Data Collection & Preprocessing
- 슬라이드 다운로드: click me
- Dataset 다운로드: click me (Password Required!)
- Password will be provided by the professor in offline.
첨부 슬라이드의 전체 흐름은 언어 데이터의 수집, 정제, 레이블링, 자연어의 모호성 이해, 그리고 분절(토크나이즈)까지의 전 과정을 체계화하는 데 목적을 둔다. 실제 프로젝트에서는 이 모든 단계가 하나의 반복적 파이프라인으로 실행되며, 각 단계는 다음 단계를 좌우하는 품질 관문 역할을 한다. 특히 대규모 웹-마이닝 코퍼스(Common Crawl, C4, The Pile 등)가 일반화되면서, 데이터 윤리·거버넌스와 중복 제거나 잡음 제거 같은 정제 이슈가 성능과 신뢰성에 미치는 영향이 커졌다. 아래에서는 해당 단계들을 통합적 관점에서 설명하고, 대표 사례와 최적 실무 팁을 정리한다
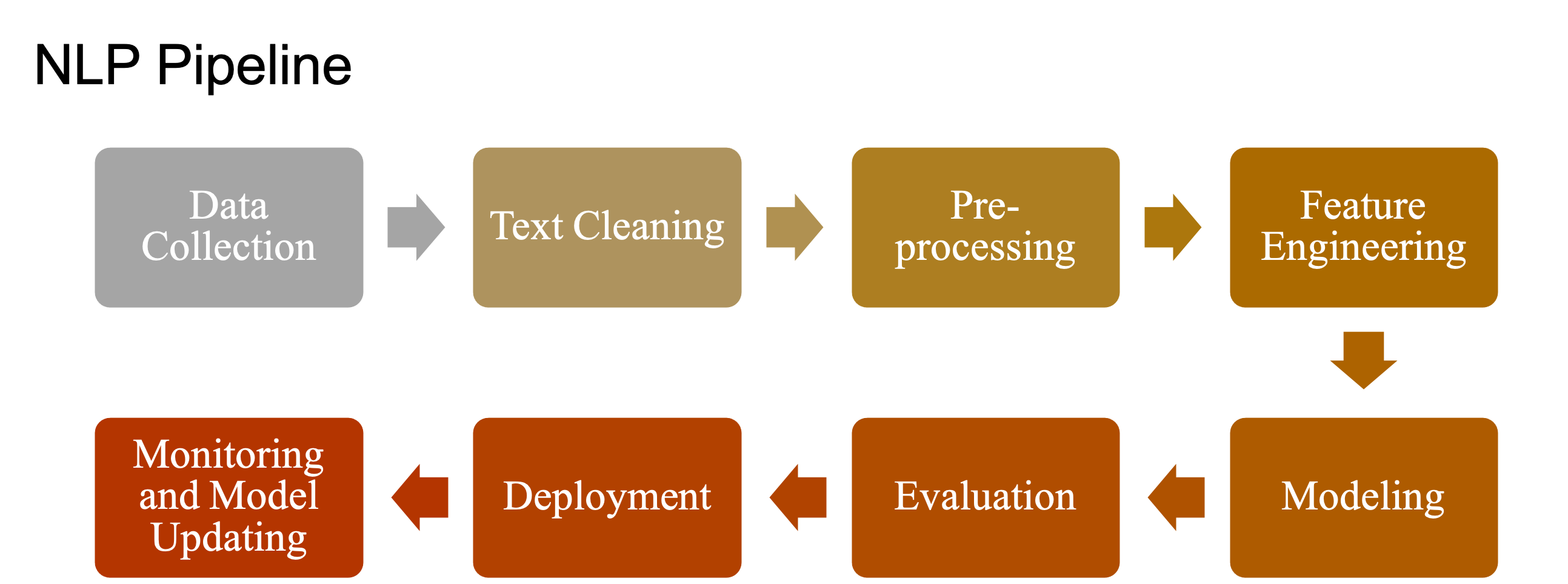
Useful Reading
- [Blog] The Natural Language Processing Pipeline
- [Paper] Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus
- [Paper] A Critical Analysis of the Largest Source for Generative AI Training Data: Common Crawl
- [Blog] What are the best datasets for training NLP models?
