기초 통계
- 강의자료 다운로드: click me
학습목표
-
데이터 요약을 위한 기초 통계 개념 이해
-
평균, 분산 등 기초 통계량의 정의와 계산법 숙지
-
다양한 확률분포의 특징 파악
-
표본 추정 및 신뢰구간 개념 이해
주요 개념
-
평균(Mean), 중앙값(Median), 최빈값(Mode)
-
분산(Variance), 표준편차(Standard Deviation)
-
확률분포 (정규분포, 이항분포, 포아송분포 등)
-
추정(Estimation): 점추정과 구간추정
기술통계
데이터 분석의 첫걸음은 수집된 데이터를 이해하는 것이다. 수천 개의 행과 수십 개의 변수로 이루어진 데이터셋을 그대로 바라본다면 그 안에 담긴 특징을 파악하기 어렵다. 따라서 데이터를 요약해 대표적인 특성과 분포를 한눈에 보여주는 방법이 필요하다. 이를 기술통계(Descriptive Statistics)라고 부른다.
기술통계는 데이터를 전체적으로 요약하여 “평균적으로 어떠한지”, “흩어짐이 얼마나 되는지”, “중앙값은 얼마인지”와 같은 질문에 답할 수 있도록 도와준다. 데이터의 구조를 간단히 요약하는 데 목적이 있으며, 분석자가 데이터의 전반적인 성격을 이해하고 이후에 적절한 분석 기법을 선택하는 기초가 된다.
기술통계의 역할
기술통계는 데이터를 전체적으로 요약하여 다음과 같은 질문에 답할 수 있도록 돕는다.
-
평균적으로 이 데이터는 어떤 경향을 보여줄까? 평균
-
데이터는 얼마나 퍼져 있고, 흩어져 있을까? 표준편차
-
가장 흔하게 나타나는 값은 무엇일까? 최빈값
-
극단값(이상치)은 존재하는가? Outlier
즉, 기술통계는 데이터를 간단히 요약하는 데 목적이 있으며, 분석자가 데이터의 전반적인 성격을 이해하고 이후에 적절한 분석 기법을 선택하는 기초가 된다.
간단한 예제
예를 들어, 10명의 학생 시험 점수가 다음과 같다고 하자.
[72, 77, 77, 83, 88, 91, 95]
이 데이터를 요약하면:
-
평균: 약 83.3
-
중앙값: 83
-
표준편차: 약 9.5
-
최빈값: 최빈값은 77 (두 번 등장 → 가장 많이 등장)
이 요약을 통해 학생들의 성적이 80점대 초반에 몰려 있고, 흩어짐은 약 ±10점 수준이라는 사실을 직관적으로 알 수 있다.
중심 경향 (Measures of Central Tendency)
데이터의 전반적인 위치나 대표값을 나타내는 지표를 중심 경향이라 한다.
사람들이 중심 경향을 사용하는 이유는 다음과 같다.
-
복잡한 데이터 요약: 수많은 데이터 값을 하나의 대표값으로 단순화하여 전체 경향을 빠르게 이해할 수 있다.
-
비교 가능성 제공: 집단 간 차이를 평균이나 중앙값으로 비교함으로써 직관적이고 명확한 해석이 가능하다.
-
의사결정 지원: 기업의 매출, 학생들의 성적, 사회 조사 결과 등에서 중심값을 활용하면 정책 결정이나 전략 수립에 근거를 제공할 수 있다.
-
데이터 해석 기준: 분산, 표준편차 같은 다른 통계 지표들을 해석할 때 기준점 역할을 한다. 예를 들어, 평균을 중심으로 데이터가 얼마나 흩어져 있는지 파악할 수 있다.
평균(Mean)의 개념과 종류
평균은 데이터의 중심 경향을 설명하는 가장 기본적이고 널리 사용되는 통계량이다. 일반적으로 사람들이 ‘평균’이라고 말할 때는 산술평균(Arithmetic Mean)을 의미한다. 산술평균은 모든 값을 더한 후 데이터 개수로 나누어 계산하며, 전체 자료를 대표하는 값으로 활용된다.
예를 들어, 학생 5명의 시험 점수가 [70, 75, 80, 85, 90]일 때
산술평균은 (70 + 75 + 80 + 85 + 90) / 5 = 80 이다.
이처럼 산술평균은 계산이 간단하고 직관적이라는 장점이 있다.
하지만 한두 개의 극단값(outlier)에 크게 영향을 받아 전체 평균이 왜곡될 수 있다는 단점도 있다.
평균에는 산술평균 이외에도 여러 형태가 존재하며, 데이터의 특성이나 분석 목적에 따라 다른 평균을 선택할 수 있다.
산술평균 (Arithmetic Mean)
-
가장 기본적인 평균으로, 모든 값을 동일한 비중으로 더한 뒤 개수로 나눈 값
-
대부분의 데이터에서 기본적으로 사용되지만, 극단값에 민감함
가중평균 (Weighted Mean)
-
각 값에 중요도(가중치)를 곱해 평균을 계산
-
예: 시험 점수를 계산할 때 중간고사 40%, 기말고사 60%와 같은 가중치 적용
예시
한 학생의 점수가 다음과 같다고 하자.
-
중간고사: 80점 (가중치 40%)
-
기말고사: 90점 (가중치 60%)
가중평균은 다음과 같이 계산된다.
따라서 이 학생의 최종 점수는 86점으로 계산된다.
기하평균 (Geometric Mean)
-
n개의 값을 모두 곱한 뒤n제곱근을 취해 계산 -
주로 성장률이나 비율 데이터 분석에 사용
-
예: 투자 수익률이 매년
10%,20%,-5%일 때, 실제 투자 성과를 설명하는 데 적합
예를 들어, 어떤 투자금이 3년 동안 다음과 같은 수익률을 기록했다고 하자.
-
1년차: +10% →
1.1배 -
2년차: +20% →
1.2배 -
3년차: −5% →
0.95배
최종 (3년간) 성장 배율은 다음과 같이 계산할 수 있다.
즉, 3년 뒤에는 원금이 약 1.254배가 된다.
그렇다면 매년 일정한 성장률 \(r\)로 3년 동안 불어나서 1.254배가 되었다고 하면, 그 \(r\)은 기하평균으로 구할 수 있다.
해석
-
산술평균으로 계산하면 \((10\% + 20\% - 5\%)/3 \approx 8.3\%\)
-
기하평균으로 계산하면 실제 복리 효과를 반영한 \(7.8\%\)
-
실제 투자 결과를 설명하는 데는 기하평균이 더 정확하다.
따라서 기하평균은 "복리 개념의 평균 성장률"이라고 생각하면 직관적으로 이해할 수 있다.
조화평균 (Harmonic Mean)
데이터 값들의 역수\((\frac{1}{n})\) 의 평균을 구한 뒤, 다시 역수를 취한 값이다.
주로 속도, 비율, 단위당 데이터 분석에 적합
-
산술평균과의 차이점
-
산술평균은 "그냥 더해서 나눈 값" → 큰 값에 민감
-
조화평균은 "역수의 평균" → 작은 값에 민감
-
따라서 속도, 비율, 단위당 성능처럼 분모가 중요한 상황에서 필요하다.
-
직관적인 예시 1 (평균 속도)
-
서울 → 부산(200km): \(100 \,\text{km/h}\)
-
부산 → 서울(200km): \(50 \,\text{km/h}\)
산술평균은 다음과 같다.
하지만 실제 평균 속도는 전체 거리 ÷ 전체 시간으로 계산해야 한다.
-
총 거리 = \(400 \,\text{km}\)
-
총 시간 = \(200/100 + 200/50 = 2 + 4 = 6 \,\text{시간}\)
-
평균 속도 = \(400 / 6 = 66.67 \,\text{km/h}\)
위와 같은 계산법은 조화평균 공식을 적용하면 정확하게 같은 값을 얻을 수 있다.
직관적인 예시 2 (평균 성능 비교)
-
CPU의 평균 성능
-
CPU A: 초당 \(100\) 회 연산 (\(100 \, \text{ops/s}\))
-
CPU B: 초당 \(300\) 회 연산 (\(300 \, \text{ops/s}\))
-
산술평균은 다음과 같다.
하지만 조화평균 개념을 적용하면 다음과 같다.
두 CPU가 같은 양의 작업을 순차적으로 처리할 경우, 산술평균은 \(200\)으로 과대 평가되어 있다.
순차적으로 같은 작업량을 처리할 경우 속도는 총 시간은 구간별 시간이 합이 되어야 한다.
같은 작업량 1 단위를 각각 처리하면 걸리는 시간은 각각 \(\tfrac{1}{100}\)초, \(\tfrac{1}{300}\) 초가 된다.
2개의 CPU가 작업하므로 총 작업량은 2 단위이다. 그리고 총 시간은 \(\tfrac{1}{100} + \tfrac{1}{300}\) 초 이다.
두 속도로 같은 작업량을 순차적으로 처리한 경우의 평균은 \(\tfrac{전체 작업량}{전체 시간}\) 이므로, 평균 속도는 다음과 같다.
산술평균은 단순히 "값의 크기"만 고려해서 평균을 내지만, CPU 성능처럼 같은 작업을 순차적으로 처리하는 상황에서는 각 속도(\(100\), \(300\) 연산/초)에서 걸린 시간이 중요한 역할을 한다.
-
CPU A는 느리기 때문에 작업 시간의 대부분을 차지한다.
-
CPU B는 빠르지만, 전체 작업 시간에서 차지하는 비중은 상대적으로 작다.
즉, "작업 시간"을 고려하지 않은 단순 산술평균은 빠른 CPU의 성능을 지나치게 반영하고, 느린 CPU의 영향을 과소평가한다.
과대평가에 대한 것은 간단한 예제를 통해 쉽게 이해할 수 있다.
CPU A와 B가 전체 600개의 연산을 순차적으로 처리한다고 하자. 각 CPU는 300개의 연산을 처리해야 한다.
-
실제 전체 작업량:
600 ops -
실제 전체 시간: $\tfrac{300}{100} + \tfrac{300}{300} = 3 + 1 = $
4s -
실제 평균 속도: \(600 / 4 = 150 \, \text{ops/s}\)
하지만 산술 평균을 작용하면 \(\tfrac{100 + 300}{2} = \,\) 200 ops/s 이다.
결과적으로 실제 평균 성능보다 산술평균이 높게(과대평가) 나온다.
조화평균은 각 값의 역수(시간 개념)를 평균 내므로, 실제로 작업을 수행할 때의 "시간적 기여도"를 올바르게 반영한다.
그래서 CPU처럼 속도, 비율, 효율이 문제될 때는 조화평균이 맞는 평균이다.
즉, 실제 성능은 \(150\) 연산/초로 보는 게 맞다.
분모에 들어가야 하는 값이 분수 꼴인 경우에는 조화 평균을 쓴다.
특히 속도, 처리율, 가동율, 인구밀도, 자동차 연비, 생산성과 같이
역수 단위 1/어떤값 (역수 단위) 로 표현되는 값들의 평균을 낼 때 사용한다.
절사평균 (Trimmed Mean)
데이터에서 상위와 하위 일부 값을 제외하고 산술평균을 계산하는 방법이다.
극단값의 영향을 줄여 안정적인 대표값을 얻는 데 효과적이다.
\(x_{(i)}\) : 오름차순으로 정렬된 데이터
\(k = \lfloor p \cdot n \rfloor\) (제거할 데이터 개수)
언제 어떤 대표값(평균)을 사용할 것인가?
| 평균 종류 | 정의 | 언제 쓰는가 | 대표 사례 |
|---|---|---|---|
| 산술평균 (Arithmetic Mean) |
값들의 합 ÷ 개수 | 값이 단순히 더해지는 상황 | 시험 점수 평균, 키·몸무게, 소득 |
| 기하평균 (Geometric Mean) |
값들의 곱의 n 제곱근 |
곱셈·성장률·비율의 누적 효과가 중요한 상황 | 투자 수익률, 인구 증가율, 성장률 비교 |
| 조화평균 (Harmonic Mean) |
값 개수 ÷ (역수들의 합) | 속도·효율·비율처럼 분모가 중요한 상황 | 평균 속도, 연비, CPU 성능, 처리율 |
평균들의 특성 비교
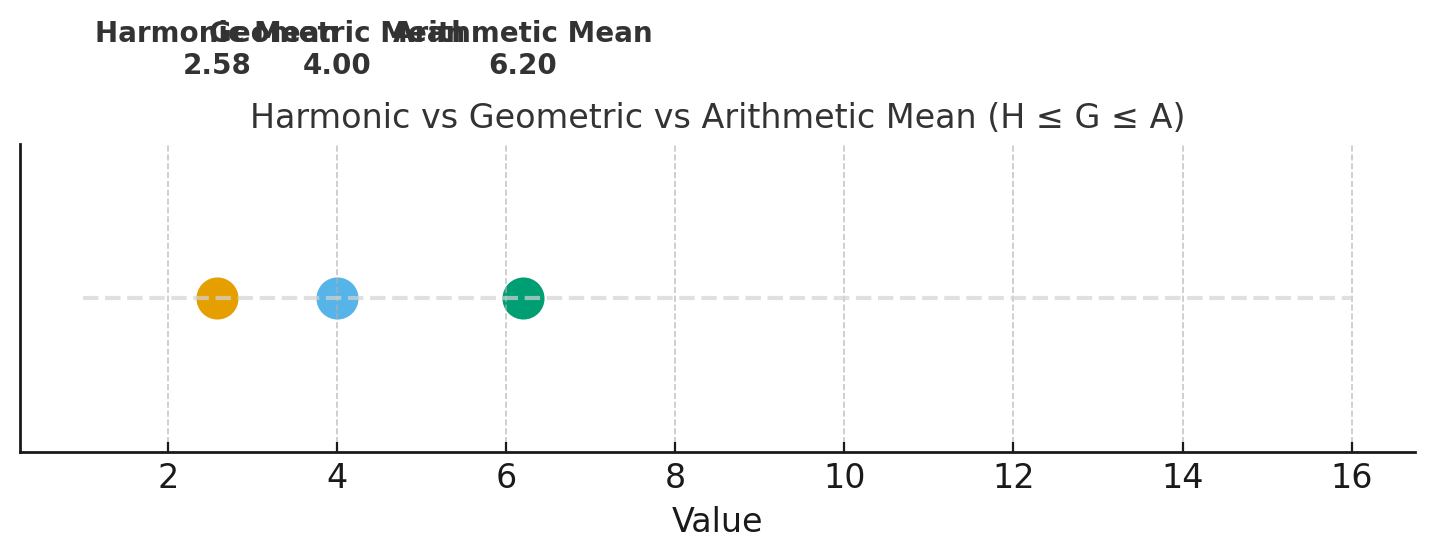
[1, 2, 4, 8, 16] 이용해 평균을 구했을 경우 위치 비교
| 평균 종류 | 수식 | 계산 결과 |
|---|---|---|
| 산술평균 (A) | \(A = \dfrac{1}{n} \sum_{i=1}^n x_i\) | 6.20 |
| 기하평균 (G) | \(G = \left( \prod_{i=1}^n x_i \right)^{1/n}\) | 4.00 |
| 조화평균 (H) | \(H = \dfrac{n}{\sum_{i=1}^n \tfrac{1}{x_i}}\) | 2.58 |
각 평균과의 관계: \(H \; (2.58) \;\leq\; G \; (4.00) \;\leq\; A \; (6.20)\)
평균은 데이터를 대표하는 중요한 통계량이지만, 단순히 산술평균만으로는 충분하지 않다.
