해 단어 빈도 기반 핵심 키워드를 도출하고 시각화한다.
-
TextBlob과 Hugging Face 파이프라인 등 다양한 도구로 감성 분석을 수행하고 결과를 해석한다.
-
wordcloud와 matplotlib 등을 사용해 전처리된 텍스트를 워드클라우드로 표현하고 활용 시 주의점을 파악한다.
텍스트 데이터란?
현대 사회에서는 우리가 남기는 데이터의 상당수가 텍스트(text) 형태로 존재한다. 예를 들어, 뉴스 기사, SNS 게시물, 고객 리뷰, 이메일, 논문 등은 모두 비정형 데이터(unstructured data)이다. 즉, 숫자나 표 형식으로 정리된 구조적 데이터(structured data)와 달리, 텍스트 데이터는 일정한 형식이 없다.
이러한 텍스트 데이터를 분석하는 기술을 텍스트 마이닝(Text Mining) 이라고 하며, 자연어처리(NLP, Natural Language Processing) 기술과 밀접하게 연결되어 있다.
텍스트 분석은 다음과 같은 단계로 진행한다.
| 단계 | 설명 |
|---|---|
| 수집 (Collection) | 뉴스, 블로그, SNS 등에서 텍스트 데이터를 수집 |
| 전처리 (Preprocessing) | 불필요한 기호나 단어를 제거하고 정제 |
| 분석 (Analysis) | 단어 빈도, 감성(긍정/부정), 주제 등을 분석 |
| 시각화 (Visualization) | 워드클라우드, 그래프 등을 통해 결과 표현 |
텍스트 전처리 (Text Preprocessing)
텍스트 데이터는 사람이 읽을 때는 의미가 명확하지만, 컴퓨터가 이해하기 위해서는 전처리 과정이 꼭 필요한다.
토큰화 (Tokenization)
토큰화는 문장을 단어 단위로 나누는 과정이다. 예를 들어,
“데이터 사이언스는 흥미로운 학문이다.”
[‘데이터’, ‘사이언스는’, ‘흥미로운’, ‘학문이다’]
NLTK 소개
NLTK (Natural Language Toolkit)는 파이썬에서 가장 널리 사용되는 자연어처리(NLP) 라이브러리 중 하나이다.
텍스트를 단어로 나누거나, 품사를 분석하고, 감성 분석을 수행하는 등 자연어 데이터를 전처리하고 분석하기 위한 다양한 기능을 제공한다.
NLTK의 주요 특징은 다음과 같다:
| 기능 | 설명 |
|---|---|
| 토큰화(Tokenization) | 문장을 단어, 문장 등으로 분리 |
| 불용어 제거(Stopword Removal) | 의미 없는 단어 제거 |
| 표제어 추출(Lemmatization) | 단어의 기본형(표제어) 변환 |
| 감성 분석(Sentiment Analysis) | 문장의 긍·부정 감정 분석 |
| 말뭉치(Corpus) 제공 | 영어 텍스트 샘플 및 사전 데이터 포함 |
NLTK는 특히 영어 텍스트 분석에 강력한 도구로, 교육용 및 연구용으로 매우 자주 활용된다.
단, 한국어 텍스트의 경우에는 KoNLPy와 같은 별도의 형태소 분석기 사용이 필요하다.
# 의존성 패키지 설치
pip install nltk
import nltk
# 최초 한 번만 실행하면 되는 부분 입니다.
# NLTK 데이터 다운로드
# 이후 실행 시 download()는 불필요합니다.
# nltk.download('punkt') # 토큰화용 데이터
# nltk.download('punkt_tab') # 탭 구분 토큰화용 데이터
# nltk.download('stopwords') # 불용어 리스트
# nltk.download('wordnet') # 표제어 추출용 데이터
text = "Data Science is an exciting field."
tokens = nltk.word_tokenize(text)
print(tokens)
실행 결과
['Data', 'Science', 'is', 'an', 'exciting', 'field', '.']
🇰🇷 한국어 토큰화 (Korean Tokenization)
영어와 달리 한국어는 조사, 어미, 복합명사가 많기 때문에 단순한 공백 기준으로는 단어를 나누기 어렵다. 따라서 한국어 문장을 분석할 때는 전용 형태소 분석기를 사용한다.
대표적인 라이브러리는 KoNLPy 패키지이며, 내부에 여러 분석기(Okt, Komoran, Mecab 등)를 포함한다. 그중 Okt(Open Korean Text) 는 간단하고 학습용으로 많이 사용된다.
| 분석기 이름 | 개발 기관 / 배경 | 주요 특징 | 장점 | 단점 | 설치 명령어 |
|---|---|---|---|---|---|
| Okt (Open Korean Text) | Twitter → Kakao | 가장 널리 쓰이는 분석기. SNS, 뉴스 등 일반 문장에 강함 | - 설치 쉬움 - 토큰화 정확도 높음 - 감정 표현 분석에 적합 |
- 전문 용어 처리 한계 - 긴 문장에서는 속도 느림 |
pip install konlpy (기본 포함) |
| Komoran | Shineware | 품사 태깅 성능이 우수하며 문장 분석 정밀도 높음 | - 복합명사 인식 정확 - 빠른 처리 속도 |
- 일부 문장에서는 형태소 분리 과다 | pip install konlpy (기본 포함) |
| Mecab | Kakao / Google Korea 기반 | 가장 빠르고 정확한 분석기 (대용량 데이터에 강함) | - 처리 속도 매우 빠름 - 대규모 텍스트에 적합 - 품사 태깅 정밀도 높음 |
- 윈도우 환경 설치 복잡 - 별도 사전 필요 |
pip install python-mecab-ko |
| Hannanum | KAIST | 한국어 연구용으로 오래된 형태소 분석기 | - 전통적인 분석기 - 명사 추출 안정적 |
- 최신 언어 트렌드 반영 부족 | pip install konlpy (기본 포함) |
| Kkma | 서울대 | 문장 구조 분석까지 가능 (의존 구문 분석 포함) | - 문장 단위 분석 가능 - 문법적 관계 파악 가능 |
- 실행 속도 느림 - 메모리 사용량 많음 |
pip install konlpy (기본 포함) |
KoNLPy 설치
pip install konlpy
from konlpy.tag import Okt
okt = Okt()
text = "데이터 사이언스는 정말 흥미로운 학문이다."
# 단어 단위(토큰)로 분리
tokens = okt.morphs(text)
print("토큰:", tokens)
# 품사 태깅(Pos tagging)
pos_tags = okt.pos(text)
print("품사 태깅:", pos_tags)
# 명사만 추출
nouns = okt.nouns(text)
print("명사:", nouns)
실행 결과
토큰: ['데이터', '사이언스', '는', '정말', '흥미로운', '학문', '이다', '.']