- [Blog] NLP Pipeline
Study Goals
이 장의 목표는 다음과 같다. 첫째, 언어 빅데이터를 책임 있게 수집하고 문서화하는 원칙을 이해한다. 둘째, 정제와 전처리(정규화, 중복 제거, 필터링)가 모델 성능과 일반화에 미치는 영향을 구체적으로 학습한다. 셋째, 비용 효율적 레이블링 전략(수동 주석, 크라우드소싱, 능동학습, 약지도)을 비교·선택하는 기준을 익힌다. 넷째, 자연어의 다층적 모호성(어휘·통사·의미·화용)을 체계적으로 분류하고 WSD(어의중의성 해소) 등 대표 접근을 이해한다. 다섯째, 토크나이즈(특히 서브워드 기반)의 설계 선택이 언어·도메인별로 불공정성을 유발할 수 있음을 인지하고, 공정성·효율성 관점에서의 트레이드오프를 파악한다
- Ambiguity in Natural Language Processing: A Workflow Perspective
- The Unfairness of Tokenizers
- The impact of preprocessing decisions on NLP model performance
- CloudFactory Blog - Natural Language Processing Guide
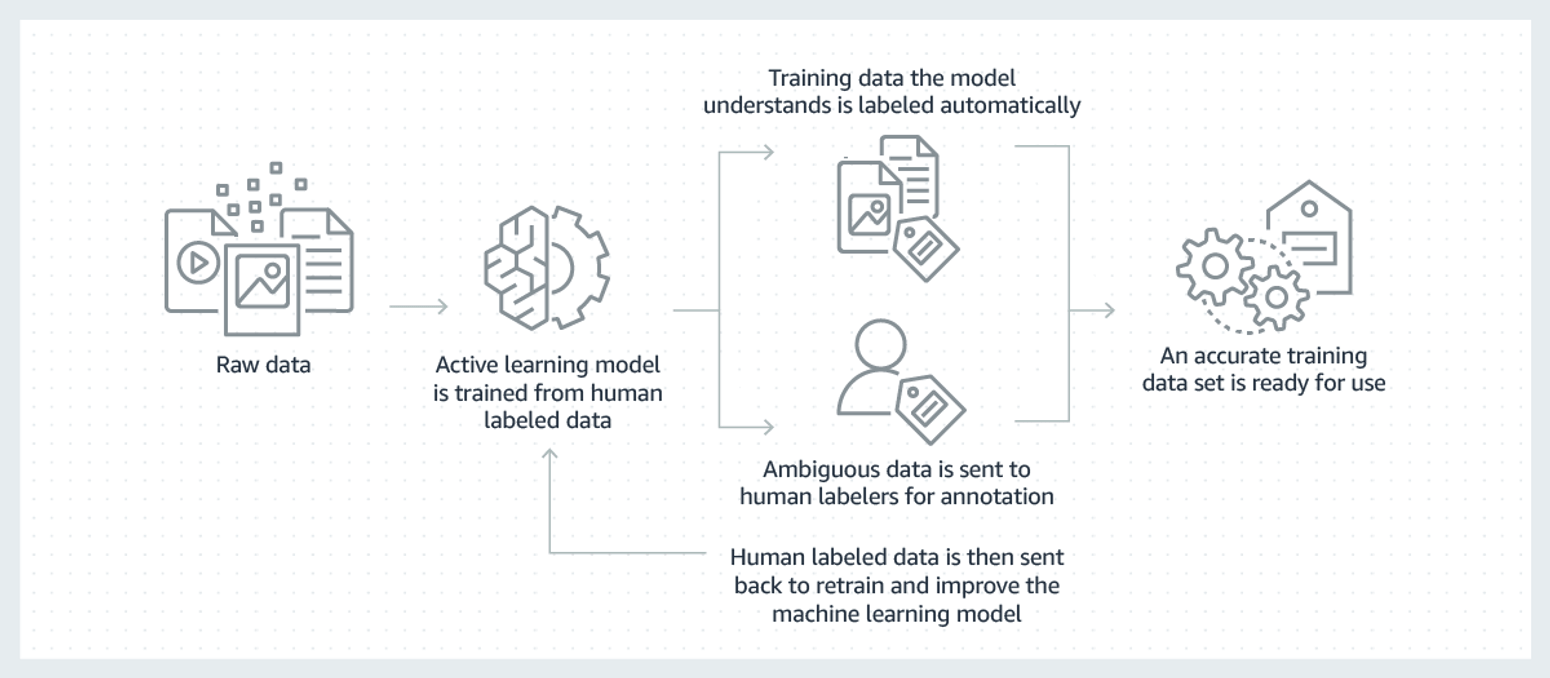
Machine Learning Process
머신러닝 혹은 딥러닝 모델을 구축하기 위해서는 일련의 절차를 체계적으로 수행해야 한다. 이 과정은 단순히 알고리즘을 선택하고 학습시키는 것에 국한되지 않으며, 문제 정의에서부터 실제 운영 환경에 모델을 배포하기까지 여러 단계를 포함한다. 아래에서는 머신러닝 수행 절차의 각 단계를 자세히 설명한다.
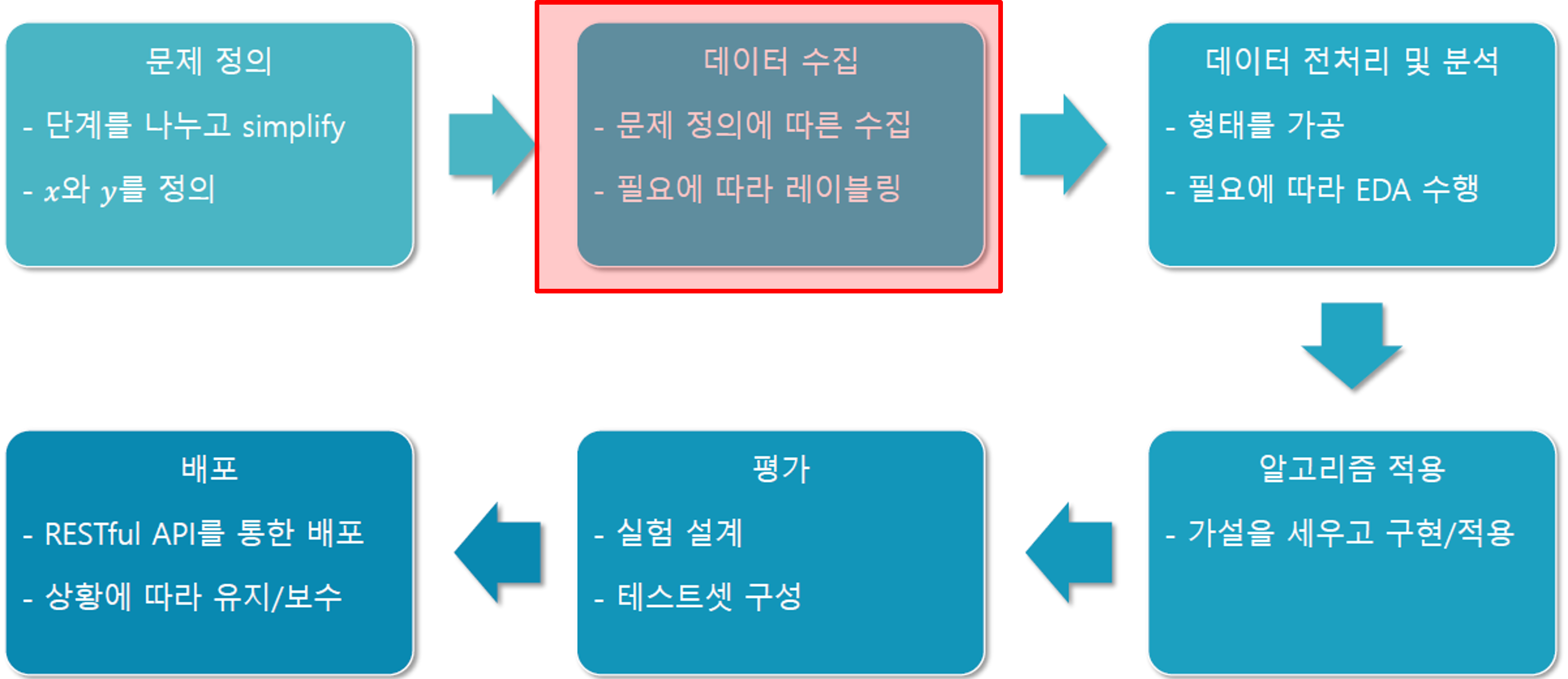
문제 정의
머신러닝 프로젝트의 출발점은 해결하고자 하는 문제를 명확히 정의하는 것이다. 문제를 가능한 한 단순화하고, 학습 과정에서 입력 변수(x)와 예측하고자 하는 목표 값(y)을 명확히 구분해야 한다. 이 단계에서 문제를 잘못 정의하면 이후 모든 과정이 잘못된 방향으로 진행될 수 있기 때문에, 충분한 논의와 분석이 필요하다.