데이터의 특성과 목적에 따라 가중평균, 기하평균, 조화평균, 절사평균 등을 적절히 활용해야 한다.
-
성적 산출 → 가중평균
-
금융 투자 수익률 → 기하평균
-
이동 속도 계산 → 조화평균
다양한 평균을 구하는 실습
# 목적: 여러 종류의 평균(산술, 가중, 기하, 조화, 절사) 계산 예제
# 환경: Python 3.10+, numpy, scipy (선택), statistics(표준 라이브러리)
from statistics import mean, geometric_mean, harmonic_mean
import numpy as np
from scipy import stats # trim_mean, gmean, hmean 도 제공
# 샘플 데이터: 시험 점수 또는 성과 지표 등
x = [70, 75, 80, 85, 90]
# 가중치 예시: 중간 40%, 기말 60% 같은 개념으로 비율 합이 1이 되도록
weights = [0.4, 0.0, 0.0, 0.0, 0.6] # 단순 예시: 처음과 마지막 항목만 가중
def arithmetic_mean(arr):
"""산술평균: 모든 값을 더해 개수로 나눔. 이상치에 민감."""
return sum(arr) / len(arr)
def weighted_mean(arr, w):
"""가중평균: 항목별 중요도(가중치)를 곱해 합한 뒤 가중치 합으로 나눔."""
arr = np.asarray(arr, dtype=float)
w = np.asarray(w, dtype=float)
if np.isclose(w.sum(), 0):
raise ValueError("가중치의 합이 0이면 안 됩니다.")
return float((arr * w).sum() / w.sum())
def geometric_mean_safe(arr, eps=1e-12):
"""
기하평균: 양수 데이터에 적합(성장률, 비율 등).
0이나 음수가 포함되면 직접 계산이 불가하므로 작은 양수 eps를 더해 보정.
보정이 필요한 상황에서는 해석에 주의.
"""
arr = np.asarray(arr, dtype=float)
if (arr <= 0).any():
arr = arr + eps
# 표준 라이브러리: statistics.geometric_mean(arr) 사용 가능
return float(geometric_mean(arr))
def harmonic_mean_safe(arr, eps=1e-12):
"""
조화평균: 속도, 비율처럼 '단위당' 개념에 적합. 0이나 음수에 민감.
0이 있으면 분모가 0이라 계산 불가 → eps로 보정하되 해석에 주의.
"""
arr = np.asarray(arr, dtype=float)
if (arr <= 0).any():
arr = arr + eps
# 표준 라이브러리: statistics.harmonic_mean(arr) 사용 가능
return float(harmonic_mean(arr))
def trimmed_mean(arr, proportion_to_cut=0.1):
"""
절사평균: 상하위 극단값을 일정 비율만큼 잘라내고 산술평균.
proportion_to_cut=0.1이면 상위 10%, 하위 10%씩 제거.
이상치 영향을 완화하여 안정적인 대표값을 얻는 데 유용.
"""
return float(stats.trim_mean(arr, proportiontocut=proportion_to_cut))
def main():
print("========== 데이터 ==========")
print(f"x = {x}")
print()
print("========== 산술평균 ==========")
# 방법 1: 직접 구현
print(f"산술평균(직접): {arithmetic_mean(x):.4f}")
# 방법 2: 표준 라이브러리
print(f"산술평균(statistics.mean): {mean(x):.4f}")
print()
print("========== 가중평균 ==========")
print(f"가중치 = {weights} (합={sum(weights):.1f})")
print(f"가중평균(직접): {weighted_mean(x, weights):.4f}")
# numpy.average도 가중평균 지원
print(f"가중평균(np.average): {float(np.average(x, weights=weights)):.4f}")
print()
print("========== 기하평균 ==========")
# 표준 라이브러리
print(f"기하평균(statistics.geometric_mean): {geometric_mean(x):.4f}")
# scipy: stats.gmean(x)
print(f"기하평균(scipy.stats.gmean): {float(stats.gmean(x)):.4f}")
# 안전 버전(0 또는 음수 보정)
print(f"기하평균(보정): {geometric_mean_safe(x):.4f}")
print()
print("========== 조화평균 ==========")
# 표준 라이브러리
print(f"조화평균(statistics.harmonic_mean): {harmonic_mean(x):.4f}")
# scipy: stats.hmean(x)
print(f"조화평균(scipy.stats.hmean): {float(stats.hmean(x)):.4f}")
# 안전 버전(0 또는 음수 보정)
# 데이터에 0이 포함되면 → 1/0 은 무한대가 되어서 계산 불가능
# 데이터에 음수 값이 포함되면 → 역수가 음수로 나오고, 어떤 경우에는 전체 분모가 0에 가까워져서 비정상적인 값이 나올 수 있음
# 안전 버전에서는 0이면 아주 작은 값(예: 1e-8)으로 치환
print(f"조화평균(보정): {harmonic_mean_safe(x):.4f}")
print()
print("========== 절사평균 ==========")
for p in (0.05, 0.1, 0.2):
print(f"절사평균(trim {int(p*100)}%): {trimmed_mean(x, p):.4f}")
print()
# 참고: 극단값을 추가해 평균 간 민감도 비교
x_with_outlier = x + [1000]
print("========== 극단값 민감도 비교 ==========")
print(f"원 데이터: {x} -> 산술평균 {mean(x):.2f}, 절사평균(10%) {trimmed_mean(x, 0.1):.2f}")
print(f"이상치 추가: {x_with_outlier} -> 산술평균 {mean(x_with_outlier):.2f}, 절사평균(10%) {trimmed_mean(x_with_outlier, 0.1):.2f}")
print()
print("해석 가이드")
print("- 산술평균은 이상치에 매우 민감하다.")
print("- 절사평균은 상하위 극단값을 제거해 이상치 영향을 완화한다.")
print("- 기하평균은 성장률/비율 데이터에, 조화평균은 속도/단위당 데이터에 적합하다.")
print("- 가중평균은 항목 중요도가 서로 다른 경우에 사용한다.")
if __name__ == "__main__":
main()
실행 결과
$ python test.py
========== 데이터 ==========
x = [70, 75, 80, 85, 90]
========== 산술평균 ==========
산술평균(직접): 80.0000
산술평균(statistics.mean): 80.0000
========== 가중평균 ==========
가중치 = [0.4, 0.0, 0.0, 0.0, 0.6] (합=1.0)
가중평균(직접): 82.0000
가중평균(np.average): 82.0000
========== 기하평균 ==========
기하평균(statistics.geometric_mean): 79.6860
기하평균(scipy.stats.gmean): 79.6860
기하평균(보정): 79.6860
========== 조화평균 ==========
조화평균(statistics.harmonic_mean): 79.3715
조화평균(scipy.stats.hmean): 79.3715
조화평균(보정): 79.3715
========== 절사평균 ==========
절사평균(trim 5%): 80.0000
절사평균(trim 10%): 80.0000
절사평균(trim 20%): 80.0000
========== 극단값 민감도 비교 ==========
원 데이터: [70, 75, 80, 85, 90] -> 산술평균 80.00, 절사평균(10%) 80.00
이상치 추가: [70, 75, 80, 85, 90, 1000] -> 산술평균 233.33, 절사평균(10%) 233.33
해석 가이드
- 산술평균은 이상치에 매우 민감하다.
- 절사평균은 상하위 극단값을 제거해 이상치 영향을 완화한다.
- 기하평균은 성장률/비율 데이터에, 조화평균은 속도/단위당 데이터에 적합하다.
- 가중평균은 항목 중요도가 서로 다른 경우에 사용한다.
평균을 활용할 때는 단순한 계산을 넘어서, 데이터의 맥락에 가장 적합한 평균을 선택하는 것이 무엇보다 중요하다.
-
중앙값(Median): 데이터를 크기순으로 정렬했을 때 중앙에 위치한 값으로, 이상치에 덜 민감하여 분포가 치우친 경우에도 대표값으로 활용하기 적합하다.
-
최빈값(Mode): 데이터에서 가장 자주 나타나는 값으로, 특히 범주형 데이터 분석에 유용하다.
산포도 (Measures of Dispersion)
데이터가 평균을 중심으로 얼마나 퍼져 있는지를 나타내는 지표를 산포도라 한다.
-
분산(Variance): 각 데이터 값이 평균으로부터 얼마나 떨어져 있는지를 제곱하여 평균낸 값이다. 값이 클수록 데이터가 넓게 퍼져 있음을 의미한다.
-
표준편차(Standard Deviation): 분산의 제곱근으로, 원래 데이터 단위와 동일하게 해석할 수 있어 직관적으로 이해하기 쉽다.
-
사분위수(Quartiles): 데이터를 4등분한 값으로, 데이터의 분포 범위와 퍼짐 정도를 쉽게 확인할 수 있다. 특히 제1사분위수(
Q1), 중앙값(Q2), 제3사분위수(Q3)를 이용해 데이터의 범위와 이상치를 판단할 수 있다.
활용 예시
한 반 학생들의 시험 점수가 있다고 하자. 단순히 평균 점수가 75점이라고 말하는 것보다는,
“평균은
75점, 중앙값은78점, 표준편차는12점”
이라고 기술하면 학생들의 성적이 얼마나 고르게 분포되어 있는지 더 명확히 이해할 수 있다. 또한 “최빈값은 82점”이라고 하면 가장 흔한 점수대까지 파악할 수 있어 데이터에 대한 설명력이 높아진다.
기술통계는 데이터 전체를 몇 개의 핵심 지표로 요약하여 데이터의 특징을 빠르게 파악할 수 있도록 한다.
기술통계는 단순한 요약을 넘어, 이후 확률분포 분석, 추정, 가설검정과 같은 통계적 추론의 기초가 되는 중요한 단계이다.
확률변수
-
확률변수(Random Variable): 우연적인 사건의 결과를 수치로 표현한 것
- 예: 주사위 눈금(
1 ~ 6), 시험 점수(0 ~ 100)
- 예: 주사위 눈금(
확률변수는 함수라는 관점
확률변수는 단순히 결과 값이 아니라, 확률적 실험의 표본공간(Sample Space)에서 실제 수치 집합으로의 사상(mapping function) 이다.
- \(\Omega\): 가능한 모든 사건들의 집합(표본공간)
- \(\mathbb{R}\): 실수 집합
- 예: 주사위 실험에서 \(\Omega = \{\omega_1, \omega_2, \ldots, \omega_6\}\) 이라 하면, 확률변수 \(X\)는 각 사건 \(\omega_i\)를 눈금 값 \(\{1,2,3,4,5,6\}\)으로 매핑한다.
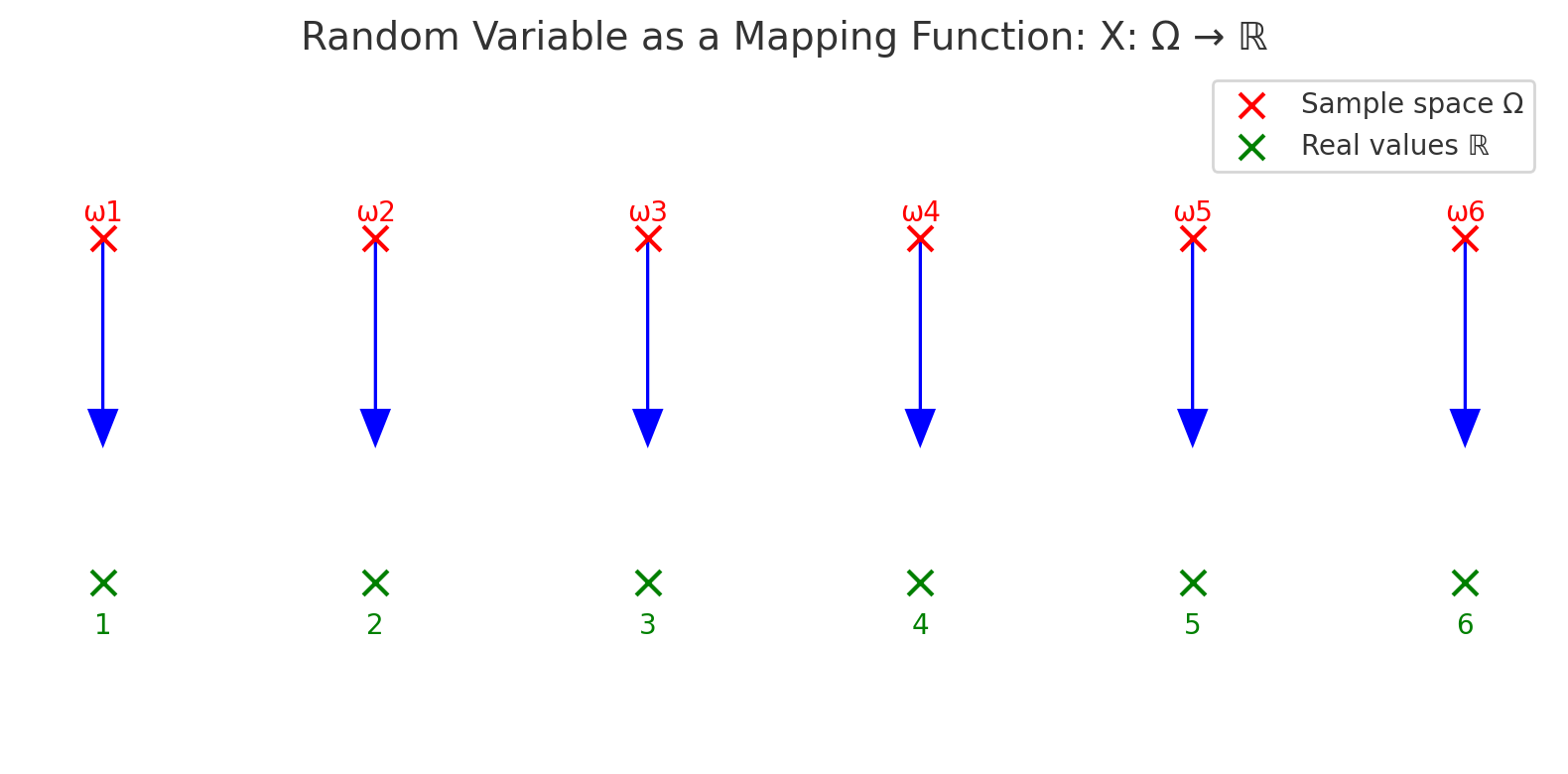
왜 함수로 이해해야 할까?
-
수학적 일관성 사건에 확률을 부여하고 이를 계산하기 위해서는 사건을 수치로 변환하는 규칙이 필요하다.
-
확률분포 정의의 기반 확률분포는 “확률변수가 특정 수치를 가질 확률”을 나타내므로, 확률변수의 함수적 성질이 전제되어야 한다.
-
응용의 편리성 실제 데이터 분석에서는 사건 자체보다는 수치화된 결과를 다루는 것이 효율적이다.
- 예: 동전의 앞면/뒷면 → {
0, 1}로 매핑하여 통계적 계산 수행.
확률변수 vs 수학적 변수
-
수학에서의 변수: 보통 미지수나 값을 임의로 대입할 수 있는 기호로, 그 자체가 값(value)을 직접 나타낸다.
-
확률변수: 표본공간의 사건을 실수로 변환하는 함수이며, 사건에 확률이 결합되어 있다는 점이 본질적인 차이다.