품사 태깅: [('데이터', 'Noun'), ('사이언스', 'Noun'), ('는', 'Josa'), ('정말', 'Adverb'), ('흥미로운', 'Adjective'), ('학문', 'Noun'), ('이다', 'Josa'), ('.', 'Punctuation')]
명사: ['데이터', '사이언스', '학문']
💡 참고
-
morphs(text) : 형태소 단위로 분리
-
pos(text) : 각 단어의 품사를 함께 반환
-
nouns(text) : 명사만 추출
-
영어, 숫자, 한글이 섞인 문장도 대부분 잘 처리함.
정규화 (Normalization)
정규화란 텍스트 데이터를 일관된 형태로 바꾸는 과정이다.
같은 의미의 단어라도 표현 방식이 다르면 컴퓨터는 서로 다른 단어로 인식하기 때문에, 정규화를 통해 이런 차이를 최소화해야 한다.
예를 들면, 텍스트 데이터 분석에서는 다음과 같은 문제점이 존재한다.
“Data”, “data.”, “DATA!”, “data?”
이 네 단어는 사람이 보기엔 모두 ‘data’를 의미하지만,
컴퓨터는 각각 다른 단어로 처리한다.
따라서 텍스트 데이터를 분석할 때는 다음과 같은 변환을 수행해준다.
| 단계 | 설명 | 예시 |
|---|---|---|
| 소문자 변환 (Lowercasing) | 대소문자 구분을 없앰 동일 단어로 인식하게 함 |
“Data”, “DATA” → “data” |
| 특수문자 제거 | 문장부호나 불필요한 기호 제거 |
“data-science!!” → “data science” |
| 공백 정리 | 여러 개의 공백을 하나로 줄임 |
“data science” → “data science” |
| 숫자/이모티콘 제거 (필요 시) | 분석 목적에 따라 숫자·이모티콘을 제거하거나 유지 |
“2024년 👍 데이터” → “데이터” |
정규화의 목표는 “사람이 보기엔 같지만, 컴퓨터는 다르게 보는” 단어들을 하나의 형태로 통일하는 것이다.
이 과정을 거치면 단어 중복이 줄고, 분석 정확도가 크게 높아진다.
💡 re 모듈 소개
re는 정규표현식(Regular Expression) 을 다루는 파이썬 내장 모듈로, 문자열에서 특정 패턴(규칙) 을 찾아내거나 바꿀 때 사용한다.
| 함수 | 설명 | 예시 |
|---|---|---|
re.sub(pattern, repl, text) |
패턴에 해당하는 문자열을 다른 값으로 치환 | re.sub(r'[^a-z]', '', 'ABC!') → 'ABC' |
re.findall(pattern, text) |
패턴에 맞는 모든 문자열을 리스트로 반환 | re.findall(r'\d+', '2025년 10월') → ['2025', '10'] |
re.split(pattern, text) |
패턴을 기준으로 문자열을 분리 | re.split(r'\s+', 'A B C') → ['A', 'B', 'C'] |
re 모듈은 텍스트 데이터를 다룰 때 매우 강력한 도구이며, 단순히 “기호를 지운다” 수준을 넘어 데이터를 깨끗하고 분석하기 좋은 형태로 만드는 정제 도구다.
re 모듈은 다양한 기능을 지원하기 때문에 자세한 내용은 아래 웹 페이지를 참고하여 개인적으로 추가 학습하기 바란다.
re 모듈 참고 웹페이지
| 구분 | 설명 | 링크 |
|---|---|---|
| 공식 문서 | Python 표준 라이브러리의 re 모듈 설명.모든 함수( match, search, sub, findall 등)의 동작과 인자 설명이 포함됨. |
Python 공식 문서: re — Regular expression operations |
| 정규표현식 HOW-TO | 초보자를 위한 Python 공식 “정규표현식 입문 가이드”. 메타문자, 그룹, 수량자 등 정규식의 원리를 체계적으로 설명함. |
Regular Expression HOWTO — Python Docs |
| Real Python 튜토리얼 | 실습 중심의 예제로 re 모듈 사용법을 설명.정규표현식을 단계별로 익히기에 적합함. |
Regular Expressions in Python: the re Module |
| 블로그 | re.match, re.search, re.findall 등의 차이점을 한눈에 비교.한국어로 정리된 예제 중심 설명. |
Python 정규표현식 정리 (note.nkmk.me) |
📎 Tip: 처음 배우는 학생이라면 Real Python 튜토리얼로 예제를 따라 해본 뒤, 공식 문서로 함수 세부 인자와 정규식 문법을 확인하는 것이 좋다.
예제 코드
import re # re는 Regular Expression(정규표현식) 모듈이다.
text = "Data-Science!! is, Exciting??? "
# 1️⃣ 모든 문자를 소문자로 변환
text = text.lower()
# 2️⃣ 알파벳과 공백만 남기기
# [^a-z\\s] → 알파벳(a~z)과 공백(\\s)을 제외한 나머지를 모두 찾아 공백으로 치환
text = re.sub(r'[^a-z\s]', ' ', text)
# 3️⃣ 여러 개의 공백을 하나로 줄이고, 양쪽 공백 제거
# \\s+ → 공백 문자(스페이스, 탭, 줄바꿈 등)가 하나 이상 연속될 때
text = re.sub(r'\s+', ' ', text).strip()
print(text)
실행 결과
datascience is exciting
불용어 제거 (Stopword Removal)
불용어(stopwords) 는 텍스트에 자주 등장하지만 분석 목적에 큰 기여를 하지 않는 단어를 말한다.
하지만 “의미가 없다”기보다는, 해당 과제(task) 에서 구분력을 떨어뜨리거나 노이즈가 되는 경향이 있어서 제거하는 것이다.
예: 영어의 the, is, and, 한국어의 조사/어미 은, 는, 이, 가, 을, 를, 에, 와, 과 등이 해당된다.
핵심: 불용어는 절대적 목록이 아니라 ‘과제·도메인 의존적’이다.
감성 분석, 주제 분류, 요약 등 목적에 따라 제거하거나 보존해야 한다.
불용어를 제거하는 이유
-
자주 등장하지만 정보량이 적은 단어를 줄여서 모델이 중요한 단어에 집중하게 한다.
-
단어 수를 줄여 연산 속도와 메모리 효율을 높인다.
-
빈도 기반 지표(예: TF, TF-IDF)의 단어 가중치 계산 품질을 향상시킨다.
제거하지 말아야 하는 단어
-
부정어/부사:
not, no, never, 없다, 않다, 못하다같은 단어는 감성 분석에서 결정적 의미를 가진다. 예를 들어“좋다”와“좋지 않다”는 정반대이므로 ‘않다’를 제거하면 분석이 왜곡된다. -
지시어나 의문사: 검색, QA 시스템에서는
what, where, how / 이것, 저것, 여기같은 단어가 핵심 역할을 한다. -
짧은 문장: SNS나 댓글처럼 문장이 짧을 때는 불용어를 제거하면 전체 의미가 사라질 수 있다.