데이터 수집
문제를 정의한 후에는 해당 문제를 해결하기 위한 데이터를 수집해야 한다. 데이터는 다양한 경로(센서, 로그, 오픈 데이터셋, 웹 크롤링 등)를 통해 확보될 수 있다. 중요한 점은 문제 정의에 맞는 데이터를 선정하는 것이며, 경우에 따라 추가적인 데이터 레이블링이 필요할 수 있다. 이 단계는 모델의 성능을 좌우하는 핵심 과정이다.
데이터 전처리 및 분석
수집된 데이터는 원시(raw) 상태 그대로는 모델 학습에 적합하지 않다. 따라서 결측치 처리, 이상치 제거, 정규화 및 표준화와 같은 전처리 과정을 거쳐야 한다. 또한, 탐색적 데이터 분석(Exploratory Data Analysis, EDA)을 통해 데이터의 분포, 상관관계, 패턴을 파악함으로써 문제에 대한 이해를 심화시킬 수 있다.
알고리즘 적용
전처리된 데이터를 바탕으로 적절한 알고리즘을 선택하고 적용한다. 이 과정에서는 문제에 대한 가설을 세우고, 이를 구현 가능한 모델로 설계하여 학습시킨다. 알고리즘 선택은 문제의 특성, 데이터의 양과 품질, 성능 요구사항 등에 따라 달라진다.
평가
모델이 학습된 후에는 성능을 평가해야 한다. 이를 위해 별도의 테스트셋을 구성하고, 실험 설계를 통해 모델의 예측 정확도와 일반화 성능을 검증한다. 평가 결과는 이후 모델 개선 여부를 판단하는 기준이 된다.
배포
최종적으로 성능이 검증된 모델은 실제 환경에 배포된다. 배포는 RESTful API 등의 형태로 이루어지며, 서비스 상황에 따라 모델의 유지·보수와 업데이트가 필수적으로 수반된다. 이 과정에서 운영 환경의 요구사항에 맞추어 모델을 최적화하는 작업도 수행된다.
이와 같이 머신러닝은 문제 정의에서부터 배포까지 유기적으로 연결된 절차를 필요로 한다. 특히, 데이터 수집은 모든 과정의 출발점이자 가장 중요한 단계로, 학습 데이터의 품질이 모델의 성능에 직결된다. 따라서 우리는 이번 Chapter에서 데이터 수집에 대해 집중적으로 학습할 것이다.
Data Collection
언어 빅데이터를 활용한 자연어처리 연구와 응용은 단순히 데이터를 모으는 것에서 끝나지 않는다. 데이터를 수집한 이후에는 정제, 레이블링, 분절 등 일련의 과정을 거쳐야만 학습 가능한 형태로 변환할 수 있다. 아래는 언어 빅데이터 수집 및 전처리의 주요 단계를 정리한 것이다.