즉, \(x=3\) 같은 단순한 대입은 수학적 변수의 개념이고,
주사위를 던져서 나온 사건 \(\omega\)를 \(X(\omega)=3\)으로 매핑하는 것은 확률변수의 개념이다.
따라서 확률변수는 단순한 “숫자 기호”가 아니라, 사건을 수치로 연결시켜 확률적 계산을 가능하게 하는 함수적 개념이다.
확률변수를 대문자 \(X\)로 쓰는 이유
-
함수로서의 개념 구분
-
확률변수는 표본공간에서 실수 집합으로의 함수이다.
-
따라서 “랜덤한 수 자체”라기보다 “사건을 수치로 매핑하는 규칙”을 의미한다.
-
이를 일반 수치와 구분하기 위해 대문자(예: X, Y, Z) 를 사용한다.
-
-
실현값(Realization)과 구분
-
확률변수 \(X\) : 아직 결과가 정해지지 않은 “랜덤 함수”
-
실현값(관측값) \(x\) : 실험을 통해 실제로 관측된 구체적인 수치
-
즉, \(X\)는 변수 자체, \(x\)는 그 결과 값을 나타낸다.
-
예: “주사위 눈금을 나타내는 확률변수 \(X\)”가 있고, 실제 던져서 나온 값이 \(x=3\) 이라면 \(X=3\) 이 된다.
-
-
수학적 표기 관습
-
수학·통계학에서 대문자는 일반적으로 무작위적 대상(확률변수, 집합, 행렬 등)을 표시하는 데 자주 쓰인다.
-
반면, 소문자는 특정 수치 값이나 샘플을 표시할 때 사용된다.
-
정리하면, 확률변수 \(X\)는 대문자로, 그 결과 값 \(x\)는 소문자로 구분하는 것은 “확률적 성질을 가진 함수”와 “그 함수가 만들어낸 실제 값”을 명확히 나누기 위함이다.
이산형 vs. 연속형 확률변수
확률변수는 크게 이산형(discrete) 과 연속형(continuous) 으로 나눌 수 있다.
이 구분은 확률변수가 가질 수 있는 값의 형태와 확률을 표현하는 방식에서 비롯된다.
이산형 확률변수 (Discrete Random Variable)
-
특징: 셀 수 있는 값들만 취한다. 값의 집합이 유한하거나 가산무한(
1, 2, 3, ...)일 수 있다. -
확률 표현: 각 가능한 값마다 확률을 직접 부여하며, 모든 확률의 합은
1이다. -
예시:
-
주사위 눈금 (
1, 2, 3, 4, 5, 6) -
동전 던지기의 결과 (앞면=
1, 뒷면=0) -
하루에 도착하는 손님 수 (
0명,1명,2명,...)
-
연속형 확률변수 (Continuous Random Variable)
-
특징: 특정 구간 안에서 무한히 많은 값을 가질 수 있다. 값은 연속적인 실수 범위에 속한다.
-
확률 표현: 특정 값 하나의 확률은 0이며, 구간에 대한 확률로 정의된다. 이때 확률밀도함수(pdf)를 사용한다.
-
예시:
-
사람의 키, 몸무게
-
특정 지역의 기온, 강수량
-
기계가 고장 나기까지 걸리는 시간
-
비교 정리
| 구분 | 이산형 확률변수 | 연속형 확률변수 |
|---|---|---|
| 값의 형태 | 셀 수 있는 값 (유한 또는 가산무한) | 연속적인 실수 구간 |
| 확률 표현 | 확률질량함수 (PMF) | 확률밀도함수 (PDF) |
| 특정 값의 확률 | \(P(X = x) > 0\) 가능 | \(P(X = x) = 0\), 구간 확률로 정의 |
| 예시 | 주사위, 동전, 손님 수 | 키, 몸무게, 시간, 온도 |
- 이산형은 점 단위 확률, 연속형은 구간 단위 확률로 이해하면 된다.
시각화 예시
# 목적: PMF(주사위)와 PDF(정규분포) 비교 그림 저장
# 환경: Python 3.10+, matplotlib, scipy 필요
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# -------- PMF (주사위 예시) --------
x_pmf = np.arange(1, 7)
pmf = np.ones_like(x_pmf) / 6 # 균등 분포 (1/6)
# -------- PDF (정규분포 예시) --------
x_pdf = np.linspace(-4, 10, 500)
mu, sigma = 3, 1.5 # 평균과 표준편차
pdf = norm.pdf(x_pdf, mu, sigma)
# -------- 시각화 --------
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# PMF (이산형 확률변수: 주사위)
axes[0].bar(x_pmf, pmf, color="skyblue", edgecolor="black")
axes[0].set_xticks(x_pmf)
axes[0].set_title("PMF - Dice Roll (Discrete)", fontsize=12)
axes[0].set_xlabel("Dice Outcome")
axes[0].set_ylabel("Probability")
# PDF (연속형 확률변수: 정규분포)
axes[1].plot(x_pdf, pdf, color="tomato", linewidth=2)
axes[1].fill_between(x_pdf, pdf, color="tomato", alpha=0.3)
axes[1].set_title("PDF - Normal Distribution (Continuous)", fontsize=12)
axes[1].set_xlabel("x")
axes[1].set_ylabel("Density")
plt.tight_layout()
# -------- 이미지 저장 --------
plt.savefig("pmf_pdf_example.png", dpi=300)
plt.show()
print("'pmf_pdf_example.png' 파일이 저장되었습니다.")
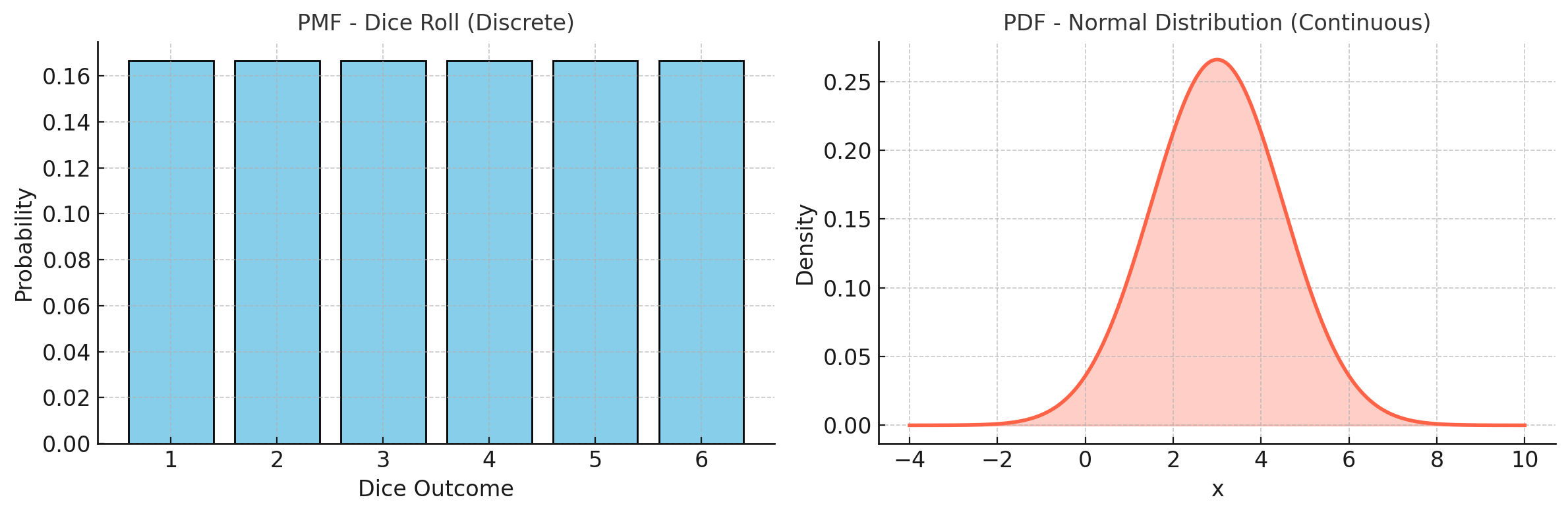
주사위를 던졌을 때 나오는 눈금을 확률변수 \(X\)라고 하자.
-
가능한 값: \(1, 2, 3, 4, 5, 6\)
-
각 값의 확률: \(p(x) = \tfrac{1}{6}\)
-
이 경우 \(P(X=3) = \tfrac{1}{6}\) 은 "주사위를 던졌을 때
3이 나올 확률"을 의미한다. -
왼쪽 (Dice Roll): 주사위 눈금
{1,2,3,4,5,6}은 셀 수 있는 값이며, 각 값의 확률은 \(\tfrac{1}{6}\). -
오른쪽 (Normal Distribution): 정규분포는 연속형 확률변수로, 특정 점의 확률은
0이고 곡선 아래 면적이 구간 확률을 나타낸다.
확률분포
확률분포(Probability Distribution)란, 확률변수(Random Variable)가 가질 수 있는 값들과 그 값들이 나타날 확률을 체계적으로 정리한 것이다. 즉, "어떤 값이 얼마나 자주 나타나는가"를 수학적으로 표현한 것이다.
이산형 확률분포 (Discrete Probability Distribution)
이산형 확률분포란 확률변수가 가질 수 있는 값이 정수처럼 하나하나 세어질 수 있는 경우에 해당하는 분포를 말한다.
즉, 확률변수가 취할 수 있는 값들은 뚝뚝 끊어져 있으며, 각각의 값마다 확률이 주어진다.
이때 확률변수의 가능한 값들은 유한 개일 수도 있고, 무한히 많더라도 셀 수 있는 경우라면 모두 이산형에 속한다.
예를 들어 동전을 여러 번 던졌을 때 앞면이 나오는 횟수, 주사위를 던졌을 때 나오는 눈금, 혹은 편의점에 1시간 동안 들어오는 손님 수와 같은 경우가 이산형 확률변수에 해당한다. 이러한 값들은 하나씩 세어 나열할 수 있기 때문에 이산형이라고 부른다.
이산형 확률분포에서는 각 값에 대한 확률을 직접 더할 수 있으며, 모든 확률의 합은 항상 1이 된다. 예를 들어 주사위를 던졌을 때, 눈금이 1부터 6까지 나올 확률은 각각 모두 1/6이고, 이를 모두 합하면 1이 된다. 즉, 가능한 모든 값의 확률을 합하면 반드시 1이 되어야 한다는 것이 이산형 확률분포의 중요한 성질이다.
이산형 확률분포는 결과가 셀 수 있는 값들로만 이루어져 있고, 각각의 값에 확률이 배분되는 경우를 말한다. 대표적인 예로는 이항분포, 포아송분포, 기하분포가 있으며, 이러한 분포들은 각각의 상황에 맞게 특정 사건이 발생할 확률을 모델링하는 데 활용된다.
확률질량함수 (Probability Mass Function, PMF)
확률질량함수 (Probability Mass Function, PMF)는 이산형 확률변수의 분포를 정의하는 함수이다.
확률변수 \(X\)가 특정 값 \(x\)를 가질 확률을 다음과 같이 나타낸다.
특징 1. \(0 \leq f(x) \leq 1\) (모든 확률은 0과 1 사이에 있음)
-
가능한 모든 값에 대한 확률의 합은 1 $$ \sum_x f(x) = 1 $$
-
PMF를 알면 평균(기대값)과 분산 같은 통계적 특성을 계산할 수 있다.
- 기대값: $$ E[X] = \sum_x x \cdot f(x) $$
- 분산: $$ Var(X) = \sum_x (x - E[X])^2 f(x) $$
역할
PMF는 이산형 확률변수의 성질을 설명하는 기본 도구이다.
이를 통해 사건의 확률뿐 아니라 분포의 중심(평균), 흩어짐(분산), 전체 구조를 이해하고 분석할 수 있다.
예시
공정한 주사위의 눈금을 나타내는 확률변수 \(X\)가 있다고 하자.
가능한 값은 \(\{1,2,3,4,5,6\}\)이고, 각 눈금이 나올 확률은 모두 동일하다.
이항분포 (Binomial Distribution)
이항분포는 어떤 사건이 두 가지 결과(성공/실패, 참/거짓, 앞/뒤 등)로만 나뉘는 상황에서,
동일한 확률을 가진 독립적인 시행을 여러 번 반복했을 때 성공이 발생하는 횟수를 나타내는 분포이다.
예를 들어 동전을 10번 던져서 앞면이 몇 번 나오는지를 모델링할 때 이항분포를 사용할 수 있다.
수식 정의
이항분포의 확률질량함수(PMF)는 다음과 같이 정의된다.
-
\(n\): 독립 시행의 횟수
-
\(p\): 한 번의 시행에서 성공할 확률
-
\(k\): 성공 횟수
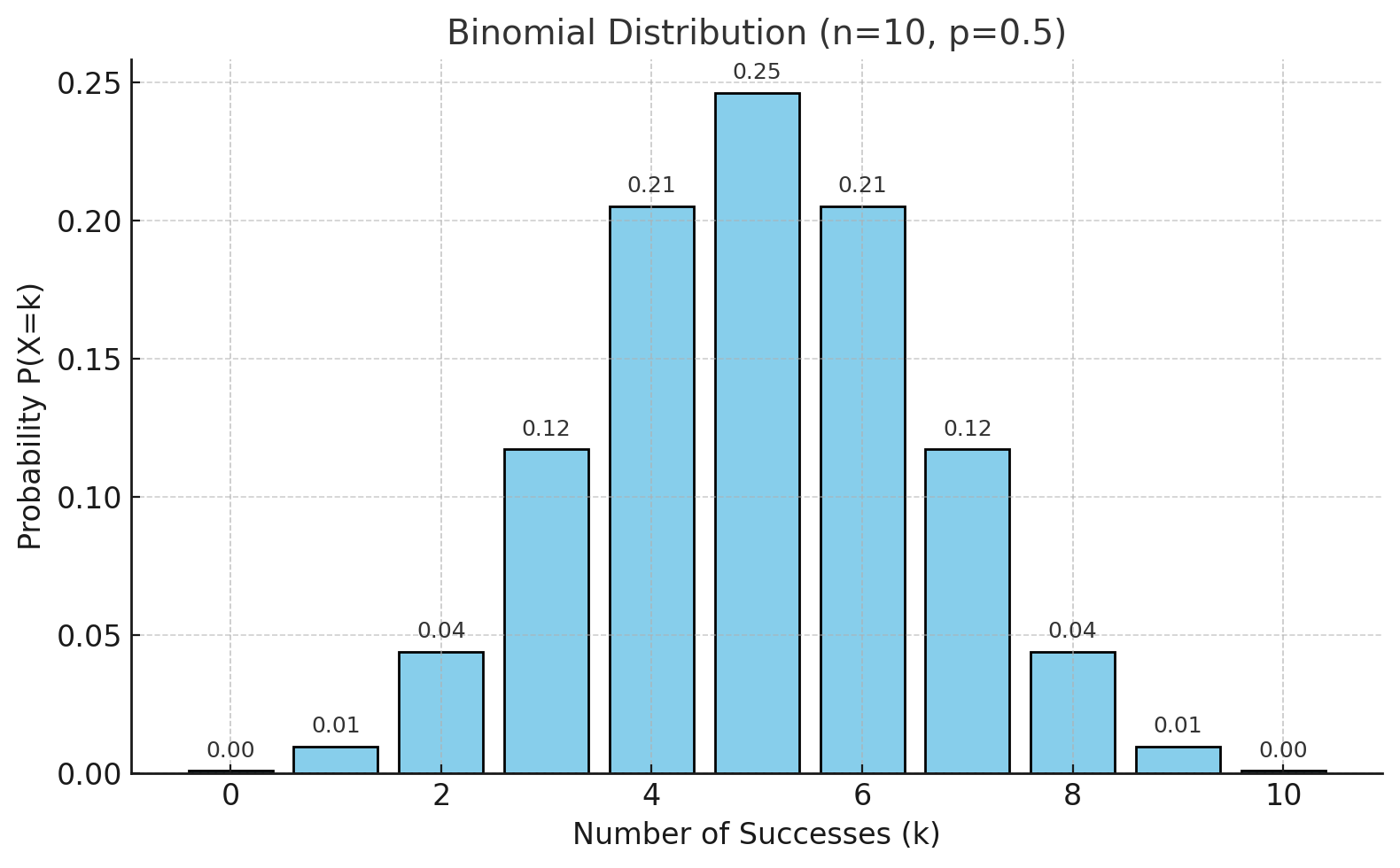
위 그림은 \(n=10\), 성공확률 \(p=0.5\)일 때의 이항분포 확률질량함수(PMF)를 나타낸다.