불용어 설계 가이드
| 단계 | 설명 |
|---|---|
| 1. 기본 리스트 사용 | 영어: nltk.corpus.stopwords.words('english')한국어: KoNLPy 형태소 분석 후 조사(Josa), 어미(Eomi) 제거 |
| 2. 화이트리스트 정의 | 부정어·강조어(예: not, 없다, 않다)는 제거하지 않는다 |
| 3. 빈도 기반 제거 | 문서의 \(x\)% 이상 등장하는 단어(max_df), 너무 희귀한 단어(min_df)는 제거 |
| 4. 지속적 업데이트 | 분석 결과를 검토해 커스텀 불용어 목록을 보완한다 |
영어 불용어 제거 예제
예제 코드는 다음과 같은 순서를 걸쳐 불용어 처리를 수행한다.
-
기본 불용어 리스트(
base_sw)를 불러온다. -
부정어(
whitelist)는 제외하여 보존한다. -
isalpha()로 기호를 제거하고 단어만 남긴다.
# ================================
# 🧩 영어 불용어 제거 예제
# ================================
# 1️⃣ NLTK 라이브러리 불러오기
# NLTK(Natural Language Toolkit)는 자연어처리용 파이썬 대표 라이브러리다.
# 단어 토큰화, 불용어 제거, 형태 분석 등에 자주 사용된다.
import nltk
from nltk.corpus import stopwords
# 2️⃣ NLTK의 'stopwords' 데이터 다운로드
# 한 번만 다운로드하면 이후에는 자동으로 캐시된 데이터를 사용한다.
nltk.download('stopwords')
# 3️⃣ 예시 문장 설정
text = "This is not only a simple example, but also a very useful one."
# 4️⃣ 모든 단어를 소문자로 변환하고 공백 기준으로 나눈다.
# 대소문자를 통일하면 같은 의미의 단어를 하나로 처리할 수 있다.
tokens = [w.lower() for w in text.split()]
# 5️⃣ NLTK 내장 영어 불용어 목록 불러오기
# stopwords.words('english')는 약 180개 일반 불용어를 포함한다.
base_sw = set(stopwords.words('english'))
# 6️⃣ 화이트리스트(whitelist) 정의
# 부정어(not, no, never)는 의미가 매우 중요하므로 삭제 대상에서 제외한다.
whitelist = {"not", "no", "never"}
# 7️⃣ 실제로 제거할 불용어 집합 정의
# 기본 불용어 목록에서 화이트리스트 단어를 뺀다.
stop_set = base_sw - whitelist
# 8️⃣ 토큰 중에서
# - 알파벳으로만 이루어진 단어(`isalpha()` 조건)
# - 불용어 목록에 없는 단어
# 만 남긴다.
# 리스트 컴프리헨션을 사용하는 경우
# filtered = [w for w in filtered_by_pos if w not in custom_sw]
# for문을 사용하는 경우
filtered = []
for token in tokens:
# 1) 알파벳인지 확인
if not token.isalpha():
continue
# 2) 불용어인지 확인
if token in stop_set:
continue
filtered.append(token)
# 9️⃣ 결과 출력
print(filtered)
# 출력 결과: ['not', 'simple', 'example', 'also', 'useful', 'one']
# 설명:
# - "is", "a", "but" 등 자주 등장하지만 의미가 약한 단어는 제거된다.
# - "not"은 부정 의미를 지니므로 제거되지 않는다.
# - 최종적으로 문장에서 중요한 의미 단어만 남게 되어,
# 이후 분석(예: TF-IDF, 감성 분석 등)의 품질이 높아진다.
실행 결과
['not', 'simple', 'example', 'also', 'useful', 'one']
한국어 불용어 제거 예제 (KoNLPy)
# ================================
# 🇰🇷 한국어 불용어 제거 예제 (KoNLPy + 품사 기반)
# ================================
# 1️⃣ KoNLPy의 Okt 형태소 분석기 불러오기
# KoNLPy는 한국어 자연어처리를 위한 파이썬 패키지다.
# Okt(Open Korean Text)는 SNS나 일상 문장에 강한 분석기로,
# 명사, 동사, 형용사, 조사 등을 구분해준다.
from konlpy.tag import Okt
# 2️⃣ 형태소 분석기 객체 생성
okt = Okt()
# 3️⃣ 분석할 문장 예시
text = "이 정책은 결코 쉬운 결정이 아니지만, 국민의 안전을 위해 반드시 필요하다."
# 4️⃣ 형태소 분석 수행
# norm=True → '아니지만' 같은 문장을 기본형으로 정규화 ("아니지만" → "아니다")
# stem=True → 어간 추출, 예: "필요하다" → "필요"
pos = okt.pos(text, norm=True, stem=True)
# 형태소 분석 결과 예시:
# [('이', 'Determiner'), ('정책', 'Noun'), ('은', 'Josa'), ('결코', 'Adverb'),
# ('쉽다', 'Adjective'), ('결정', 'Noun'), ('이', 'Josa'), ('아니다', 'Adjective'),
# ('지만', 'Eomi'), ('국민', 'Noun'), ('의', 'Josa'), ('안전', 'Noun'),
# ('을', 'Josa'), ('위해', 'PreEomi'), ('반드시', 'Adverb'), ('필요', 'Noun'),
# ('하다', 'Verb'), ('.', 'Punctuation')]
# 5️⃣ 조사(Josa), 어미(Eomi), 구두점(Punctuation) 제거
# 조사(은, 는, 이, 가, 을, 를), 어미(다, 지만 등)는 문법적 역할만 하므로 제거 대상이다.
ban_pos = {'Josa', 'Eomi', 'Punctuation'}
filtered_by_pos = [w for w, p in pos if p not in ban_pos]
# 6️⃣ 도메인(분석 목적)에 맞게 커스텀 불용어 정의
# 예: 정책 분야 텍스트에서는 "정책", "위해" 같은 단어는 너무 빈번하므로 제거
custom_sw = {'것', '수', '정책', '위해'}
# 리스트 컴프리헨션을 사용하는 경우
# filtered = [w for w in filtered_by_pos if w not in custom_sw]
# for문을 사용하는 경우
filtered = []
for token in tokens:
# 1) 알파벳인지 확인
if not token.isalpha():
continue
# 2) 불용어인지 확인
if token in stop_set:
continue
filtered.append(token)
# 7️⃣ 최종 결과 출력
print(filtered)
# 설명:
# - 형태소 분석을 통해 단어의 품사 정보를 얻는다.
# - 문법적 기능어(조사·어미)는 제거하고, 핵심 의미어(명사·형용사·부사 등)만 남긴다.
# - 불용어 목록은 과제에 맞게 조정하며, 반복 등장하지만 의미가 약한 단어를 제거한다.
# - 결과적으로 문장에서 ‘의미 중심 단어’만 남아, 분석 효율과 정확도가 향상된다.
실행 결과
['결코', '쉽다', '결정', '아니다', '국민', '안전', '반드시', '필요']
-
조사(Josa), 어미(Eomi), 구두점(Punctuation)을 제거
-
norm=True, stem=True옵션으로 표기를 통일 -
custom_sw로 도메인에 맞는 불용어를 추가
어간 추출 (Stemming) / 표제어 추출 (Lemmatization)
어간 추출(Stemming)과 표제어 추출(Lemmatization)은 단어의 다양한 변형 형태를 하나의 공통된 형태로 통일하는 과정이다.