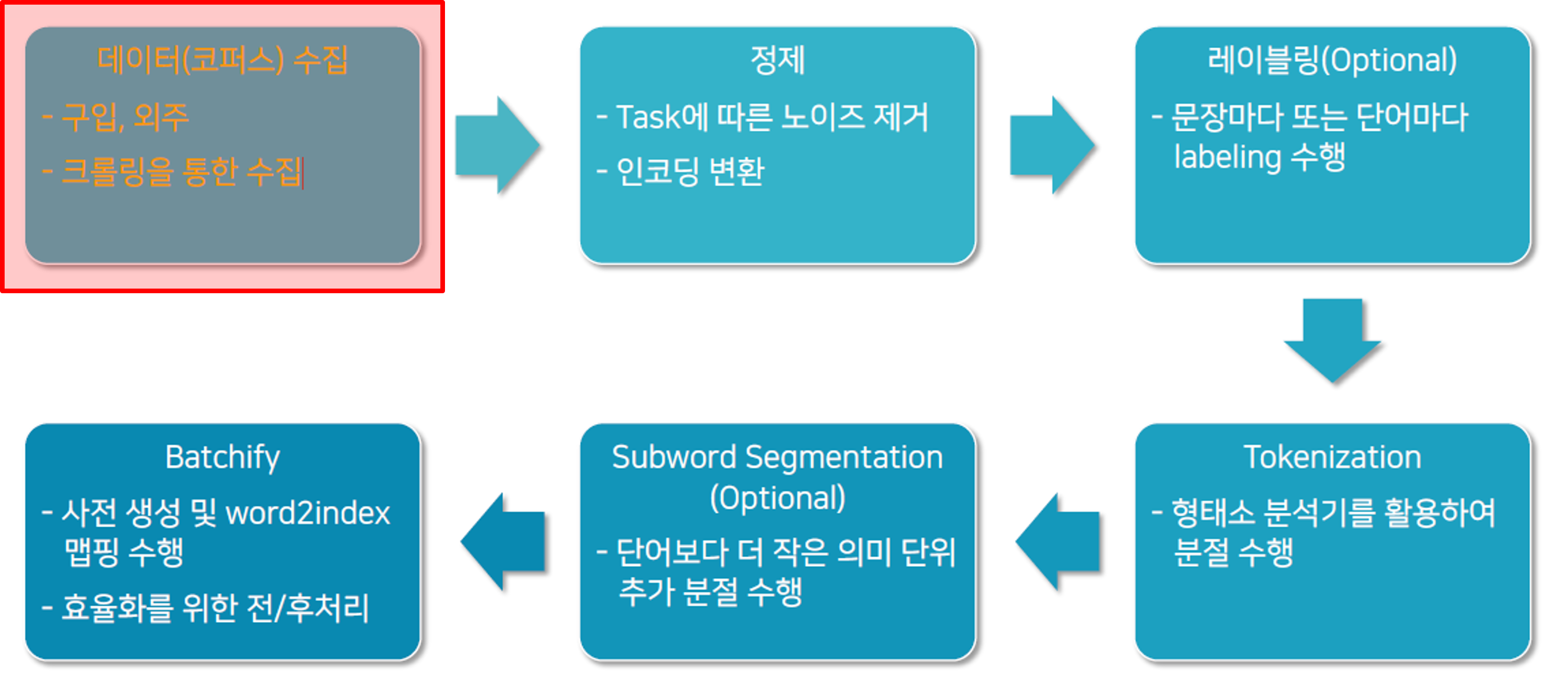
가장 먼저 수행해야 할 작업은 대규모 언어 데이터를 모으는 것이다. 이는 구입을 통해 확보하거나 외부 기관에서 제공받을 수 있으며, 웹 크롤링을 통해 자동으로 수집하는 방법도 널리 활용된다. 수집 단계에서의 핵심은 연구 목적에 적합한 데이터의 확보와 품질 관리이다.
수집된 데이터에는 불필요한 노이즈가 포함되어 있는 경우가 많다. 광고 문구, HTML 태그, 특수문자 등 분석과 무관한 요소들을 제거해야 한다. 또한 모델 학습에 적합하도록 인코딩 변환을 수행하여 일관된 데이터 형태를 만드는 과정이 필요하다.
모든 언어 데이터가 레이블을 필요로 하지는 않는다. 그러나 지도학습(Supervised Learning)을 수행하기 위해서는 문장 단위 또는 단어 단위의 레이블링이 필요하다. 이 과정에서는 사람이 직접 태깅을 수행하거나, 반자동화된 도구를 활용하여 효율성을 높일 수 있다.
형태소 분석기를 활용하여 문장을 단어 단위로 분절하는 과정이다. 한국어와 같은 교착어에서는 형태소 단위로 쪼개는 것이 중요하며, 영어와 같은 언어에서는 공백을 기준으로 기본적인 분리가 가능하다. 이 단계는 이후 모든 NLP 작업의 기초가 된다.
토큰 단위보다 더 세밀한 의미 단위를 고려해야 할 때, 단어를 더 작은 서브워드 단위로 분절하는 과정을 거친다. 대표적으로 BPE(Byte Pair Encoding)나 SentencePiece와 같은 알고리즘이 활용되며, 희귀 단어 처리 및 어휘 집합 축소에 유리하다.
마지막으로, 데이터를 모델 학습에 효율적으로 사용할 수 있도록 사전을 생성하고 단어를 인덱스로 매핑한다. 이 과정을 통해 데이터를 텐서 형태로 변환하고, 학습 시 병렬 처리와 전·후처리를 용이하게 만든다.
이와 같이 언어 빅데이터는 단순히 수집에 그치지 않고, 정제와 레이블링, 토큰화 및 배치화 과정을 거쳐야 비로소 학습 가능한 형태로 완성된다. 우리는 이 일련의 과정 중 데이터 수집 단계부터 학습을 시작할 것이다.
코퍼스(Corpus)에 대하여
자연어 처리에서 코퍼스(corpus)란 언어 연구나 기계 학습을 위해 수집된 문장들의 집합을 의미한다. 말뭉치라고도 부르며, 텍스트 데이터 기반의 모든 연구의 기초가 된다. 코퍼스는 포함된 언어의 수, 구성 방식, 그리고 주석 여부에 따라 다양한 종류로 나눌 수 있다.
코퍼스의 주요 유형
-
Monolingual Corpus (단일 언어 코퍼스)
한 가지 언어로만 이루어진 데이터셋으로, 특정 언어의 문법적 특징이나 통계적 패턴을 학습할 때 주로 활용된다. 예를 들어 한국어 신문 기사 모음이나 영어 뉴스 기사 데이터 등이 있다. -
Bi-lingual Corpus (이중 언어 코퍼스)
두 가지 언어가 함께 포함된 데이터셋으로, 기계 번역 연구에서 널리 사용된다. 예를 들어 영어–한국어 병렬 문장이 정렬된 말뭉치가 있다. -
Multi-lingual Corpus (다중 언어 코퍼스)
세 가지 이상의 언어로 구성된 데이터셋이다. 다양한 언어 자원을 필요로 하는 다국어 번역 시스템이나 다언어 정보 검색 연구에 유용하다. -
Parallel Corpus (병렬 코퍼스)
서로 다른 언어로 번역된 문장 쌍이 레이블링된 상태로 제공되는 데이터셋이다. 이는 기계 번역 모델을 학습시키는 데 핵심적이며, 예를 들어 영어 문장과 그에 대응하는 한국어 번역이 정렬된 데이터를 포함한다.