가로축은 성공 횟수 \(k\), 세로축은 확률 \(P(X=k)\)를 의미한다.
각 막대는 10번의 독립 시행에서 정확히 \(k\)번 성공할 확률을 나타내며, \(p=0.5\)이므로 분포가 좌우 대칭을 이룬다.
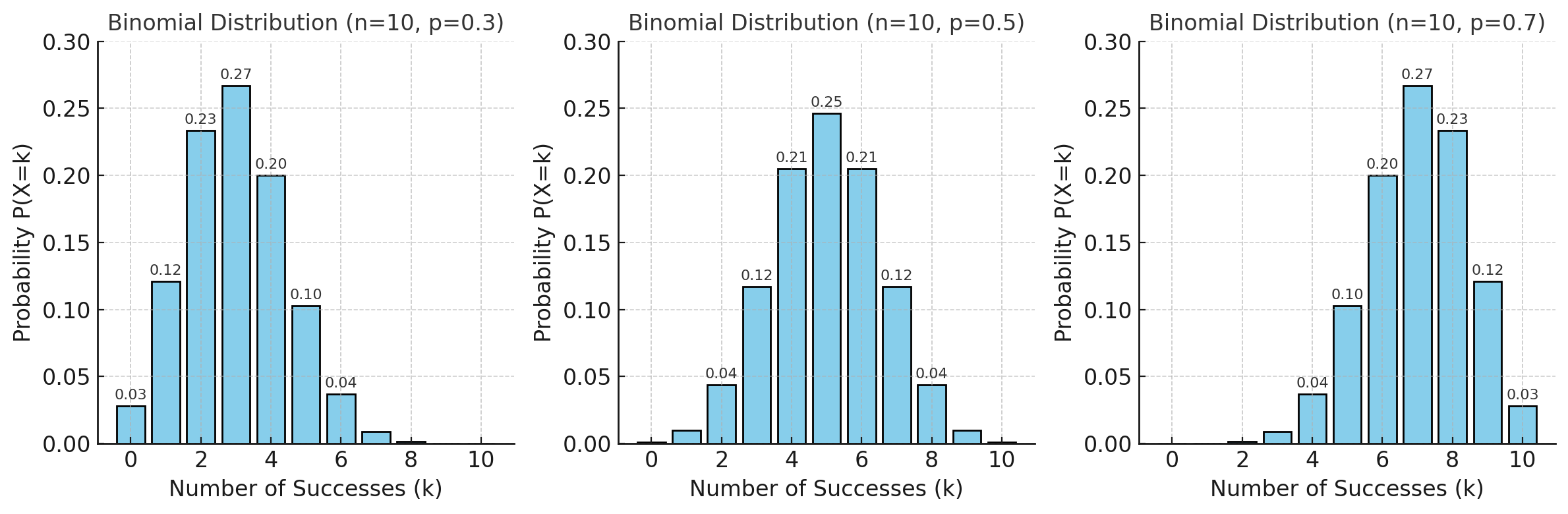
위 그림은 \(n=10\)일 때 성공 확률 \(p\)에 따른 이항분포 확률질량함수(PMF)의 변화를 보여준다.
-
왼쪽 (p=0.3): 성공 확률이 낮아 분포가 왼쪽으로 치우침
-
가운데 (p=0.5): 성공과 실패 확률이 같아 분포가 좌우 대칭
-
오른쪽 (p=0.7): 성공 확률이 높아 분포가 오른쪽으로 치우침
성공 확률 \(p\)의 값에 따라 이항분포의 모양이 달라진다.
특징
-
시행은 서로 독립적이며, 각 시행의 성공 확률은 항상 동일하다.
-
가능한 값은 \(0 \leq k \leq n\) 의 정수이다.
-
평균과 분산은 다음과 같다.
-
평균: \(E[X] = np\)
-
분산: \(Var[X] = np(1-p)\)
-
-
시행 횟수 \(n\)이 커지고 \(p\)가 적당할 때, 정규분포로 근사할 수 있다.
-
\(n\)이 크고 \(p\)가 매우 작을 때는 포아송분포로 근사할 수 있다.
사용하는 분야
-
통계학: 설문조사 응답(성공/실패), 품질관리(불량품 개수), 임상시험 성공률 분석
-
산업: 생산 라인에서 불량품 비율 추정, 마케팅 캠페인의 성공 횟수 예측
-
자연과학: 유전자 발현 확률, 생물학적 성공·실패 실험
이항분포는 성공/실패가 명확한 반복 시행의 결과를 다루는 가장 기본적인 분포이며, 통계학뿐만 아니라 머신러닝과 인공지능 알고리즘의 핵심적인 확률적 기반을 제공한다.
포아송분포 (Poisson Distribution)
포아송분포는 일정한 시간이나 공간에서 드물게 일어나는 사건의 발생 횟수를 모델링할 때 사용되는 확률분포이다.
사건이 발생하는 평균 횟수(λ)가 주어졌을 때, 실제로 관측되는 사건 횟수가 어떤 확률로 일어나는지를 설명한다.
예를 들어, 한 시간 동안 콜센터에 걸려오는 전화의 수나, 하루 동안 특정 웹사이트에 접속하는 사용자의 수가 이에 해당한다.
수식 정의
포아송분포의 확률질량함수(PMF)는 다음과 같이 정의된다.
-
\(\lambda\): 단위 시간(또는 단위 공간)당 평균 발생 횟수
-
\(k\): 실제로 관측된 사건의 횟수
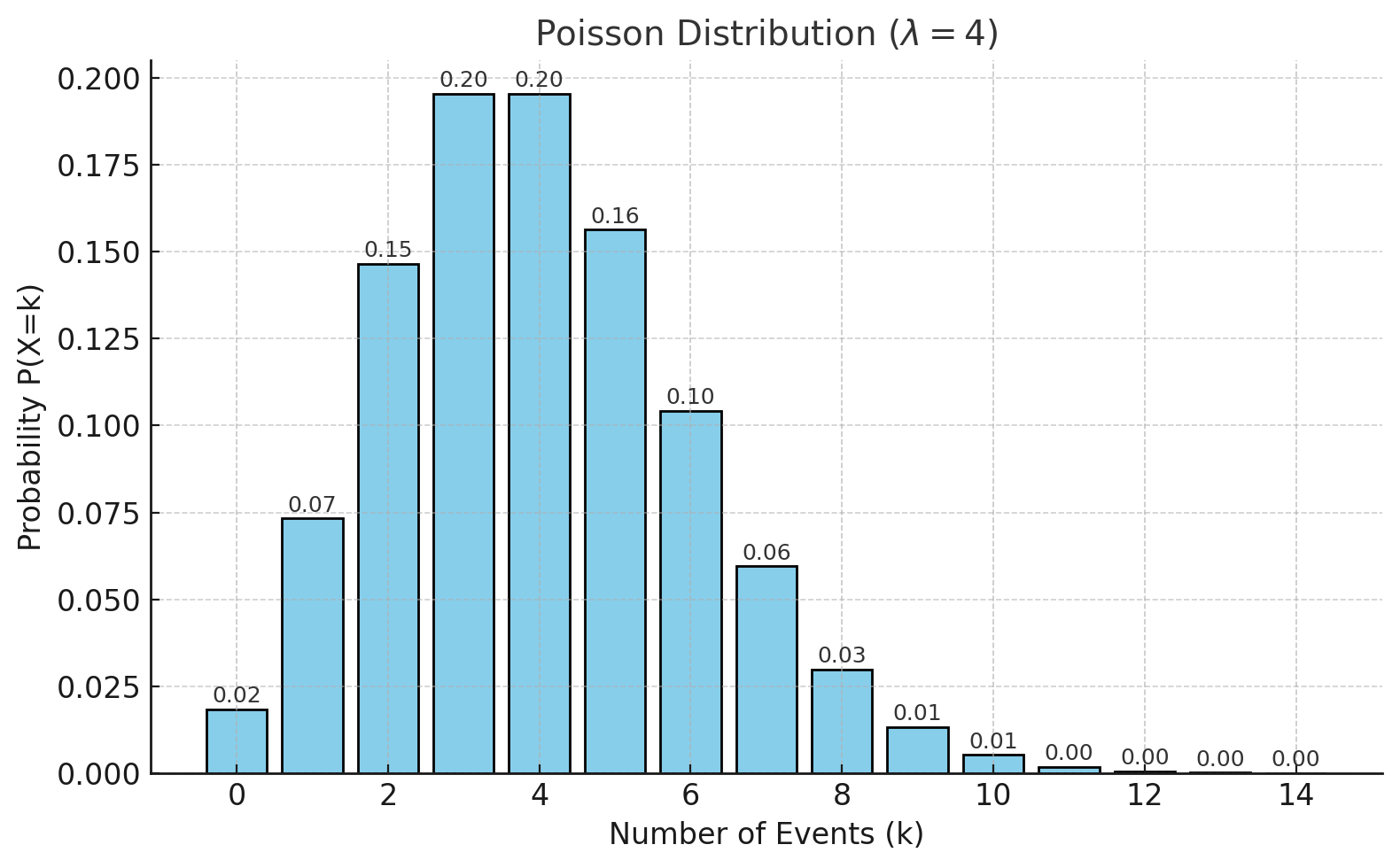
위 그림은 평균 발생 횟수 \(\lambda = 4\)일 때의 포아송분포 확률질량함수(PMF)를 보여준다.
가로축은 사건 발생 횟수 \(k\), 세로축은 확률 \(P(X=k)\)를 의미한다.
막대의 높이는 단위 시간(또는 단위 공간) 동안 사건이 정확히 \(k\)번 발생할 확률을 나타내며,
분포는 평균값 \(\lambda\) 근처에서 가장 높고, \(k\)가 멀어질수록 점차 낮아진다.
특징
-
사건은 서로 독립적으로 발생한다.
-
사건 발생 확률은 짧은 시간 간격에서 비례적으로 일어나며, 동시에 여러 사건이 동시에 발생할 확률은 매우 작다.
-
평균과 분산이 동일하다.
-
평균: \(E[X] = \lambda\)
-
분산: \(Var[X] = \lambda\)
-
-
이항분포에서 시행 횟수 \(n\)이 크고 성공 확률 \(p\)가 작을 때, \(np = \lambda\)로 두면 포아송분포로 근사할 수 있다.
사용하는 분야
-
통신: 단위 시간당 도착하는 전화 호출 수
-
교통: 일정 시간 동안 교차로에 도착하는 차량의 수
-
자연과학: 방사성 붕괴 입자의 발생 횟수, 돌연변이 유전자 발생 빈도
-
서비스 산업: 병원에 응급환자가 도착하는 횟수, 고객 불만 신고 건수
포아송분포는 드물지만 일정 평균으로 발생하는 사건의 발생 횟수를 다루는 분포이며, 통신·교통·의료 같은 실생활뿐만 아니라 NLP, 추천 시스템, 딥러닝 손실 함수 등 인공지능 분야에서도 중요한 역할을 한다.
기하분포 (Geometric Distribution)
기하분포는 어떤 사건이 두 가지 결과(성공/실패)로만 나뉘는 베르누이 시행에서, 첫 번째 성공이 나올 때까지의 시행 횟수를 확률변수로 하는 분포이다. 예를 들어, 동전을 계속 던졌을 때 처음으로 앞면이 나올 때까지 걸린 횟수를 모델링할 수 있다.
수식 정의
기하분포의 확률질량함수(PMF)는 다음과 같이 정의된다.
-
\(p\): 성공 확률
-
\(k\): 첫 성공이 일어나기까지의 시행 횟수
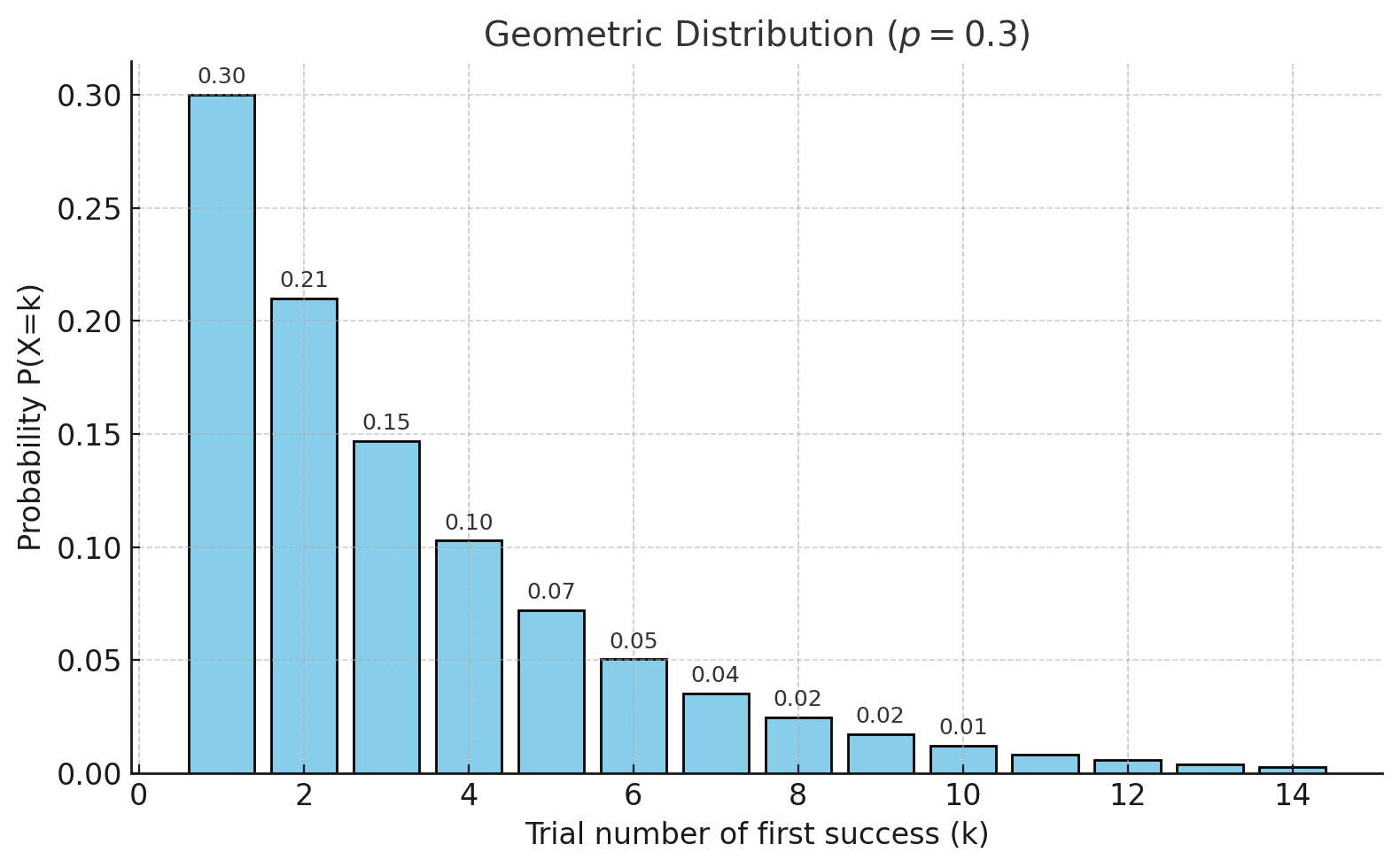
위 그림은 성공 확률 \(p = 0.3\)일 때의 기하분포 확률질량함수(PMF)를 보여준다.