이 과정을 통해 모델이 “형태는 달라도 의미가 같은 단어”를 하나로 인식하게 된다.
어간 (Stem)
-
단어의 기본 형태 중에서 변하지 않는 핵심 부분을 의미한다.
-
동사의 시제, 명사의 복수형 등은 변할 수 있지만, 어간은 단어의 뿌리 역할을 한다.
-
즉, 단어 변화의 공통된 부분으로 의미를 유지하는 최소 단위이다.
원형 단어 변형된 형태 공통 어간 play playing, played, plays play study studying, studied, studies studi move moving, moved, moves mov
어간(Stemming) 추출
-
단어의 어미나 접사(suffix/prefix)를 단순 규칙에 따라 잘라내는 방법이다.
-
문법적 정확성보다는 단순히 형태를 통일하는 데 초점을 둔다.
-
예를 들어, studying, studies, studied → studi 로 단순히 자른다.
표제어 (Lemma)
-
표제어는 사전(dictionary)에 등록된 단어의 기본형이다.
-
단어의 품사(POS)와 문법 규칙을 고려하여 의미적으로 올바른 기본 형태로 변환한다.
-
예를 들어, “better”는 어간 추출로는 그대로 남지만, 표제어 추출에서는 “good”으로 바뀐다.
단어 표제어(Lemma) 품사 running run 동사(verb) studies study 동사(verb) better good 형용사(adj) was be 동사(verb)
요약 비교
| 구분 | 어간 추출 (Stemming) | 표제어 추출 (Lemmatization) |
|---|---|---|
| 정의 | 단순히 단어의 어미를 자르고 통일 | 사전과 품사 정보를 이용해 의미적으로 정확한 기본형 변환 |
| 예시 | studying → studi |
studying → study |
| 결과 형태 | 실제 단어가 아닐 수 있다 | 실제 존재하는 단어 |
| 처리 속도 | 빠르다 | 느리지만 정확하다 |
| 사용 목적 | 단순 검색, 키워드 중심 분석 | 문법적·의미적 분석이 필요한 작업 |
영문 실습 코드 (Python NLTK)
from nltk.stem import PorterStemmer, WordNetLemmatizer
from nltk.corpus import wordnet
import nltk
nltk.download('wordnet')
# 어간 추출기 (Stemming)
stemmer = PorterStemmer()
# 표제어 추출기 (Lemmatization)
lemmatizer = WordNetLemmatizer()
words = ["studies", "studying", "studied", "better", "running"]
print("단어\t어간추출\t표제어추출")
for w in words:
stem = stemmer.stem(w)
lemma = lemmatizer.lemmatize(w, pos=wordnet.VERB) # 동사 기준으로 변환
print(f"{w}\t{stem}\t{lemma}")
실행 결과
단어 어간추출 표제어추출
studies studi study
studying studi study
studied studi study
better better good
running runn run
한국어에서 어간 및 표제어 추출을 하지 않는 이유
1️⃣ 형태가 복잡하고, 규칙이 단순하지 않다
영어는 run → running, study → studying처럼 접사 규칙이 단순하지만, 한국어는 어미 변화와 조사 결합이 매우 다양하다.
| 원형 | 변형된 형태 |
|---|---|
| 가다 | 갑니다, 가요, 가고, 갔지만, 가니까, 가려면 |
| 하다 | 합니다, 해요, 했지만, 하는, 하려고, 하겠다고 |
형태 변형이 수십 가지이기 때문에 단순 규칙 기반의 “어간 추출”은 현실적으로 어렵고, 의미 손실이 쉽게 발생한다.
2️⃣ 대신 “형태소 분석(Morphological Analysis)”을 사용한다
한국어에서는 단순히 어미를 자르는 것보다, 문장을 형태소 단위로 나누고 각 형태소의 품사(POS)를 분석하는 접근이 훨씬 정확하다.
POS(Part-of-Speech)는 품사 태깅(Pos tagging) 을 의미한다. 즉 형태소 분석 결과에서 각 단어(또는 형태소)가 어떤 품사인지를 알려주는 정보이다.
예를 들어 다음과 같은 문장을 분석하려는 경우,
“가고 싶지만 가지 못했다”
형태소 분석을 하면 다음과 같이 나온다.
[('가', 'Verb'), ('고', 'Eomi'), ('싶', 'Verb'),
('지만', 'Eomi'), ('가', 'Verb'), ('지', 'Eomi'),
('못하', 'Verb'), ('었', 'Eomi'), ('다', 'Eomi')]
3️⃣ KoNLPy 분석기들이 이미 “어간화” 옵션을 제공한다
예를 들어 Okt.pos(text, stem=True) 옵션을 쓰면 자동으로 필요하다 → 필요, 먹었다 → 먹다, 한다 → 하다로 변환된다.
즉, 영어의 Lemmatizer처럼 별도의 단계가 아니라, 형태소 분석 단계에서 이미 표제어(lemma) 처리가 함께 수행된다.
4️⃣ 실제 연구·실무에서는 형태소 기반 처리로 충분하다
한국어 NLP에서는 보통 다음 단계로 진행된다
-
형태소 분석 (Morphological Analysis) → 품사 정보까지 포함한 토큰화
-
불용어 제거 + 품사 선택 (예: 명사, 동사만 사용)
-
임베딩/모델 입력 (Word2Vec, BERT 등)
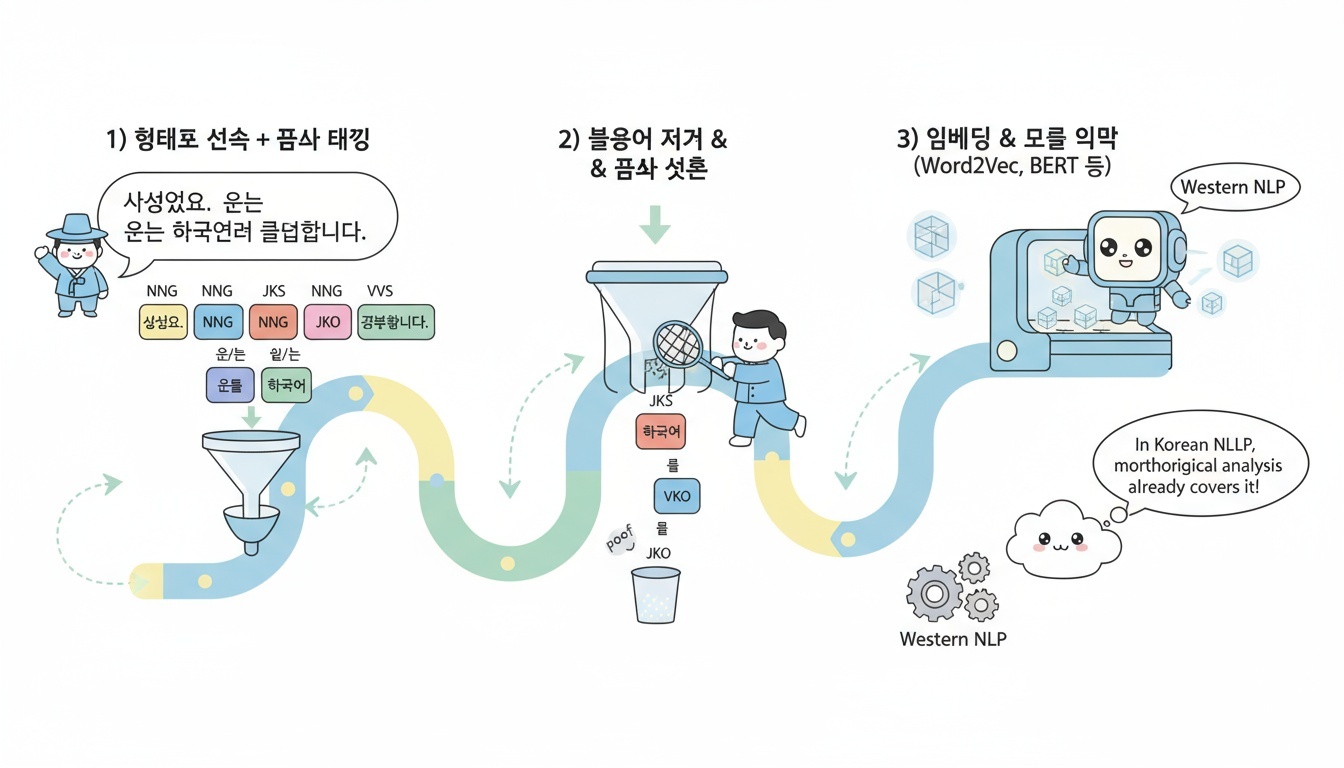
이 흐름 속에서는 한국어 처리에서는 “Stemming”과 “Lemmatization”을 별도 단계로 두지 않는다.