예시: 영어–한국어 병렬 코퍼스
| English | Korean |
|---|---|
| I love University. | 나는 대학교를 좋아한다. |
| I am a college student. | 나는 대학생 입니다. |
| ... | ... |
이처럼 코퍼스는 단순히 문장을 모아 놓은 것이 아니라, 언어 분석과 모델 학습의 출발점이 된다. 특히 병렬 코퍼스는 기계 번역, 언어 모델 학습, 다언어 시스템 구축에 있어서 필수적인 자원이다.
언어 빅데이터 수집 방법
언어 빅데이터를 확보하는 방식은 크게 세 가지로 구분할 수 있다. 연구 목적, 예산, 그리고 데이터 품질 요건에 따라 선택이 달라질 수 있다. 각각의 방식은 장단점이 존재하며, 실제 프로젝트에서는 이들을 혼합하여 활용하는 경우가 많다.
돈 쓰는 방법
가장 직관적인 방법은 비용을 지불하고 데이터를 확보하는 것이다. 대표적으로 상업적 데이터셋을 구입하거나, 특정 기업·기관으로부터 데이터를 외주 형태로 제공받을 수 있다. 이 방식은 높은 품질과 전문적인 레이블링이 보장되는 경우가 많지만, 비용 부담이 크고 데이터 사용에 제약이 있을 수 있다.
데이터를 확보하는 가장 직접적이고 확실한 방법은 구입(purchase)이다. 이 방법은 이미 정제와 라벨링이 끝난 고품질 데이터를 제공받을 수 있다는 장점이 있다. 따라서 연구자나 기업은 데이터를 수집하고 가공하는 시간과 비용을 절약할 수 있으며, 즉시 실험이나 모델 학습에 활용할 수 있다.
그러나 단점도 존재한다. 구입한 데이터가 내가 분석하려는 도메인(domain)과 일치하지 않을 수 있다. 예를 들어 특정 산업(의료, 법률, 금융 등)에 특화된 데이터를 원하지만, 일반 대화체 데이터나 뉴스 기사 데이터만 제공되는 경우가 많다. 따라서 구입 데이터는 범용성은 높지만 특정 목적에 최적화되지는 않은 경우가 많다.
대표적인 데이터 구입처로는 대학 연구소와 같은 학술 기관이 있으며, 상용 데이터 제공 기업들도 활발히 활동하고 있다. 예를 들어, 플리토(Flitto)는 언어 데이터 전문 기업으로 다양한 언어 데이터를 제공한다.
플리토와 같은 기업을 통해 데이터셋을 구매하면 신뢰할 수 있는 라벨링 품질과 대규모 데이터를 확보할 수 있다. 하지만 비용이 발생한다는 점에서 프로젝트 예산을 고려해야 한다.
무료 데이터 활용
많은 연구 커뮤니티와 기관에서는 무료로 데이터셋을 제공한다. 예를 들어, Common Crawl, Wikipedia Dump, OpenSubtitles 등은 누구나 접근 가능한 대표적인 공개 데이터셋이다. 이러한 데이터는 비용 부담이 없고 학술 연구에 널리 쓰이지만, 데이터 품질이 일정하지 않거나 불필요한 노이즈가 많이 포함될 수 있다.
언어 데이터 수집에서 가장 유용하면서도 비용 효율적인 방법은 무료로 공개된 데이터셋을 활용하는 것이다. 정부, 공공기관, 연구단체, 기업 등에서 제공하는 다양한 형태의 데이터가 존재하며, 이를 적절히 활용하면 대규모 데이터를 손쉽게 확보할 수 있다.
주요 무료 데이터 소스
공공주도 빅데이터
- AI Hub (회원가입 필수)
- 교육, 문화, 스포츠 등 다양한 주제의 데이터셋을 제공하며, 한국어–영어 번역 병렬 말뭉치 등 고품질 데이터가 포함되어 있다.
- 특히 인공지능 연구 및 모델 학습을 위한 정제된 데이터를 제공하므로, 많은 연구자들이 활용하고 있다.
공공데이터 포털
- 공공데이터 포털
- 행정, 사회, 교통, 환경 등 다양한 주제의 데이터를 정부 차원에서 제공한다. 연구 목적뿐 아니라 실무 프로젝트에도 폭넓게 활용 가능하다.
무료 뉴스기사 데이터
- 빅카인즈(BigKinds)
- 국내 주요 언론사의 기사 데이터를 무료로 제공하며, 뉴스 기반 텍스트 마이닝 연구나 감성 분석 실험 등에 자주 활용된다.
Github의 Open 데이터셋
- 네이버 영화 리뷰 감성 데이터(NSMC)
- 한국어 감성 분석 연구에서 가장 널리 사용되는 데이터셋 중 하나로, 긍정/부정 레이블이 포함된 리뷰 데이터이다.
외국 언론사에서 제공하는 API
- New York Times API
- 뉴욕타임스 기사 데이터를 API로 제공하여 영어 텍스트 분석이나 정보 검색 연구에 활용할 수 있다.
캐글(Kaggle) 데이터
- Kaggle Datasets
- 전 세계 연구자와 기업이 업로드한 데이터셋을 공유하는 플랫폼이다. 자연어처리뿐 아니라 이미지, 음성, 금융, 헬스케어 등 폭넓은 분야의 데이터를 포함한다.