가로축은 첫 성공이 일어나기까지의 시행 횟수 \(k\), 세로축은 확률 \(P(X=k)\)를 의미한다.
막대의 높이는 정확히 \(k\)번째 시행에서 첫 성공이 일어날 확률을 나타내며,
성공이 빨리 나올수록 확률이 크고, 시행이 길어질수록 확률이 등비수열 꼴로 감소한다.
기하분포와 '기하'라는 표현의 의미
기하분포에서 기하(幾何, geometric)라는 용어는 우리가 흔히 생각하는 기하학(geometry)에서 나온 것이 아니다.
여기서의 '기하'는 기하급수(geometric series, 등비급수) 를 의미한다.
기하분포의 확률질량함수는 다음과 같이 정의된다.
이 식에서 \((1-p)^{k-1}\) 항은 등비수열(geometric sequence) 의 형태를 가진다. 따라서 기하분포의 확률값들은 \(k\)가 증가함에 따라 등비적으로 감소하게 된다.
또한 모든 확률의 합은 다음과 같이 계산된다.
여기서 사용된 공식 역시 등비급수의 합 공식이다.
따라서 기하분포는 확률값이 등비급수적으로 분포한다는 특징 때문에 '기하분포'라는 이름이 붙었다.
정리하면, 기하분포의 '기하'는 등비급수와 밀접한 관련이 있는 개념이지, 기하학적 의미의 'geometry'와는 전혀 다른 맥락에서 사용되는 용어이다.
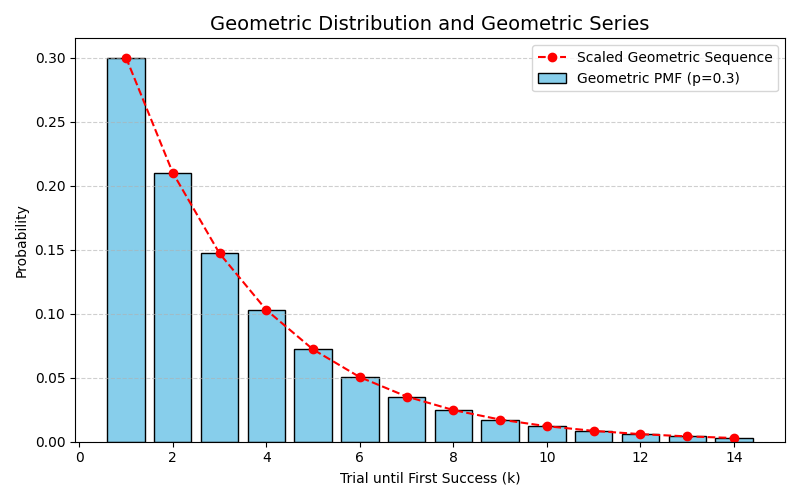
기하분포의 확률질량함수(PMF)를 성공 확률 \(p=0.3\)으로 나타낸 것이다.
막대그래프는 각 시행 횟수 \(k\)에서 처음으로 성공할 확률을 보여주며, 확률 값들이 \(k\)가 증가할수록 등비급수적으로 감소하는 모습을 확인할 수 있다.
빨간 점선은 등비수열 \((1-p)^{k-1}\)에 비례하는 항을 나타내며, 기하분포의 확률들이 바로 이 등비급수의 형태를 따른다는 사실을 직관적으로 보여준다.
기하분포에서 왜 첫 번째 성공 확률이 가장 높은가?
기하분포에서 확률질량함수는 다음과 같이 정의된다.
이는 "처음 \(k-1\)번은 실패하고, \(k\)번째에 처음 성공할 확률"을 의미한다.
-
\(k=1\): 곧바로 성공할 확률은 단순히 \(p\)이다.
-
\(k=2\): 첫 번째는 반드시 실패 \((1-p)\), 두 번째는 성공 \((p)\)이 되어야 하므로 \(P(X=2) = (1-p)p\)가 된다. 이는 \(p\)보다 작다.
-
\(k=3\): 앞의 두 번은 모두 실패하고, 세 번째에 성공해야 하므로 \((1-p)^2p\)로 더 줄어든다.
따라서 조건이 늘어날수록 만족하기가 점점 어려워져서, 처음 성공할 확률이 가장 높고 이후로 갈수록 확률은 등비적으로 감소한다.
"많이 시행하면 성공할 확률이 높아진다"와의 차이
-
우리가 흔히 말하는 "많이 하면 언젠가는 성공한다"는 것은 누적 확률(CDF) 을 뜻한다.
-
예를 들어, "3번 안에 한 번은 성공할 확률"은 다음과 같다.
이는 단순히 \(p\)보다 크다.
반대로, "정확히 3번째에 첫 성공할 확률"은 다음과 같이 계산된다.
이는 \(p\)보다 작다.
따라서,
-
개별 사건 확률(PMF): 특정 횟수에 '딱' 성공 → \(k\)가 커질수록 작아진다.
-
누적 확률(CDF): 일정 횟수 안에 '한 번이라도' 성공 → 시행이 많아질수록 1에 가까워진다.
간단한 예시 (성공 확률 \(p=0.5\))
-
\(P(X=1) = 0.5\)
-
\(P(X=2) = 0.25\)
-
\(P(X=3) = 0.125\)
즉, 첫 시도에 성공할 확률이 가장 크고, 뒤로 갈수록 점점 줄어든다.
그러나 3번 안에 한 번이라도 성공할 확률은 다음과 같다.
이는 훨씬 커진 값이다.
-
PMF는 특정 횟수에 '딱' 성공할 확률 → 시행 횟수가 커질수록 확률은 감소한다.
-
CDF는 일정 횟수 안에 '한 번이라도' 성공할 확률 → 시행이 많아질수록 1에 가까워진다.
기하분포의 특징
-
시행은 독립적이며, 각 시행의 성공 확률 \(p\)는 동일하다.
-
평균과 분산은 다음과 같다.
-
평균: \(E[X] = \frac{1}{p}\)
-
분산: \(Var[X] = \frac{1-p}{p^2}\)
-
-
성공할 확률이 \(p\)일 때, 평균적으로 \(1/p\) 번의 시행을 하면 성공이 나타난다.
-
기억 없음 성질(Memoryless Property):
-
\(P(X > s + t \mid X > s) = P(X > t)\) 가 성립한다.
-
이미 \(s\)번 실패했더라도 앞으로 성공할 확률 분포는 여전히 동일하다.
-
사용하는 분야
-
산업: 제품 테스트에서 첫 불량이 발견될 때까지 검사하는 횟수
-
서비스: 고객이 처음으로 특정 서비스를 이용할 때까지 걸리는 시도 횟수
-
통신: 데이터 전송에서 첫 오류가 발생하기까지의 패킷 수
기하분포는 첫 성공이 나타날 때까지 걸린 시행 횟수를 다루며,
실험적 상황뿐 아니라 강화학습, 시뮬레이션, 불균형 데이터 분석 등 인공지능에서도 중요한 개념으로 활용된다.
연속형 확률분포 (Continuous Probability Distribution)
연속형 확률분포란 확률변수가 특정 구간 안에서 무수히 많은 값을 가질 수 있는 경우에 해당한다. 즉, 확률변수가 연속적인 실수 값을 취할 수 있으며, 그 값들은 하나하나 셀 수 없을 정도로 무한히 많다. 따라서 연속형 확률변수에서는 개별 값에 확률을 부여할 수 없고, 오직 구간에 대해 확률을 정의할 수 있다.
연속형 확률분포에서는 특정 값 하나가 나올 확률은 항상 0이며, 확률은 확률밀도함수(pdf)를 적분하여 구간 단위로 계산한다. 예를 들어 온도, 키, 몸무게, 시간과 같은 데이터는 연속적으로 측정되기 때문에 연속형 확률변수로 다루게 된다. 확률분포 곡선 아래 면적이 전체 확률을 나타내며, 전체 면적은 항상 1이 된다.
가장 대표적인 연속형 확률분포는 정규분포로, 평균을 중심으로 좌우 대칭을 이루는 종 모양의 곡선을 가진다. 정규분포는 자연 현상이나 사회 현상에서 관측되는 많은 데이터들이 따르는 분포라고 가정되며, 모수로는 평균과 표준편차가 있다. 또한 표본의 크기가 작거나 모분산을 알 수 없는 경우에는 t-분포가 자주 활용된다. t-분포는 자유도가 커질수록 정규분포에 가까워지며, 평균 차이에 대한 가설검정에서 중요한 역할을 한다.
연속형 확률분포는 값이 연속적으로 정의되는 확률변수를 다루며, 특정 값 자체보다는 구간에 대한 확률로 해석한다. 대표적인 예로 정규분포, t-분포, 카이제곱분포, F-분포 등이 있으며, 통계적 추론에서 매우 중요한 역할을 한다.
확률밀도함수 (Probability Density Function, PDF)
확률밀도함수(PDF)는 연속형 확률변수가 특정 구간에 속할 확률을 나타내는 함수이다. 연속형 확률변수는 특정 값 하나에 대한 확률이 0이므로, \(P(X = x)\) 형태로는 의미가 없다. 대신, PDF \(f(x)\)는 값의 "밀도(density)"를 표현하며, 구간 단위의 확률을 적분을 통해 계산한다.
연속형 확률변수 \(X\)의 확률밀도함수는 다음 성질을 가진다.
- 모든 값에 대해 음수가 아니다.
$$ f(x) \geq 0 $$
- 전체 영역에 대한 확률은 1이다.
$$ \int_{-\infty}^{\infty} f(x) \, dx = 1 $$
- 임의의 구간 \(a \leq X \leq b\)에 대한 확률은 다음과 같이 계산된다.
$$ P(a \leq X \leq b) = \int_a^b f(x) \, dx $$
예시
-
정규분포 \(X \sim \mathcal{N}(\mu, \sigma^2)\)의 PDF는 다음과 같다. $$ f(x) = \frac{1}{\sqrt{2\pi}\,\sigma} \exp!\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) $$
-
특정 점 하나의 확률 \(P(X = \mu)\)는 0이지만, "평균 주변 ±1σ 구간"에 속할 확률은 $$ P(\mu-\sigma \leq X \leq \mu+\sigma) \approx 0.68 $$ 이다.
정리
-
PDF는 연속형 확률변수의 분포를 설명하는 기본 도구이다.
-
PMF가 "점 단위 확률"이라면, PDF는 "구간 단위 확률"을 정의한다.
-
따라서 PDF는 연속형 데이터 분석과 통계적 추론의 출발점이다.
정규분포 (Normal Distribution)
정규분포는 연속형 확률분포의 대표로, 평균을 중심으로 좌우가 대칭인 종(bell) 모양의 밀도 곡선을 갖는다. 자연·사회에서 관측되는 많은 측정값(키, 시험 점수, 센서 노이즈 등)이 여러 요인의 작은 영향이 합쳐져 나타날 때 정규분포로 잘 근사된다. 또한 중심극한정리(CL T)에 의해 적당한 조건에서 표본평균의 분포가 정규분포로 수렴하므로, 통계적 추론의 핵심적 기반이 된다.
수식(밀도함수, PDF) 평균이 \(\mu\), 분산이 \(\sigma^2\)인 정규분포 \(X \sim \mathcal{N}(\mu,\sigma^2)\)의 확률밀도함수는
표준정규분포는 \(\mu=0,\ \sigma=1\)인 경우로 \(Z\sim\mathcal{N}(0,1)\)이라 쓴다. 누적분포함수(CDF)는
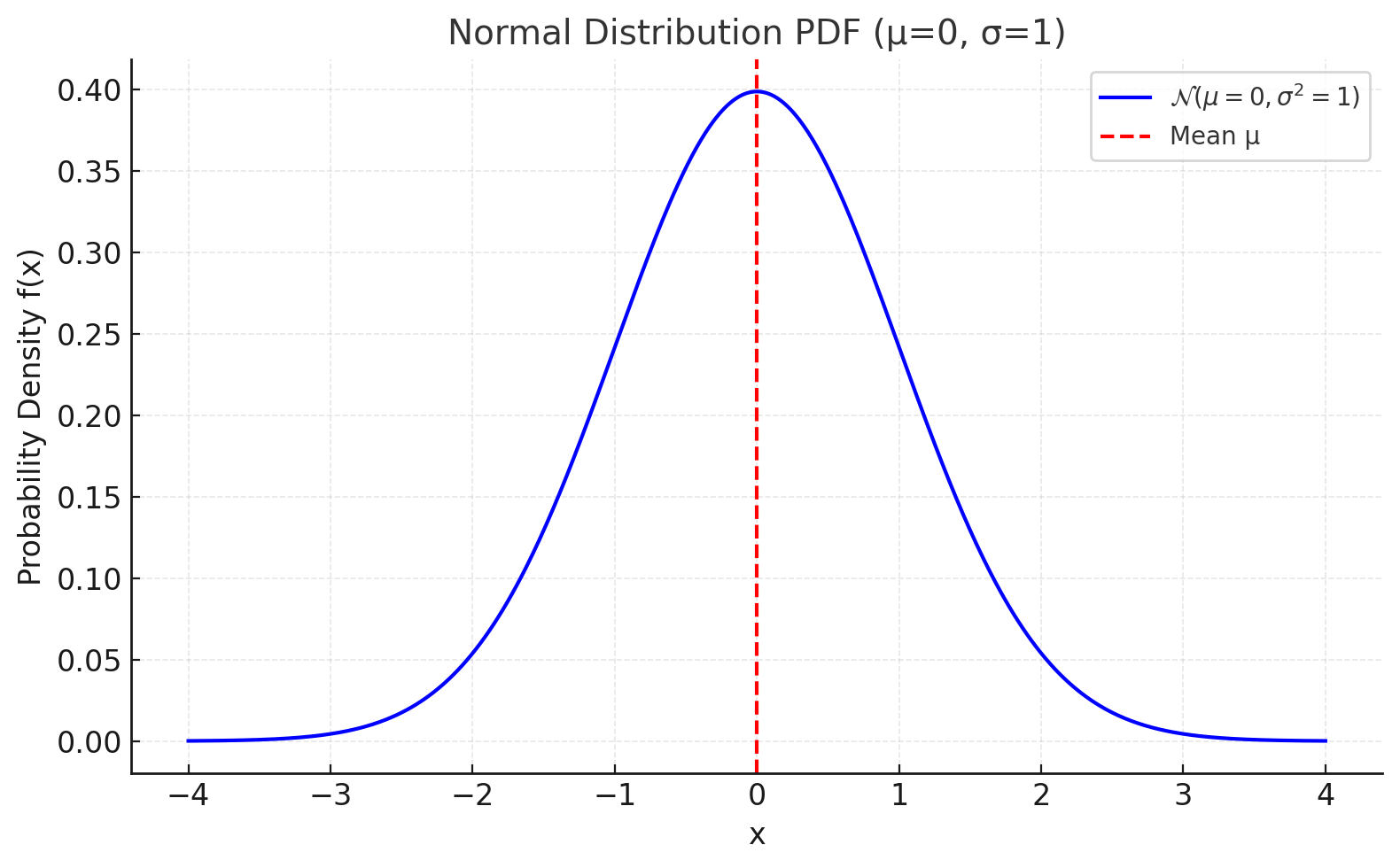
위 그림은 평균 \(\mu = 0\), 분산 \(\sigma^2 = 1\)인 표준정규분포의 확률밀도함수(PDF)를 보여준다.