영어와 한국어 비교
| 항목 | 영어 | 한국어 |
|---|---|---|
| 어간 추출 | 규칙 기반 접사 제거 | 형태소 분석으로 대체 |
| 표제어 추출 | 사전 기반 의미 변환 | 형태소 분석 시 자동 처리됨 (stem=True) |
| 주 사용 도구 | PorterStemmer, WordNetLemmatizer |
KoNLPy(Okt, Komoran, Mecab) |
| 필요성 | 매우 높음 | 낮음 (대부분 형태소 분석으로 해결) |
단어 빈도 분석
토큰화가 끝난 후에는 각 단어가 몇 번 등장했는지를 계산할 수 있다.
문서 내에서 어떤 단어가 자주 등장하는지를 계산하여, 그 문서의 주요 주제나 핵심 키워드를 빠르게 파악할 수 있다. 이 과정을 단어 빈도 분석(word frequency analysis) 이라고 한다.
예를 들어, 뉴스 기사나 대통령 연설문을 분석한다면,
‘경제’, ‘국민’, ‘정책’, ‘안전’ 같은 단어가 자주 등장할 수 있다.
이런 단어는 해당 문서의 핵심 관심사를 보여준다.

실습 코드
from collections import Counter
import matplotlib.pyplot as plt
# 예시 단어 리스트
words = ['data', 'science', 'data', 'machine', 'learning', 'data']
# 각 단어의 등장 횟수를 세기
counter = Counter(words)
# 상위 3개 단어 출력
print(counter.most_common(3))
# Counter 결과를 이용한 시각화
labels, values = zip(*counter.most_common(5))
plt.bar(labels, values)
plt.title("Top 5 Word Frequencies")
plt.xlabel("Words")
plt.ylabel("Count")
plt.show()
실행 결과
[('data', 3), ('science', 1), ('machine', 1)]
대통령 연설문 단어 빈도 분석
-
대통령기록관: https://www.pa.go.kr/research/contents/speech/index.jsp
-
샘플 데이터 다운로드: 제103주년 3·1절 기념사
실습 코드
# Okt 실행을 위해서는
# jdk 가 설치되어 있어야 함.
# 의존성 설치 - 윈도우는 지원 안됨 ㅠ
pip install python-mecab-ko
# ==========================================
# 🇰🇷 대통령 연설문 단어 빈도 분석 및 시각화
# ==========================================
from konlpy.tag import Okt, Mecab
from collections import Counter
import re
import matplotlib.pyplot as plt
# 한글 폰트 설정 (윈도우 기준)
plt.rcParams['font.family'] = 'Malgun Gothic' # 한글 기본 폰트
plt.rcParams['axes.unicode_minus'] = False
# 1) 형태소 분석기 준비
# - Okt(Open Korean Text)는 한국어 형태소 분석기 중 하나로,
# SNS/연설문 같은 자연스러운 문체에서 좋은 성능을 보인다.
okt = Okt()
# 2) 연설문 불러오기
# - speech.txt 파일에 대통령 연설문 전문이 저장되어 있다고 가정한다.
# - UTF-8 인코딩을 사용 (윈도우에서 인코딩 오류가 날 경우 'cp949'로 변경 가능)
with open("president_speech.txt", encoding="utf-8") as f:
text = f.read()
# 3) 정규화: 한글과 공백만 남기기
# - [^가-힣\s] : 한글(가~힣)과 공백(\s)을 제외한 모든 문자를 찾아 공백으로 대체
# - 여러 공백을 하나로 줄이고, 문장 앞뒤 공백을 제거한다.
text = re.sub(r"[^가-힣\s]", " ", text)
text = re.sub(r"\s+", " ", text).strip()
# 4) 형태소 분석 & 명사 추출
# - okt.nouns()는 문장에서 명사만 추출해 리스트 형태로 반환한다.
tokens = okt.nouns(text)
# 5) 1글자 명사 제거
# - 조사·단음절 등 의미가 약한 단어 제거
tokens = [w for w in tokens if len(w) > 1]