무료 데이터는 초기 연구 단계에서 실험을 설계하고 모델을 검증하는 데 매우 유용하다. 또한 상용 데이터 구매 전에 연구 가설을 검증하는 파일럿 연구에도 적합하다. 다만, 데이터 품질이나 최신성이 보장되지 않는 경우도 있으므로, 연구자는 데이터를 활용하기 전에 반드시 적합성과 한계를 검토해야 한다.
직접 데이터를 수집하는 방법
데이터는 구매나 공개 데이터 활용만으로는 항상 충분하지 않다. 특히 특정 도메인에 특화된 데이터나 한국어처럼 상대적으로 데이터가 부족한 언어의 경우에는 연구자가 직접 데이터를 수집해야 하는 경우가 많다. 직접 데이터를 수집하는 방법은 크게 두 가지로 나눌 수 있다: 무료 데이터의 한계 인식과 웹 크롤링(Crawling)이다.
유료·무료 공개 데이터의 한계
이미 공개된 데이터셋을 활용할 경우, 종류와 양의 제한성이 가장 큰 문제다. 내가 분석하려는 도메인과 정확히 일치하지 않는 경우가 많으며, 특히 한국어 데이터는 영어에 비해 현저히 부족하다.
이러한 한계 때문에 연구자는 원하는 목표에 맞는 데이터를 직접 수집해야 하는 상황에 자주 직면하게 된다.
Crawling
웹 크롤링은 인터넷으로부터 방대한 데이터를 자동으로 수집하는 방법이다.
거의 무한대의 코퍼스를 확보할 수 있고, 특정 도메인별로 데이터를 맞춤형으로 수집할 수 있다는 점에서 강력한 방법이다. 하지만 단점도 뚜렷하다.
- 품질 문제: 수집된 데이터는 이모티콘, 특수문자, 노이즈가 많으며, 한국어는 띄어쓰기 오류가 빈번하다.
- 정제 비용: 크롤링 후 데이터 정제를 위해 많은 시간과 비용이 소요된다.
- 법적 이슈: 데이터 수집의 적법성은 여전히 논란이 있으며, 각 사이트의 로봇 배제 표준(
robots.txt)을 반드시 확인해야 한다.
관련 자료
직접 데이터를 수집하는 방식은 강력한 가능성을 제공하지만, 동시에 품질 관리와 법적 문제를 반드시 고려해야 한다. 따라서 연구자는 데이터 수집 과정에서 기술적 효율성과 법적 정당성을 모두 충족할 수 있는 전략을 마련해야 한다.
Hell of Preprocessing
데이터 전처리 – 과연 지옥인가!?
데이터 전처리는 많은 연구자들이 공통적으로 가장 힘들다고 느끼는 과정 중 하나이다.

반복적이고 지루하며, 눈에 띄는 성과가 바로 나타나지 않는 작업이기 때문이다.
하지만 역설적으로, 이 과정이야말로 딥러닝과 머신러닝의 성패를 좌우하는 핵심 단계이다.
널리 알려진 사실
- 데이터 전처리는 지루하고 끝없는 반복 작업이다.
- 프로그래머와 연구자가 가장 싫어하는 지점이 바로 이 전처리 과정이다.
- 그러나, 동시에 가장 중요한 과정이다. 깨끗하지 않은 데이터로는 절대 좋은 모델을 얻을 수 없다.
그래도 중요한 이유
- Garbage in, Garbage out!
- 잘못된 데이터를 입력하면, 그 결과물도 잘못될 수밖에 없다.
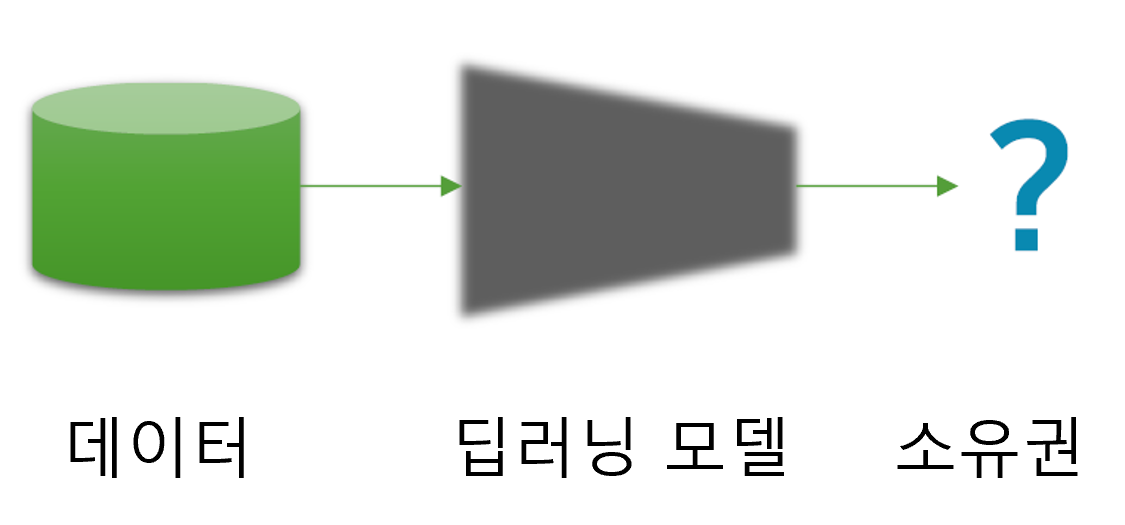
- 딥러닝 모델의 최종 성과(Final Outcome Quality)는 결국 데이터 입력 품질에 의해 결정된다.

핵심 메시지
아무리 뛰어난 알고리즘과 강력한 연산 자원이 있더라도, 데이터가 정제되지 않았다면 성능은 한계에 부딪힌다.
아무리 힘들고 포기하고 싶더라도, 데이터 전처리는 반드시 수행해야 하는 필수 단계이다.