파란 곡선은 종 모양의 대칭 분포를 나타내며, 붉은 점선은 평균 위치를 표시한다.
정규분포는 평균을 중심으로 값이 집중되어 있고, 좌우로 멀어질수록 확률밀도가 급격히 줄어드는 특징을 가진다.
정규분포와 가우시안분포의 비교
정규분포(Normal Distribution)와 가우시안분포(Gaussian Distribution)는 사실상 같은 확률분포를 가리키는 용어이다. 두 용어는 수학적 정의나 성질에서 차이가 없으며, 사용되는 맥락과 전통에 따라 이름만 다르게 불린다.
정규분포(Normal Distribution)는 통계학에서 주로 사용하는 용어이다. 19세기 카를 피어슨(Karl Pearson)이 여러 분포를 체계적으로 정리하면서, 자연 현상에서 가장 보편적이고 정상적(normal)이라고 여겨진 분포라는 의미에서 "정규분포"라는 이름이 붙었다. 통계학 교재나 응용 분야(심리학, 사회과학 등)에서는 일반적으로 "정규분포"라는 용어가 더 익숙하다.
가우시안분포(Gaussian Distribution)는 수학·공학·물리학에서 더 자주 사용되는 용어이다. 독일 수학자 카를 프리드리히 가우스(Carl Friedrich Gauss)가 천문학 데이터의 오차 분포를 연구하면서 이 분포를 공식화한 데서 유래하였다. 신호 처리, 영상 처리, 머신러닝 등 공학적 맥락에서는 "가우시안 분포"라는 표현이 널리 쓰인다.
정리하면, 정규분포와 가우시안분포는 완전히 동일한 분포를 가리킨다. "정규분포"라는 명칭은 통계학적 전통에서, "가우시안분포"라는 명칭은 수학적·공학적 전통에서 주로 사용되며, 맥락에 따라 달리 쓰일 뿐 수식과 성질은 완전히 같다.
표준화(Z-점수) 정규분포 \(X\)를 표준정규분포로 바꾸는 표준화는
이며 임계값·구간확률 계산에 널리 사용된다. 경험적 규칙(68–95–99.7 법칙):
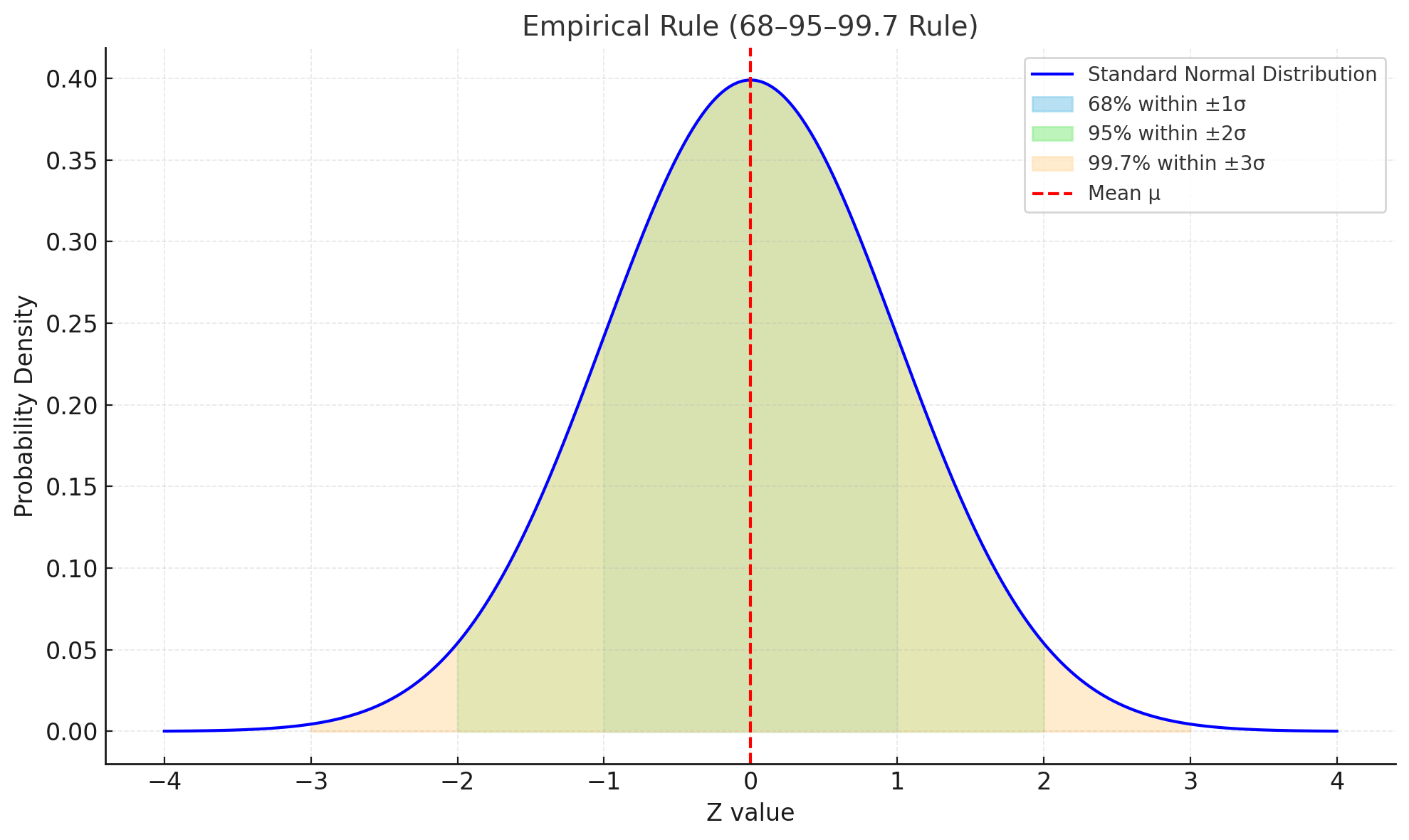
위 그림은 표준정규분포 \(\mathcal{N}(0,1)\)에서 경험적 규칙(68–95–99.7 법칙)을 시각화한 것이다.
붉은 점선은 평균(0)을 나타내며, 색깔로 구분된 영역은 각각 다음 확률을 의미한다.
-
하늘색: \(±1\sigma\) 구간 (약 68%)
-
연두색: \(±2\sigma\) 구간 (약 95%)
-
주황색: \(±3\sigma\) 구간 (약 99.7%)
즉, 표준정규분포에서 데이터의 대부분은 평균을 중심으로 좁은 구간 안에 존재하며, 구간이 넓어질수록 더 많은 확률이 포함됨을 보여준다.
정규분포의 성질
-
대칭성: 평균 \(\mu\)를 중심으로 좌우 대칭, 왜도는
0. -
선형결합의 폐포성: \(X_i\sim\mathcal{N}(\mu_i,\sigma_i^2)\)가 독립이면 \(aX_1+bX_2\)도 정규분포, 폐포성(closure)이란 수학에서 어떤 연산을 해도 그 결과가 다시 같은 집합 안에 머문다는 성질을 의미함.
-
모집단에서 데이터를 여러 개를 뽑아 평균을 계산하면 그 평균값 자체도 확률변수가 되며 정규분포를 따름. 예를 들어 \(X_1, X_2, \cdots, X_n\)이 독립이고 \(X_i\sim\mathcal{N}(\mu_i,\sigma_i^2)\) 이라면 표본평균 \(\bar X = \frac{1}{n}\sum_{i=1}^n X_i\)도 정규분포를 따른다. 이 때 \(\bar X\)의 분포는 다음과 같다.
$$ X_i\sim\mathcal{N}(\mu_i, \frac{\sigma_i^2}{n}), $$
$$ 표본 크기가 커질수록 분산이 줄어들어 평균 추정이 더 정밀해진다는 의미 $$
-
근사: \(n\)이 크고 \(p\)가 극단적이지 않으면 이항분포 \(\text{Bin}(n,p)\)는 \(\mathcal{N}(np,\ np(1-p))\)로 근사.
-
최대엔트로피: 주어진 평균·분산 제약 하에서 엔트로피가 최대인 분포가 정규분포.
-
엔트로피(Entropy): 확률분포의 불확실성을 측정하는 척도
-
엔트로피가 높다는 것은 "결과를 예측하기 더 어렵다"는 의미, "가장 퍼저 있는 분포", 즉 "아무것도 가정하지 않는 상태에서의 분포"
-
우리가 평균, 표준편차만 알고 그 외에 아무 정보도 없다면, 이 데이터의 확률 분포를 어떤 것이라고 가정할 수 있을까?
-
정규분포는 평균과 표준편차 이외에는 어떤 가정이나 패턴을 적용하지 않으므로 가장 퍼저있는(불확실성이 높은) 분포이므로 정규분포를 가정하고 문제를 풀게 됨.
-
내가 수집한 데이터가 어떤 분포를 가지는지 알 수 없다. 이 경우 대부분은 정규분포를 따른다고 가정하면 대부분 문제를 풀 수 있다.
-
인공지능/데이터사이언스에서의 정규분포 활용
-
회귀의 손실함수 해석: 관측오차가 \(\mathcal{N}(0,\sigma^2)\)라고 가정하면 MSE가 정규우도(음의 로그우도)와 동치이다.
- 선형회귀에서는 예측값 \(\hat y\)와 실제값 \(y\)의 차이(오차)가 정규분포를 따른다고 가정한다.
정규분포의 확률밀도함수는 다음과 같다.
이 식의 로그를 취하고 부호를 바꾸면(= 음의 로그우도):
-
가우시안 나이브 베이즈: 연속 특성의 조건부분포를 정규로 가정해 사후확률 계산
-
가우시안 혼합모형(GMM): 여러 정규의 혼합으로 복잡한 분포 근사
-
딥러닝:
-
가중 초기화·배치정규화에서 활성 분포를 근사 정규로 가정하는 논리.
-
확산모형은 학습·샘플링 과정에 가우시안 노이즈를 점진적으로 주입/제거.
-
대표적인 최신 확산모형 비교 (SDXL vs SD3 vs Flux)
모델 발표 시기 기관/회사 특징 Stable Diffusion XL (SDXL) 2023 Stability AI - 오픈소스 텍스트-투-이미지 확산모델
- 뛰어난 해상도(1024×1024), 세밀한 컨트롤
- ControlNet, LoRA 등 커뮤니티 생태계 활성화Imagen / Imagen 2 2022~2024 Google DeepMind - 대규모 텍스트-이미지 모델
- 고해상도, 사실적 표현력 우수
- Imagen 2는 Parti와 결합해 향상된 세밀 묘사DALL·E 3 2023 OpenAI - GPT-4와 결합된 고품질 이미지 생성
- 프롬프트 해석 능력 강화, 복잡한 장면 표현 -
VAE (Variation Auto Encoder)에서 잠재변수 \(z\)의 사전분포는 \(p(z)=\mathcal{N}(0,I)\) 사용
- VAE(Variational Autoencoder)는 입력 데이터를 압축해 잠재공간(latent space)이라는 곳에 표현하고, 그 공간에서 다시 샘플링해 원래 데이터를 복원하는 방식의 생성모델이다.
-
정규분포는 “많은 작은 효과의 합”과 “표본평균의 한계분포”라는 두 축에서 등장하는 핵심 분포다. 계산이 폐포적이고(선형변환에 닫혀 있음) 해석적 도구(표준화, Z-점수, 근사)가 풍부해, 통계적 추론과 기계학습 알고리즘의 설계·해석에 폭넓게 사용된다.
t-분포 (Student’s t-Distribution)
t-분포는 표본 크기가 작거나 모분산을 알 수 없는 상황에서 평균에 대한 추론을 할 때 사용되는 연속형 확률분포이다.
정규분포와 비슷한 종 모양을 가지고 있지만, 꼬리가 더 두꺼워 극단값(이상치)에 대한 확률을 더 크게 부여한다.
자유도(degree of freedom)가 커질수록 정규분포에 점점 가까워지고, 자유도가 무한대에 수렴하면 정규분포와 동일해진다.
수식 (확률밀도함수, PDF)
자유도 \(v\)인 t-분포의 확률밀도함수는 다음과 같이 정의된다.
- \(v\): 자유도 (일반적으로 \(n-1\), 표본 크기 \(n\)일 때)
- \(\Gamma(\cdot)\): 감마 함수 (위키 보기)
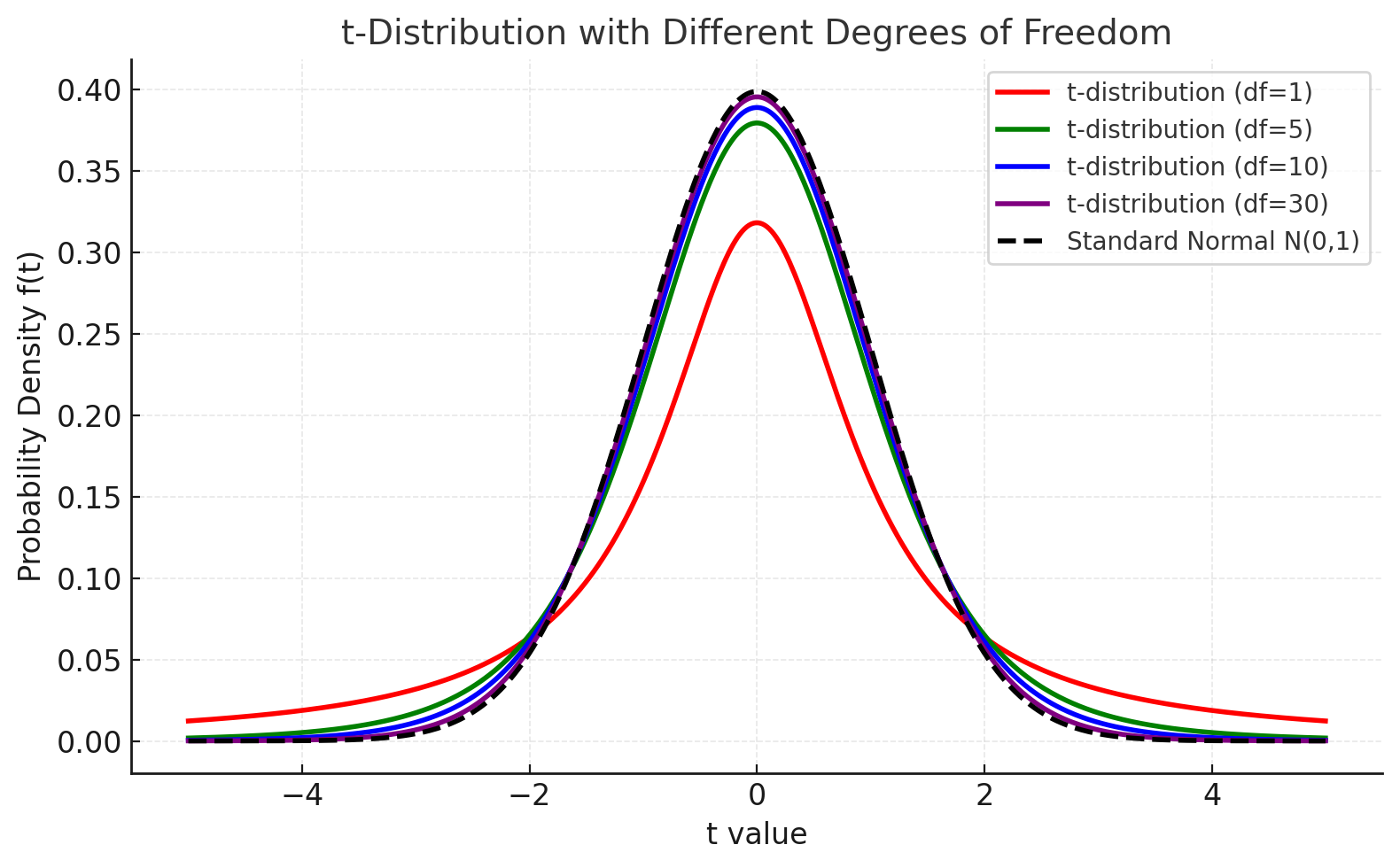
위 그림은 자유도(df)가 다른 t-분포의 확률밀도함수를 보여준다.