# 6) 불용어 정의
# - 문서 분석 목적상 불필요하거나 너무 일반적인 단어를 제외한다.
# - 필요에 따라 도메인별로 불용어를 추가/삭제할 수 있다.
stopwords = {"국민", "정부", "대한민국", "대통령", "우리", "것", "수"}
# 7) 불용어 제거
filtered = [w for w in tokens if w not in stopwords]
# 8) 단어 빈도 계산
# - Counter는 각 단어의 등장 횟수를 세어 딕셔너리 형태로 반환한다.
counter = Counter(filtered)
# 9) 상위 10개 단어 추출
top10 = counter.most_common(10)
# 10) 결과 출력
print("상위 10개 명사:", top10)
# ------------------------------------------
# 11) 시각화: 막대 그래프
# ------------------------------------------
# Counter 결과를 (단어, 빈도) 형태로 분리
labels, values = zip(*top10)
# 그래프 크기 설정
plt.figure(figsize=(8, 5))
# 막대그래프 그리기
plt.bar(labels, values, color="skyblue")
# 그래프 제목과 축 라벨
plt.title("대통령 연설문 Top 10 단어 빈도", fontsize=14)
plt.xlabel("단어", fontsize=12)
plt.ylabel("빈도수", fontsize=12)
# x축 글자 겹침 방지
plt.xticks(rotation=45)
# 그래프 여백 조정
plt.tight_layout()
# 그래프 출력
plt.show()
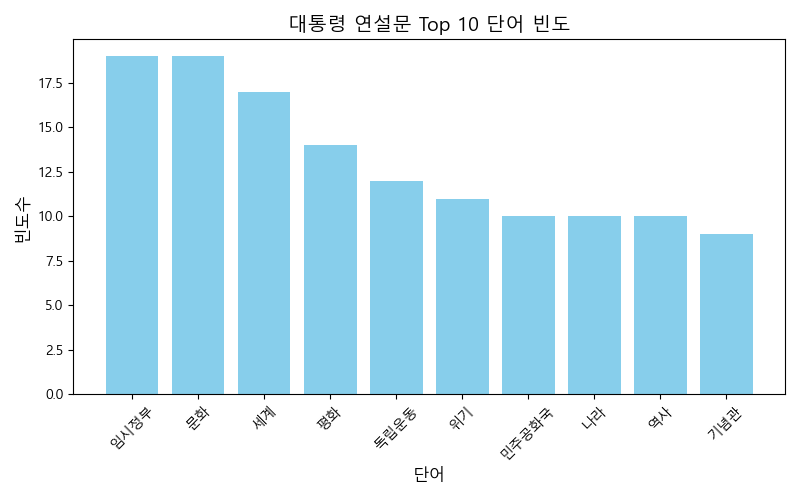
실행 결과
상위 10개 명사: [ ('임시정부', 19), ('문화', 19), ('세계', 17),
('평화', 14), ('독립운동', 12), ('위기', 11),
('민주공화국', 10), ('나라', 10), ('역사', 10),
('기념관', 9) ]
감성 분석 (Sentiment Analysis)
감성 분석은 텍스트(문장, 리뷰, 트윗 등)에 담긴 사람의 감정이나 의견을 자동으로 파악하는 기술이다. 쉽게 말하면, 컴퓨터가 문장을 읽고 긍정적인지(Positive), 부정적인지(Negative), 혹은 중립적인지(Neutral) 를 구분하는 작업이다.
“I really love this movie. It was fantastic!” → 긍정적 감정 (Positive)
“This movie was boring and too long.” → 부정적 감정 (Negative)
텍스트 데이터 분석에서의 역할
-
의견 요약 및 분류
-
수많은 고객 리뷰나 SNS 댓글을 자동으로 요약하거나 긍·부정 비율로 시각화할 수 있다.
-
예: 기업은 제품 리뷰 중 “불만”이 많은 부분을 자동으로 파악해 개선 가능.
-
-
의사결정 지원
- 마케팅, 여론 분석, 정치, 주식 시장 등 다양한 분야에서 대중의 정서를 수치화하여 데이터 기반 의사결정
-
자연어 처리(NLP) 파이프라인의 핵심 단계
- 토큰화(tokenization), 품사 태깅(pos tagging), 감정 분류(classification) 등 텍스트 분석 과정에서 핵심적인 응용 단계로 사용
TextBlob을 이용한 간단한 감성분석
TextBlob은 텍스트 데이터를 처리하기 위한 파이썬 라이브러리이다.
자연어 처리(NLP)에서 자주 수행되는 작업들을 간단하게 수행할 수 있도록 하는 직관적인 API를 제공한다.
-
품사 태깅(Part-of-Speech Tagging)
-
명사구 추출(Noun Phrase Extraction)
-
감성 분석(Sentiment Analysis)
-
문서 분류(Classification)
-
번역(Translation) 등
pip install textblob
from textblob import TextBlob
texts = [
"The service was very unfriendly. I will never use it again.",
"서비스가 너무 불친절했어요. 다시는 이용 안 할 거예요.",
"I had a really satisfying experience and I recommend it!",
"정말 만족스러운 경험이었고 추천합니다!",
"It was decent for the price.",
"가격 대비 괜찮았어요.",
]
for text in texts:
blob = TextBlob(text)
decision = "positive" if blob.sentiment.polarity > 0 else "negative" if blob.sentiment.polarity < 0 else "neutral"
print(f'\n문장: {text}')
print(f' → 긍부정 판단: {decision} (감정 점수: {blob.sentiment.polarity * 100:.1f}%)')
print(f" → 주관성 점수: {blob.sentiment.subjectivity*100:.1f}%\n")
출력
문장: The service was very unfriendly. I will never use it again.
→ 긍부정 판단: positive (감정 점수: 20.0%)
→ 주관성 점수: 30.0%
문장: 서비스가 너무 불친절했어요. 다시는 이용 안 할 거예요.
→ 긍부정 판단: neutral (감정 점수: 0.0%)
→ 주관성 점수: 0.0%
문장: I had a really satisfying experience and I recommend it!
→ 긍부정 판단: positive (감정 점수: 62.5%)
→ 주관성 점수: 100.0%
문장: 정말 만족스러운 경험이었고 추천합니다!
→ 긍부정 판단: neutral (감정 점수: 0.0%)
→ 주관성 점수: 0.0%
문장: It was decent for the price.
→ 긍부정 판단: positive (감정 점수: 16.7%)
→ 주관성 점수: 66.7%
문장: 가격 대비 괜찮았어요.
→ 긍부정 판단: neutral (감정 점수: 0.0%)
→ 주관성 점수: 0.0%
결과 해석
| 항목 | 의미 | 값의 범위 | 예시 |
|---|---|---|---|
| polarity | 문장의 긍·부정 정도 | -1.0 ~ +1.0 | +1.0 → 매우 긍정 -1.0 → 매우 부정 |
| subjectivity | 문장의 주관적 표현 정도 | 0.0 ~ 1.0 | 1.0 → 매우 주관적 0.0 → 객관적 진술 |
딥러닝 모델을 이용한 감성 분석
BERT 소개
BERT (Bidirectional Encoder Representations from Transformers)는 Google이 2018년에 발표한 언어 모델로, 문맥을 양방향(앞뒤 문장 모두)으로 이해하는 Transformer 기반 구조를 사용한다.
문장의 의미나 어휘 간 관계를 깊이 파악할 수 있으며, 문장 분류·질의응답·감성 분석 등 다양한 NLP 작업에서 높은 성능을 보인다.
Roberta 소개
RoBERTa는 2019년 Facebook AI(현재 Meta AI)가 발표한 BERT 모델의 개선 버전이다. 이름의 뜻은 “Robustly Optimized BERT Approach”, 즉 “더 강력하게 최적화된 BERT 방식”이라는 의미를 가지고 있다.
BERT가 처음 등장했을 때 NLP 분야를 혁신시켰지만, RoBERTa는 학습 데이터, 학습 방법, 하이퍼파라미터를 개선해서 BERT보다 더 강력한 언어 이해 성능을 달성했다.