데이터 정제와 가공을 소홀히 하면 연구의 신뢰성과 모델의 활용 가능성이 떨어진다.
따라서 연구자는 전처리 과정을 단순 반복작업이 아니라, 모델 성능을 담보하는 투자 과정으로 이해해야 한다.
Refinement
데이터 정제(Refining 또는 Cleaning)는 수집된 원시 데이터(raw data)를 학습 가능한 상태로 가공하는 과정을 의미한다. 이 과정은 단순히 불필요한 데이터를 제거하는 데서 그치지 않고, 연구 목적과 학습 과제(Task)에 맞게 데이터를 최적화하는 것을 목표로 한다.
정제 과정의 주요 단계
Task에 따른 노이즈 제거
- 원시 데이터에는 불필요하거나 잘못된 정보가 다수 포함되어 있다. 예를 들어 HTML 태그, 광고 문구, 특수문자, 이모티콘, 중복 문장, 맞춤법 오류 등이 노이즈에 해당한다.
- 연구 목적에 맞게 어떤 요소를 제거할지 결정해야 한다. 예를 들어 감성 분석 과제에서는 이모티콘이 중요한 의미를 가질 수 있으므로 단순히 제거하지 않고 보존하는 전략이 필요할 수 있다.
인코딩 변환
- 서로 다른 데이터 소스에서 수집한 텍스트는 인코딩 방식이 일관되지 않을 수 있다. UTF-8, EUC-KR, ANSI와 같은 다양한 인코딩 방식이 존재하며, 이를 통일하지 않으면 학습 과정에서 오류가 발생할 수 있다.
- 따라서 데이터 정제 단계에서 모든 텍스트를 하나의 표준 인코딩(일반적으로 UTF-8)으로 변환하는 것이 중요하다.
데이터 정제의 필요성
- Garbage in, Garbage out 원칙에 따라, 정제되지 않은 데이터는 모델 성능을 심각하게 저하시킨다.
- 텍스트 데이터를 기계가 이해할 수 있는 구조로 바꾸는 과정에서 정제는 필수적이다.
- 특히 대규모 언어 데이터에서는 작은 오류가 전체 모델 품질에 큰 영향을 미칠 수 있기 때문에, 데이터 정제는 단순 반복이 아니라 모델 품질을 보장하는 핵심 과정이라 할 수 있다.
데이터 Cleaning 단계
데이터 정제(Cleaning)는 단순히 불필요한 정보를 제거하는 것이 아니라, 텍스트를 과제(Task)에 적합한 형태로 최적화하는 과정이다. 일반적으로 두 단계에 걸쳐 수행된다.
1단계: 기계적 노이즈 제거
- 전형적 노이즈 제거: Task에 필요하지 않은 특수문자, 불필요한 기호, 중복 공백 등을 제거한다.
- 전각 문자 제거: 유니코드 이전의 한글, 한자, 일본어 문서에는 전각(全角) 문자가 포함되어 있는 경우가 많다. 전각 문자는 반각(半角) 문자와 시각적으로는 유사하지만, 컴퓨터는 다른 코드로 인식하기 때문에 통일이 필요하다.
- 예:
P(전각) vsP(반각)

- 중국어/일본어 처리: 중국어나 일본어 코퍼스는 전각 문자가 흔히 사용되므로 반드시 반각으로 변환해주어야 한다. 오래된 한국어 문서에서도 종종 전각 문자가 발견되므로 주의가 필요하다.
2단계: 인터랙티브(Interactive) 노이즈 제거
- 코퍼스 특성 기반 제거: 코퍼스가 가진 언어적·도메인적 특성을 고려하여 불필요한 데이터를 제거한다.
- 예: 감성 분석에서는 이모티콘이 중요한 의미를 가질 수 있지만, 법률 문서 분석에서는 불필요한 요소로 간주될 수 있다.
- 신중한 접근: 이모티콘, 특수문자, 방언 등은 무조건 제거할 것이 아니라, 연구 목적과 데이터 도메인에 따라 보존 여부를 결정해야 한다.
- 대소문자 통일(Optional): 영어 코퍼스의 경우, 필요에 따라 모든 텍스트를 소문자로 변환하여 일관성을 확보할 수 있다.
정리
데이터 Cleaning은 단순 반복이 아니라, 텍스트 품질을 보장하는 전략적 과정이다.
이 과정을 얼마나 정교하게 수행하느냐에 따라 모델 성능과 연구 신뢰성이 크게 달라진다.
정규표현식을 이용한 인터랙티브 정제
언어 데이터 정제 과정에서 반복적이고 규칙적인 패턴을 처리할 때 정규표현식(Regular Expression, Regex)은 강력한 도구로 활용된다. 정규표현식은 특정 규칙에 따라 문자열을 탐색, 추출, 치환할 수 있도록 해준다.
정규표현식의 특징
- 패턴 기반 처리: 언어 데이터에서 일정한 규칙(예: 전화번호, 이메일, URL 등)을 찾아내어 일괄적으로 처리할 수 있다.
- 재활용성: 한 번 작성한 정규표현식은 다양한 데이터셋에 적용 가능하다. 다만, 한 번 적용하면 중간 과정의 확인이 어렵다는 단점이 있다.
- 파이썬 활용:
re라이브러리를 통해 쉽게 사용할 수 있다.
예제 (파이썬 코드)
import re
# 전화번호 패턴 정의
regex = r"([\w]+\s*:?\s*)?(?:\+?[0-9]{1,3})?-?[0-9]{2,3}(\)|\-)?[0-9]{3,4}-?[0-9]{4}"
# 예제 문자열
x = "Ki: +82-10-1234-5678 "
print(re.sub(regex, "REMOVED", x))
# 출력: 'REMOVED'
x = "CONTENT jiu 02)1234-5678."
print(re.sub(regex, "REMOVED", x))
# 출력: 'CONTENT REMOVED'
위 예시에서는 전화번호 패턴을 탐지하여 "REMOVED"라는 텍스트로 치환하였다. 이처럼 개인정보나 불필요한 숫자 패턴을 제거할 때 정규표현식이 유용하다.