-
빨강, 초록, 파랑, 보라 곡선: 각각 자유도 1, 5, 10, 30의 t-분포
-
검은 점선: 표준정규분포 \(\mathcal{N}(0,1)\)
자유도가 작을수록 분포의 꼬리가 두껍게 나타나며, 표본 크기가 커져 자유도가 증가할수록
t-분포는 점점 정규분포에 가까워진다. 이는 표본이 많아질수록 추정이 안정된다는 사실을 반영한다.
자유도 (Degree of Freedom)
자유도는 통계학에서 데이터가 가질 수 있는 독립적인 정보의 개수를 의미한다.
즉, 전체 데이터 중에서 통계량을 계산할 때 제약 조건에 의해 자유롭게 변할 수 있는 값의 수라고 이해할 수 있다.
자유도에 대한 직관적으로 설명하면 다음과 같다.
-
표본의 크기가 \(n\)인 데이터가 있다고 하자.
-
이 데이터들의 평균 \(\bar{x}\)를 이미 알고 있다면, \(n-1\)개의 값이 정해지면 마지막 값은 자동으로 결정된다.
-
따라서 평균을 계산할 때 자유롭게 선택할 수 있는 값은 \(n-1\)개이며, 이를 자유도라고 한다.
자유도에 대한 구체적인 예시 (데이터 3개, 자유도 = 2)
예를 들어, 표본 데이터가 3개 있다고 하자. $$ x_1, \; x_2, \; x_3 $$
이때 표본평균 \(\bar{x}\)가 주어져 있다면 다음 제약 조건이 성립한다.
즉, \(x_1\)과 \(x_2\) 값을 자유롭게 정하면 \(x_3\) 값은 자동으로 결정된다. 따라서 세 데이터 중 실제로 자유롭게 선택할 수 있는 값은 2개이고, 자유도는 \(3-1=2\)가 된다.
수학적 정의
자유도는 보통 데이터 개수 \(n\)에서 제약 조건의 수를 뺀 값으로 정의된다.
평균을 알고 있는 상황에서는 제약 조건이 1개 있으므로 자유도는 \(n-1\)이 된다.
통계에서의 활용
- 표본 분산: 분모를 \(n-1\)로 나누는 이유는 자유도를 고려하기 때문이다. $$ s^2 = \frac{1}{n-1} \sum_{i=1}^n (x_i - \bar{x})^2 $$ 여기서 자유도 \(n-1\)을 사용해야 불편추정량(unbiased estimator)이 된다.
추정량(estimator)이란 모수(parameter)를 추정하기 위해 표본 데이터로 계산하는 통계량을 말한다. 예를 들어, 모평균 \(\mu\)를 추정하기 위해 표본평균 \(\bar{x}\)를 사용하거나, 모분산 \(\sigma^2\)을 추정하기 위해 표본분산 \(s^2\)을 사용하는 것이 추정량의 예이다.
불편추정량(unbiased estimator)이란 표본으로 계산한 추정량의 평균이 실제 모수와 일치하는 경우를 말한다. 즉, 표본을 무한히 많이 뽑아서 추정량을 계산했을 때, 그 기대값이 모수에 정확히 일치한다면 그 추정량을 불편추정량이라고 한다.
중심극한정리
개념
중심극한정리(Central Limit Theorem, CLT)는 통계학의 핵심 정리로, 표본의 크기가 충분히 크다면 모집단의 분포가 어떤 형태이든지 표본평균의 분포는 정규분포에 가까워진다는 내용을 담고 있다. 즉, 원래 데이터가 정규분포가 아니어도, 표본평균을 반복해서 구하면 그 값들의 분포가 점점 정규분포로 수렴한다.
수식
독립이고 동일한 분포(i.i.d.)를 따르는 확률변수 \(X_1, X_2, \ldots, X_n\)이 기댓값 \(E[X_i] = \mu\), 분산 \(Var(X_i) = \sigma^2\)를 가질 때,
표본평균
즉, \(n\)이 커질수록 표본평균의 표준화된 분포는 표준정규분포에 수렴한다.
직관적인 이해
-
주사위를 던지는 실험에서 한 번 던질 때의 결과는 균등분포(1~6)이다.
-
하지만 주사위를 30번 던져 평균을 구하는 실험을 수천 번 반복하면, 이 평균들의 분포는 종(bell) 모양의 정규분포 형태에 가까워진다.
-
즉, 원래 데이터의 분포가 어떤 모양이든 간에, 평균값의 분포는 정규분포로 수렴한다.
언제, 어떻게 사용되는가 (사례)
일반 통계 분석
-
표본 기반 추정
예를 들어, 전국 고등학생의 평균 키를 알고 싶을 때 모든 학생을 측정할 수는 없다.
표본 1,000명을 뽑아 평균을 계산하면, 그 평균은 정규분포를 따른다고 가정할 수 있어 신뢰구간이나 가설검정에 정규분포를 사용할 수 있다.
-
품질 관리 (Quality Control)
공장에서 생산된 부품의 길이가 일정하지 않을 때, 표본을 일정 개수씩 뽑아 평균을 측정하면 그 분포가 정규분포에 근사한다.
이를 통해 공정의 이상 여부를 통계적으로 판정할 수 있다.
인공지능(AI)에서의 적용 사례
-
모델 성능 추정 및 불확실성 추정
모델의 예측값에 대한 평균 손실(loss)을 여러 배치에서 측정하면, 개별 손실의 분포가 어떻든 간에 배치 평균 손실은 정규분포로 근사할 수 있다.
평균 성능의 신뢰구간을 구하거나 모델 간 성능 비교 시 통계적 유의성을 평가할 수 있다.
-
배치 정규화(Batch Normalization)
미니배치(batch)마다 평균과 분산을 계산해 정규화할 때, 각 배치의 평균은 표본평균이다.
중심극한정리 덕분에 배치 평균이 정규분포에 근사한다고 보고 안정적으로 학습이 가능하다.
-
Ensemble/Bagging 성능 분석
여러 개의 모델을 앙상블할 때, 각 모델의 예측값이 서로 독립이라면 그들의 평균은 CLT에 의해 정규분포로 수렴한다.
데이터사이언스에서의 적용 사례
-
대규모 표본에서의 평균 추정
수집된 로그 데이터나 센서 데이터가 정규분포를 따르지 않더라도, 표본 평균을 이용한 추정에서는 CLT를 적용해 정규 근사를 사용한다.
예를 들어, 하루 평균 트래픽, 평균 체류 시간 등을 계산할 때 정규분포 근사를 이용해 신뢰구간을 구할 수 있다.
-
통계적 가설검정
데이터의 원래 분포를 모르더라도, 충분한 표본 크기에서 표본평균의 분포를 정규로 근사해 t-검정, z-검정 등을 적용한다.
추정
데이터 분석의 중요한 목표 중 하나는 표본(sample)으로부터 모집단(population)의 특성을 추론하는 것이다. 이 과정에서 사용되는 핵심 개념이 추정(Estimation)이다. 추정은 관측된 표본 데이터를 이용해 모집단의 모수(parameter)를 예측하는 절차를 의미한다.
예를 들어, 한 학교 전체 학생의 평균 키를 알고 싶을 때 모든 학생을 조사하는 것은 현실적으로 불가능하다. 대신 일부 학생(표본)의 키를 측정하여 이를 바탕으로 전체 평균을 추정하게 된다.
점추정 (Point Estimation)
점추정은 모수(parameter)의 값을 하나의 구체적인 수치(점) 로 추정하는 방법이다. 예를 들어, 모집단의 평균 \(\mu\)나 분산 \(\sigma^2\)와 같은 모수를 알 수 없을 때, 표본 데이터를 이용해 이를 하나의 값으로 추정하는 것이 점추정이다.
정의
점추정량(point estimator)은 표본 데이터의 함수로 정의되며, 이를 계산한 실제 값은 점추정치(point estimate)라고 부른다.
예를 들어,
-
표본평균 \(\bar{x}\)는 모평균 \(\mu\)의 점추정량이다.
-
표본분산 \(s^2\)는 모분산 \(\sigma^2\)의 점추정량이다.
성질
좋은 점추정량은 다음과 같은 성질을 만족하는 것이 바람직하다.
-
불편성(Unbiasedness) 추정량의 기댓값이 모수와 일치해야 한다. $$ E[\hat{\theta}] = \theta $$
-
일치성(Consistency) 표본의 크기 \(n\)이 커질수록 추정량이 모수에 점점 가까워져야 한다.
-
효율성(Efficiency) 같은 모수를 추정하는 여러 불편추정량 중에서, 분산이 가장 작은 추정량이 더 효율적이다.
-
충분성(Sufficiency) 표본 데이터 안에서 모수에 대한 정보를 온전히 담고 있는 추정량일수록 충분하다.
점추정 예시
-
어떤 학교 학생들의 평균 키를 알고 싶을 때, 전체 학생을 조사할 수 없다면 표본 50명을 뽑아 평균 키를 계산한다. 이때 표본평균 \(\bar{x}\)는 모평균 \(\mu\)의 점추정량이며, 계산된 값이 점추정치가 된다.
-
제조업 공정에서 제품 무게의 분산을 알고 싶을 때, 30개 제품을 뽑아 분산을 계산하면 표본분산 \(s^2\)이 모분산 \(\sigma^2\)의 점추정량이 된다.
점추정 요약
점추정은 모집단의 모수를 하나의 수치로 추정하는 가장 기본적인 방법이다.
하지만 점추정치 하나만으로는 추정의 불확실성을 알 수 없기 때문에,
실제 통계적 추론에서는 구간추정(Interval Estimation)과 함께 사용되어 신뢰도를 보완한다.
구간추정 (Interval Estimation)
구간추정은 모수(parameter)의 값을 하나의 수치로 추정하는 점추정과 달리,
모수가 포함될 가능성이 높은 구간(interval)을 제시하는 방법이다.
즉, 추정값에 대한 불확실성을 반영하여 “모수가 이 구간 안에 있을 것이다”라는 형태로 표현한다.
정의
구간추정에서는 보통 신뢰구간(confidence interval, CI) 을 사용한다.
신뢰구간은 모수 \(\theta\)에 대한 추정량 \(\hat{\theta}\)를 중심으로, 일정한 신뢰수준(confidence level) 하에서 계산된 구간이다.
신뢰구간 (Confidence Interval)
신뢰구간은 구간추정의 구체적인 방법으로, 모집단의 모수가 포함될 가능성이 높은 구간을 제시한다.
점추정이 단일 값만을 제공한다면, 신뢰구간은 추정값 주위에 불확실성을 반영하여 “모수가 이 구간 안에 있을 것이다”라는 정보를 제공한다.
통계적 추론에서 신뢰구간은 매우 중요한 개념으로, 연구자가 추정의 신뢰도를 제시할 수 있게 해준다.
모수 \(\theta\)에 대한 추정량 \(\hat{\theta}\)가 있을 때, 신뢰수준 \(1-\alpha\)로 정의되는 신뢰구간은 다음과 같다.