-
사용할 모델:
cardiffnlp/twitter-xlm-roberta-base-sentiment -
Hugging Face: Click me
실습 코드
-
Pytorch등 필요한 패키지 설치- 참고: 파이토치 설치 사이트
pip install torch transformers sentencepiece protobuf
from transformers import pipeline
MODEL = "cardiffnlp/twitter-xlm-roberta-base-sentiment"
nlp = pipeline(
"text-classification",
model=MODEL,
tokenizer=MODEL,
device=-1, # CPU. GPU 쓰면 device_map="auto"
return_all_scores=False
)
texts = [
"The service was very unfriendly. I will never use it again.",
"서비스가 너무 불친절했어요. 다시는 이용 안 할 거예요.",
"I had a really satisfying experience and I recommend it!",
"정말 만족스러운 경험이었고 추천합니다!",
"It was decent for the price.",
"가격 대비 괜찮았어요.",
]
for text in texts:
out = nlp(text, truncation=True, max_length=128)[0]
print(f"\n문장: {text}")
print(f" → 긍부정 판단: {out['label']} (확률: {out['score'] * 100:.1f}%)\n")
출력
문장: The service was very unfriendly. I will never use it again.
→ 긍부정 판단: negative (확률: 94.5%)
문장: 서비스가 너무 불친절했어요. 다시는 이용 안 할 거예요.
→ 긍부정 판단: negative (확률: 92.6%)
문장: I had a really satisfying experience and I recommend it!
→ 긍부정 판단: positive (확률: 93.8%)
문장: 정말 만족스러운 경험이었고 추천합니다!
→ 긍부정 판단: positive (확률: 92.1%)
문장: It was decent for the price.
→ 긍부정 판단: positive (확률: 79.4%)
문장: 가격 대비 괜찮았어요.
→ 긍부정 판단: positive (확률: 66.1%)
문장별 비교 해석 (Korean + English)
| # | 문장 (KO/EN) | TextBlob | RoBERTa | 해석 & 원인 |
|---|---|---|---|---|
| 1 | EN: The service was very unfriendly. I will never use it again. | positive 20%, subj 30% | negative 94.5% | 실제론 강한 부정. TextBlob은 unfriendly의 부정 강도를 약하게 잡고, “never use it again”의 문맥적 분노/단호함을 반영 못함. RoBERTa는 문맥을 반영해 정확히 부정. |
| 2 | KO: 서비스가 너무 불친절했어요. 다시는 이용 안 할 거예요. | neutral 0%, subj 0% | negative 92.6% | TextBlob은 한국어 미지원 → 전부 0으로 수렴. RoBERTa는 한국어 문맥 인식으로 강한 부정. |
| 3 | EN: I had a really satisfying experience and I recommend it! | positive 62.5%, subj 100% | positive 93.8% | 둘 다 긍정. RoBERTa가 “recommend” 같은 강한 추천 어조까지 반영 → 더 높은 확률. |
| 4 | KO: 정말 만족스러운 경험이었고 추천합니다! | neutral 0%, subj 0% | positive 92.1% | TextBlob은 한국어 처리 불가. RoBERTa는 강한 긍정으로 정확 분류. |
| 5 | EN: It was decent for the price. | positive 16.7%, subj 66.7% | positive 79.4% | 미묘한 온건 긍정. TextBlob은 decent을 약긍정으로만 반영. RoBERTa는 “for the price” 가성비 맥락까지 읽어 더 높은 긍정. |
| 6 | KO: 가격 대비 괜찮았어요. | neutral 0%, subj 0% | positive 66.1% | TextBlob은 한국어 0. RoBERTa는 가성비 긍정 맥락을 반영해 중간 이상의 긍정. |
| 구분 | TextBlob | RoBERTa |
|---|---|---|
| 언어 지원 (Language) | 영어 전용 (English only) | 다국어, 한국어 포함 (Multilingual, including Korean) |
| 문맥 이해 (Context Awareness) | 낮음 (Low) | 높음 (High) |
| 감정 강도 표현 (Sentiment Strength) | 단순/약함 (Weak/Average) | 확률 기반, 명확함 (Probability-based, Precise) |
| 한국어 감정 분석 정확도 | ❌ 매우 낮음 | ✅ 매우 높음 |
워드클라우드 시각화 (Word Cloud)
워드클라우드는 텍스트 데이터에서 단어의 등장 빈도를 시각적으로 표현하는 방법이다. 단어의 크기, 굵기, 색상 등을 이용하여 등장 빈도가 높은 단어일수록 강조되게 표현한다. 이를 통해 긴 문서의 핵심 주제나 주요 키워드를 한눈에 파악할 수 있다.
워드클라우드를 사용하는 이유
워드클라우드는 데이터 분석 과정에서 다음과 같은 이유로 많이 활용된다.
-
요약 효과: 대량의 텍스트를 읽지 않아도 주요 단어를 직관적으로 확인할 수 있다.
-
탐색적 분석(EDA): 본격적인 분석 이전에 데이터의 전반적 특징을 파악하는 데 유용하다.
-
커뮤니케이션: 분석 결과를 시각적으로 전달하여 비전문가도 쉽게 이해할 수 있도록 돕는다.
-
전처리 점검: 불용어 제거와 형태소 분석이 잘 되었는지 시각적으로 확인할 수 있다.
장점과 한계
워드클라우드는 시각적으로 아름답고 직관적이지만, 문맥이나 부정 표현(예: “좋지 않다”)을 반영하기 어렵다는 한계가 있다. 따라서 정밀 분석보다는 탐색적 시각화나 발표용 요약에 적합하다.
사용 도구
- Python:
wordcloud,matplotlib,konlpy를 조합하여 사용 - R:
wordcloud,tm,tidytext패키지 - 시각화 툴:
Tableau,Power BI,Flourish등 - 웹 도구:
Voyant Tools,D3.js,ECharts
한국어 분석 시 주의사항
한국어는 조사가 많고 어미 변형이 다양하기 때문에 형태소 분석을 반드시 수행해야 한다. 주로 KoNLPy의 Okt나 Mecab 형태소 분석기를 이용하며, 의미 없는 조사나 접속사는 불용어로 제거한다.
예를 들어 “배송이 빠르고 포장이 깔끔했다”라는 문장에서 ‘배송’, ‘포장’ 같은 명사를 중심으로 추출해야 한다.
파이썬 예시 코드
wordcloud패키지 설치
pip install wordcloud
-
운영체제별 한글 폰트 위치
-
Windows :
C:/Windows/Fonts/malgun.ttf (맑은 고딕) -
macOS :
/Library/Fonts/AppleGothic.ttf (애플고딕) -
Linux/Colab :
/usr/share/fonts/truetype/nanum/NanumGothic.ttf (나눔고딕) -
만약 운영체제에 한글 폰트가 없다면 수동으로 다운로드 받아서 해당 위치에 넣어야 함
폰트 이름 라이선스 특징 다운로드 링크 나눔고딕
(Nanum Gothic)무료 (NAVER OFL) 깔끔하고 가독성이 좋아
워드클라우드나 웹 프로젝트에 자주 사용NAVER 카페24 써라운드
(Cafe24 Surround)무료
상업적 사용 가능귀엽고 부드러운 곡선체
감성적인 디자인에 적합카페24 배민 도현체
(BME DoHyeon)무료
상업적 사용 가능굵고 임팩트 있는 제목용 폰트 배민 -
-
실습 파일 다운로드: 대통령 연설문 제 84주년 3·1절 기념사
# ============================================
# 🎆 워드클라우드 실습: 명사 기반 시각화
# ============================================
from konlpy.tag import Okt
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 1️⃣ 텍스트 파일 읽기
# UTF-8 인코딩으로 한글 깨짐 방지
with open("independent_day.txt", "r", encoding="utf-8") as f:
text = f.read()
# 2️⃣ 형태소 분석기 초기화 (Okt)
# Okt는 한국어 문장에서 명사, 동사, 형용사 등을 구분해줌
okt = Okt()
# 3️⃣ 명사만 추출
# 예: ["독립", "기념일", "국가", "대한민국", ...]
nouns = okt.nouns(text)
# 4️⃣ 불용어(Stopwords) 제거
# 분석 목적과 상관없는 조사, 접속사 등은 제거
stopwords = ["것", "수", "등", "들", "그", "그리고", "이", "저", "제", "우리", "대한"]
filtered_nouns = [word for word in nouns if word not in stopwords and len(word) > 1]
# 5️⃣ 워드클라우드를 위한 문자열 결합
text_for_wc = " ".join(filtered_nouns)
# 6️⃣ 한글 폰트 경로 설정 (운영체제별 경로 예시)
# Windows: C:/Windows/Fonts/malgun.ttf
# macOS: /System/Library/Fonts/AppleGothic.ttf
# Linux/Colab: /usr/share/fonts/truetype/nanum/NanumGothic.ttf
font_path = "C:/Windows/Fonts/malgun.ttf"
# 7️⃣ 워드클라우드 생성
# ============================================
# WordCloud 파라미터 사용 가이드
# --------------------------------------------
# font_path : 워드클라우드에서 사용할 폰트 파일 경로 (한글 필수)
# - 미설정 시 한글이 □□□로 깨짐
# - OS별 예시:
# Windows → "C:/Windows/Fonts/malgun.ttf" (맑은 고딕)
# macOS → "/System/Library/Fonts/AppleGothic.ttf" (애플고딕)
# Linux → "/usr/share/fonts/truetype/nanum/NanumGothic.ttf" (나눔고딕)
# - Colab에서는 다음으로 설치 가능:
# !apt-get install fonts-nanum -y && fc-cache -fv
#
# background_color : 배경색 (문자열/HEX)
# - 예: "white", "black", "#f5f5f5"
# - 발표/리포트용은 보통 "white" 선호
#
# width, height : 출력 이미지 해상도(픽셀)
# - 넓을수록 글자 디테일이 좋아짐(파일 저장에 유리)
# - 예: width=1200, height=800
#
# max_words : 표시할 최대 단어 수
# - 상위 빈도 단어 n개만 시각화
# - 너무 크게 잡으면 글자 겹침/가독성 저하 → 100~200 권장
#
# colormap : 색상 팔레트 (matplotlib colormap 이름)
# - 예: "tab10", "Set2", "viridis", "plasma", "coolwarm"
# - 참고: https://matplotlib.org/stable/users/explain/colors/colormaps.html
#
# prefer_horizontal : 수평 배치 비율(0~1)
# - 기본 0.9 (대부분 가로 배치)
# - 세로 단어가 많아도 되면 0.5 정도로 조정
#
# scale : 렌더링 스케일(배율)
# - 값↑ → 더 선명한 이미지(대신 속도/메모리 ↑)
# - 저장용 이미지는 scale=2~3 고려
#
# random_state : 난수 시드(재현성)
# - 동일 텍스트라 해도 시드가 같으면 배치/색상 패턴이 동일
# - 학습/보고서는 고정 권장(예: 42)
#
# mask : 마스킹 이미지(ndarray)
# - 특정 모양(로고/학과 엠블럼)으로 단어 배치
# - 예: mask = plt.imread("logo_mask.png")
#
# generate(text) / generate_from_frequencies(freq_dict)
# - text: 공백으로 구분된 단어 문자열
# - freq_dict: {"단어": 빈도, ...} 형태 (CountVectorizer, TF-IDF 등과 연계 편리)
# ============================================
wc = WordCloud(
font_path=font_path, # 한글 폰트 경로
background_color="white", # 배경색
width=800, # 이미지 가로 크기(px)
height=500, # 이미지 세로 크기(px)
max_words=150, # 최대 단어 수
colormap="tab10", # 색상 팔레트
prefer_horizontal=0.9, # 수평 배치 비율
scale=1.0, # 렌더링 스케일(선명도)
random_state=42 # 재현성(결과 고정)
# mask=mask # (선택) 마스킹 이미지 사용 시 주석 해제
).generate(text_for_wc) # 또는 .generate_from_frequencies(freq_dict)
# 8️⃣ 시각화
plt.figure(figsize=(10, 6))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.title("Word Cloud (Noun-based) - Independence Day Speech", fontsize=16)
plt.show()
실행 결과

Home Works
과제: 뉴스 텍스트 단어 빈도 시각화
-
분석 대상 기사:
news.txt파일에 제공된 「기후변화 대응을 위한 도시 녹지 확충」 관련 기사-
관련 기사 링크: https://www.newsis.com/view/NISX20250205_0003054569
-
텍스트 데이터 다운로드: news.txt
-
-
목표: 단어 전처리 → 빈도 분석 → 시각화(막대그래프/히스토그램 + 워드 클라우드) 파이프라인 구축하기
-
news.txt를 읽어 불필요한 공백과 특수문자를 정리하고, 형태소 분석을 통해 핵심 명사를 추출하세요. -
불용어 리스트를 정의하여 분석 목적과 무관한 단어를 제거하고, 단어별 빈도를 계산하세요.
-
상위 빈도 단어 20개 내외를 선택해 막대그래프 또는 히스토그램으로 시각화하고, 축 라벨과 제목을 명확히 표기하세요.
-
동일한 전처리 결과를 활용해 워드 클라우드를 생성하고, 시각화를 노트북에 포함하세요.
-
분석 과정, 코드, 결과 그래프를 모두 담은 Jupyter Notebook (
week09_homework.ipynb)과 생성한 이미지 파일을 제출하세요.
-
팁:
collections.Counter,matplotlib,seaborn,wordcloud등을 활용하면 일관된 워크플로를 구성할 수 있습니다. 노트북 상단에 사용한 불용어 리스트와 버전 정보를 기록해 주세요.
Solution
-
가능한 솔루션을 제공합니다. 가급적이면 솔루션 없이 구현해 볼 것을 추천합니다.
-
가능한 솔루션 1. 파이썬 스크립트: homework_solution.py
-
가능한 솔루션 2. 주피터 노트북 파일: homework_solution.ipynb
-