신뢰구간의 해석
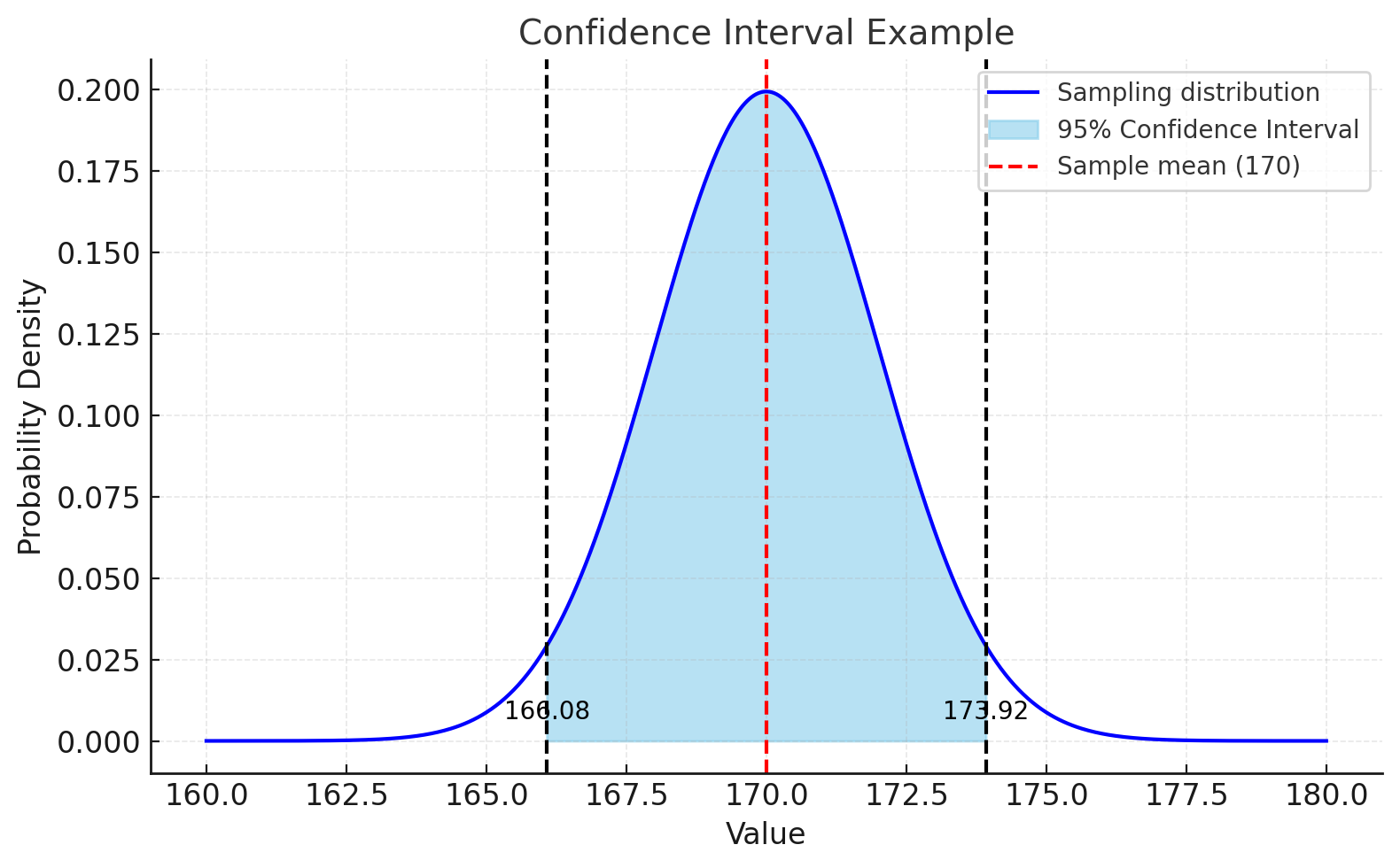
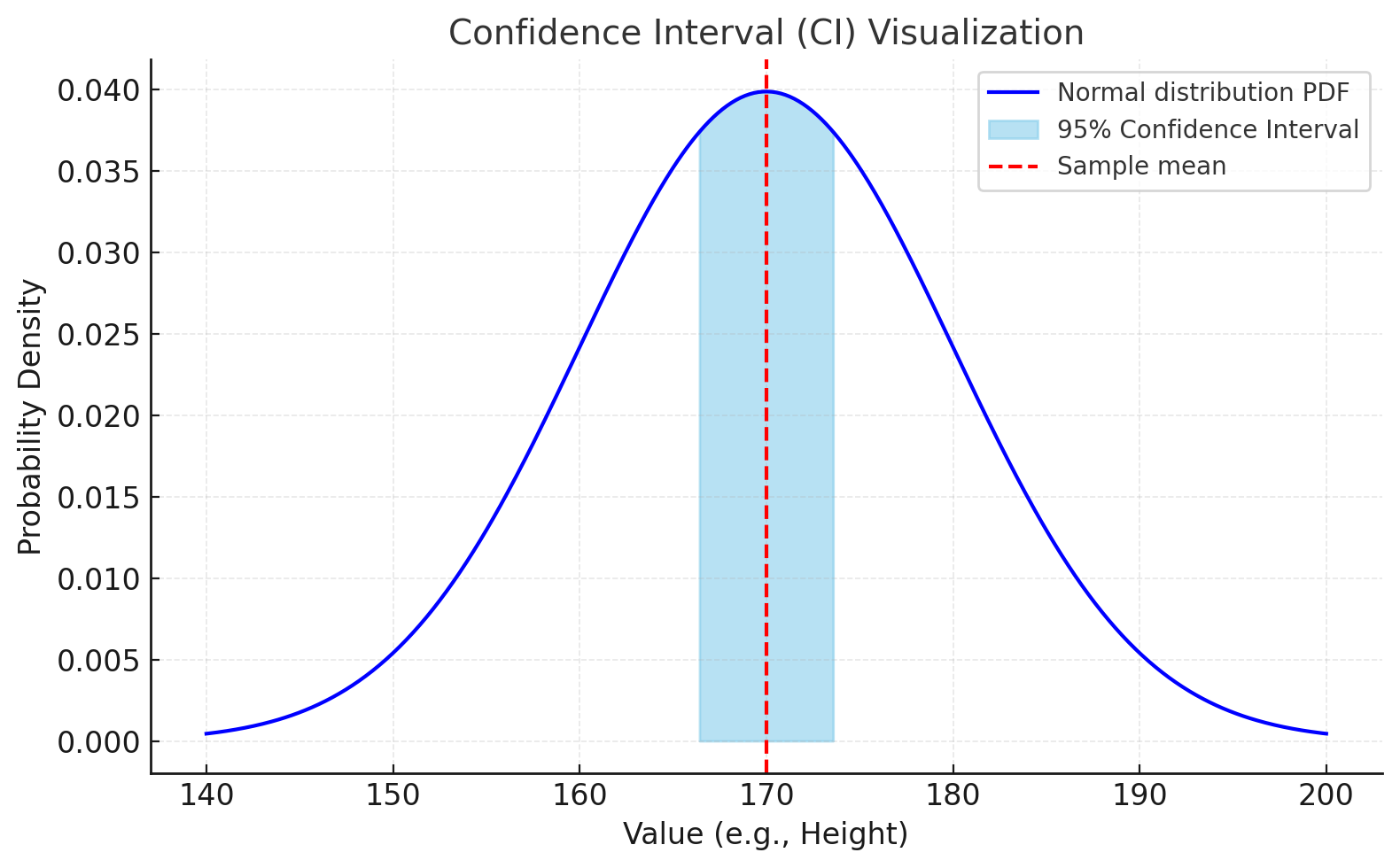
예를 들어, 모평균 \(\mu\)의 95% 신뢰구간이 [166.08, 173.92]라고 한다면,
“\(\mu\)가 이 구간 안에 있을 확률이 95%다”라고 해석하는 것이 아니라,
“같은 방식으로 표본을 무수히 반복 추출하여 신뢰구간을 만들면, 그 중 약 95%가 실제 모평균을 포함한다”라고 해석해야 한다.
신뢰수준을 산출하는 방법
표본평균 \(\bar{x}\), 표본표준편차 \(s\), 표본크기 \(n\)이 주어졌을 때 모평균 \(\mu\)의 신뢰구간은
-
모분산을 모르는 경우 (t-분포 사용) $$ \bar{x} \pm t_{\alpha/2, n-1} \cdot \frac{s}{\sqrt{n}} $$
-
모분산을 아는 경우 (정규분포 사용) $$ \bar{x} \pm z_{\alpha/2} \cdot \frac{\sigma}{\sqrt{n}} $$
-
\(z_{\alpha/2}\) (표준정규분포 임계값)
-
모집단 분산 \(\sigma^2\)를 알고 있거나, 표본 크기 \(n\)이 충분히 클 때 사용한다.
-
표준정규분포 \(\mathcal{N}(0,1)\)에서 양쪽 꼬리 부분의 확률이 \(\alpha/2\)가 되도록 하는 임계값이다.
-
예: 신뢰수준 95%일 때 \(z_{0.025} = 1.96\)
-
\(z\) 값은 표준정규분포에서 임계값을 가져오며, 모집단 분산을 알고 있거나 표본이 충분히 클 때 사용한다.
-
-
\(t_{\alpha/2, n-1}\) (t-분포 임계값)
-
모집단 분산을 모르고, 표본 크기가 작을 때 사용한다.
-
자유도 \(n-1\)인 t-분포에서 양쪽 꼬리 확률이 \(\alpha/2\)가 되도록 하는 임계값이다.
-
표본이 작을수록 꼬리가 두꺼워져 \(t\) 값이 \(z\) 값보다 크다.
- 예: \(n=10\), 신뢰수준 95%일 때 \(t_{0.025, 9} \approx 2.262\)
- 예: \(n=10\), 신뢰수준 95%일 때 \(t_{0.025, 9} \approx 2.262\)
-
\(t\) 값은 자유도에 따라 달라지는 t-분포의 임계값을 사용하며, 표본이 작고 모집단 분산을 모를 때 사용한다.
-
-
표본이 커질수록 \(t\) 값은 \(z\) 값에 가까워져, 결국 두 값은 동일하게 수렴한다.
-
유의수준 \(\alpha\)의 의미
-
신뢰구간에서 \(\alpha\)는 유의수준(significance level) 을 나타낸다.
-
이는 곧 “실제 모수가 신뢰구간 밖에 있을 확률”을 의미한다.
-
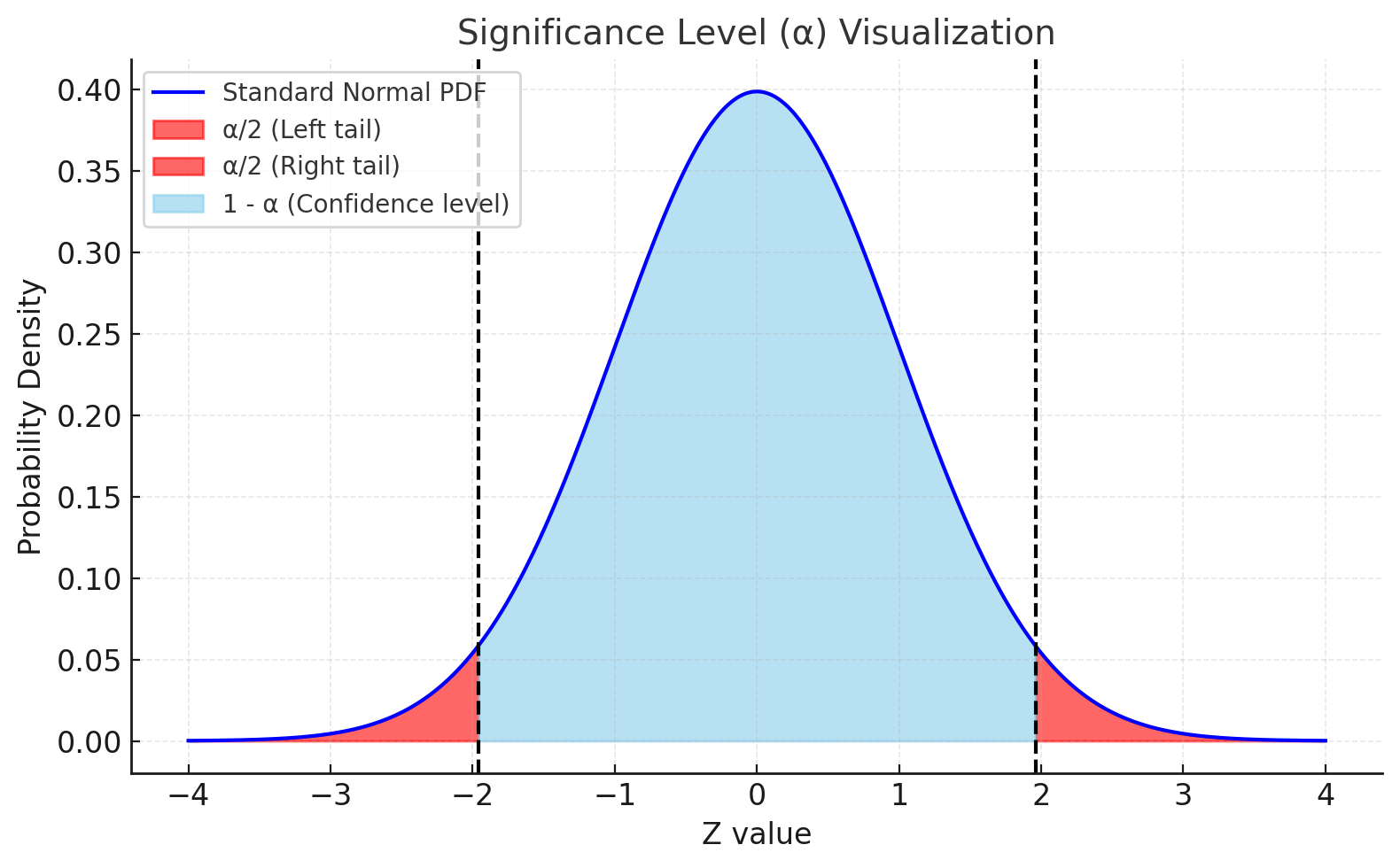
신뢰수준(confidence level)은 \(1 - \alpha\)로 표현된다.
예를 들어, 신뢰수준이 95%라면 유의수준 \(\alpha = 0.05\)이고, 이는 모수가 구간 밖에 있을 확률이 5%라는 뜻이다.
-
\(\alpha = 0.05\) (신뢰수준 95%)
- 100번의 표본 추출로 신뢰구간을 만들면, 그 중 약 95개의 구간은 실제 모수를 포함하고, 약 5개의 구간은 모수를 포함하지 못한다.
-
\(\alpha = 0.01\) (신뢰수준 99%)
- 훨씬 더 신뢰할 수 있는 구간을 제공하지만, 대신 구간이 더 넓어진다.
-
정리
-
\(\alpha\) 값: 신뢰구간이 실제 모수를 포함하지 못할 확률
-
\(1-\alpha\) 값: 신뢰구간이 실제 모수를 포함할 확률 (신뢰수준)
-
\(\alpha\) 값이 작을수록 구간은 넓어지고, 더 높은 신뢰를 제공한다.
-
신뢰수준의 특징
-
표본의 크기가 커질수록 신뢰구간은 짧아져 추정이 정밀해진다.
-
신뢰수준을 높이면 구간이 넓어져, 더 많은 불확실성을 허용한다.
-
점추정과 함께 제시되어야 추정의 의미가 명확해진다.
-
데이터 사이언스 담당자가 단순히 추정치 하나만 제시하는 대신, 신뢰구간을 함께 제공하면 결과의 신뢰성과 설득력이 크게 높아진다.
신뢰구간 구하는 예시
대한민국 군인 모집단 6만 명의 평균 키 \(\mu\)를 추정할 때, 육군 10,000명의 표본을 구성하여 측정한 평균(\(\bar{x}\))은 170cm 이고, 표준편차가 2cm인 경우라고 하자.
95% 신뢰구간(유의수준 \(\alpha = \,\) 0.05)은 다음과 같이 계산한다.
실제로는 모집단을 표준편차를 모르기 때문에 t 분포를 사용한다.
앞서 배운 것과 같이 t 분포는 모집단의 표준편차를 모를 때, 대신 표본으로부터 표준편차를 추정해서 사용하는 분포이다.
이때 표본 크기 n이 작으면, 표본 표준편차의 불확실성이 커서 꼬리가 두꺼운 분포(heavy tail) 인 t 분포를 사용해야 한다.
다시 말하면 표본이 작을수록 추정값의 변동성이 크기 때문에 표본수를 고려해야 한다.
하지만 표본 크기 n이 커질수록 표본 표준편차는 실제 모집단 표준편차에 점점 가까워지고,
t 분포는 정규분포와 거의 구분이 안 될 정도로 모양이 비슷해진다.
크기 n에 따른 일반적 해석은 다음과 같다.
| 자유도(df) | t 분포의 형태 | 정규분포와의 차이 |
|---|---|---|
| 5 | 꼬리가 매우 두꺼움 | 정규분포와 차이 큼 |
| 30 | 조금 두꺼움 | 어느 정도 근사 가능 |
| 100 이상 | 거의 정규분포와 동일 | \(z\)값과 \(t\)값 차이 미미 |
| 10,000 | 완전히 정규에 수렴 | \(t_{\alpha/2,9999} \approx 1.96\) |
실제로 샘플 수가 30개 이상이면, 복잡하게 t 값을 찾지 않고 정규분포(z 값)을 써도 충분히 정확한 신뢰구간 추정을 할 수 있다.
주어진 문제에서 자유도(n-1)가 매우 크기 (30 << n-1) 때문에 \(t_{\alpha/2,\,9999} \approx z_{\alpha/2} = 1.96\) 과 거의 동일하다.
따라서 정규분포를 사용해도 된다.
즉, \(170 \pm 1.96 \times 2 = [166.08, 173.92]\) 이 된다.
따라서 “대한민국 군인의 평균키(모평균 \(\mu\))는 95% 확률로 [166.08cm, 173.92cm] 구간 안에 있다”라고 해석한다.