텍스트 에디터에서 활용
VS Code, Sublime Text와 같은 텍스트 에디터에서도 정규표현식을 사용할 수 있다.
코드 작성 없이도 바로 적용할 수 있으며, 즉시 결과를 확인할 수 있다는 장점이 있다.
그러나 적용 과정이 기록되지 않아, 향후 동일한 정제를 반복 적용하기 어려운 단점이 있다.
정규표현식은 데이터 정제에서 강력하면서도 양날의 검과 같은 도구이다. 빠른 정제와 반복 작업에는 효과적이지만, 적용 이력이 남지 않아 재현성이 필요한 연구에서는 파이썬 코드와 같이 기록 가능한 방식으로 사용하는 것이 더 바람직하다.
Regular Expression 이용한 전처리
- 텍스트에서 일정한 패턴을 탐색·치환·추출하기 위한 강력한 도구.
- 데이터 전처리, 로그 분석, 웹 크롤링, 데이터 정제 과정에서 필수적으로 활용된다.
- Python의
re모듈, 텍스트 에디터(VS Code, Sublime Text 등)에서 사용 가능.
문자 집합
[ ]: 여러 개 중 하나
[234cde]→2,3,4,c,d,e중 하나
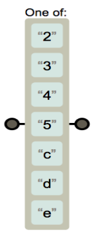
[2-4c-e]→2,3,4,c,d,e
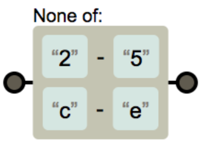
^: not 의미
[^2-4c-e]→2 ~ 4,c ~ e제외한 모든 문자
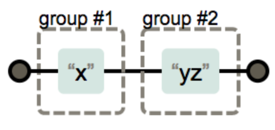
그룹과 OR
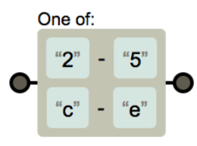
( ): 그룹을 만들어 부분 추출 가능(x)(yz)→x는 그룹1,yz는 그룹2
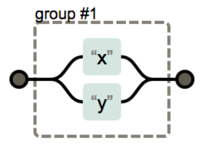
-
|: OR 연산(x|y)→x또는y
수량자
?: 0번 또는 1번 등장
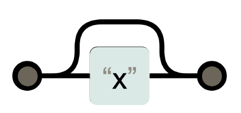
[예시] https?://: s라는 문자가 없거나 또는 1번 등장하거나 둘다 매칭으로 판정,
따라서 http://와 https:// 둘 다 매칭
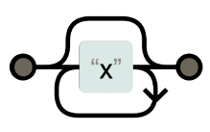
+: 1번 이상 반복
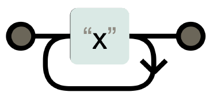
*: 0번 이상 반복
{n}: n번 반복- (예시)
x{3}:x라는 문자가 3번 반복되면 매치
- (예시)
{n,}: n번 이상 반복- (예시)
x{4,}:x라는 문자가 4번 이상 반복되면 매치
- (예시)
{n,m}: n~m번 반복- (예시)
x{4, 7}:x라는 문자가 4번 ~ 7번 사이에서 반복되면 매치
- (예시)
위치 지정자
^: 라인의 시작 ([]내부가 아닌 경우에만 해당.[]내부에서^이 사용된 경우는not을 의미함)$: 라인의 끝.: 모든 문자 매칭 (개행 제외), 어떤 글자로도 매칭되는 경우 (매우 강력한 표현임. 조심스럽게 사용)- (예시)
.{8}: 아무 문자나 9번 나타나면 매치 - (예시)
b.+d:b라는 문자 이후에 아무 문자가 1번 이상 나타나고d라는 문자가 나타나면 매치
- (예시)
전후방 탐색 (Lookaround)
(?= ): 긍정형 전방탐색 → 뒤의 조건이 맞는지 확인(?! ): 부정형 전방탐색 → 뒤의 조건이 맞지 않는지 확인(?<= ): 긍정형 후방탐색 → 앞의 조건이 맞는지 확인(?<! ): 부정형 후방탐색 → 앞의 조건이 맞지 않는지 확인
메타 문자와 이스케이프
- 자주 쓰이는 메타 문자:
\s: 공백\S: 공백 제외\w: 알파벳/숫자/언더바\W:\w제외 문자\d: 숫자-
\D: 숫자 제외 -
이스케이프 (escape) 처리:
\\: 백슬래시 그대로\.: 마침표 문자 그대로\+: 플러스 기호 그대로\[:[기호 그대로\{:{기호 그대로\-:-기호 그대로
Python 예제
import re
# 전화번호 제거
text = "연락처: 010-1234-5678"
regex = r"\d{2,3}-\d{3,4}-\d{4}"
print(re.sub(regex, "REMOVED", text))
# 출력: "연락처: REMOVED"
# URL 찾기
text2 = "사이트: http://naver.com 과 https://google.com"
urls = re.findall(r"https?://[\w\.]+", text2)
print(urls)
# 출력: ['http://naver.com', 'https://google.com']
Labeling
언어 빅데이터 레이블링(Labeling)은 수집된 데이터에 의미를 부여하는 과정으로, 모든 데이터 처리 과정에서 반드시 수행해야 하는 단계는 아니고 선택적으로 진행되는 경우가 많다. 특히 지도 학습(Supervised Learning) 모델을 학습시키기 위해서는 입력 데이터와 정답 레이블이 반드시 필요하기 때문에 중요한 역할을 한다.
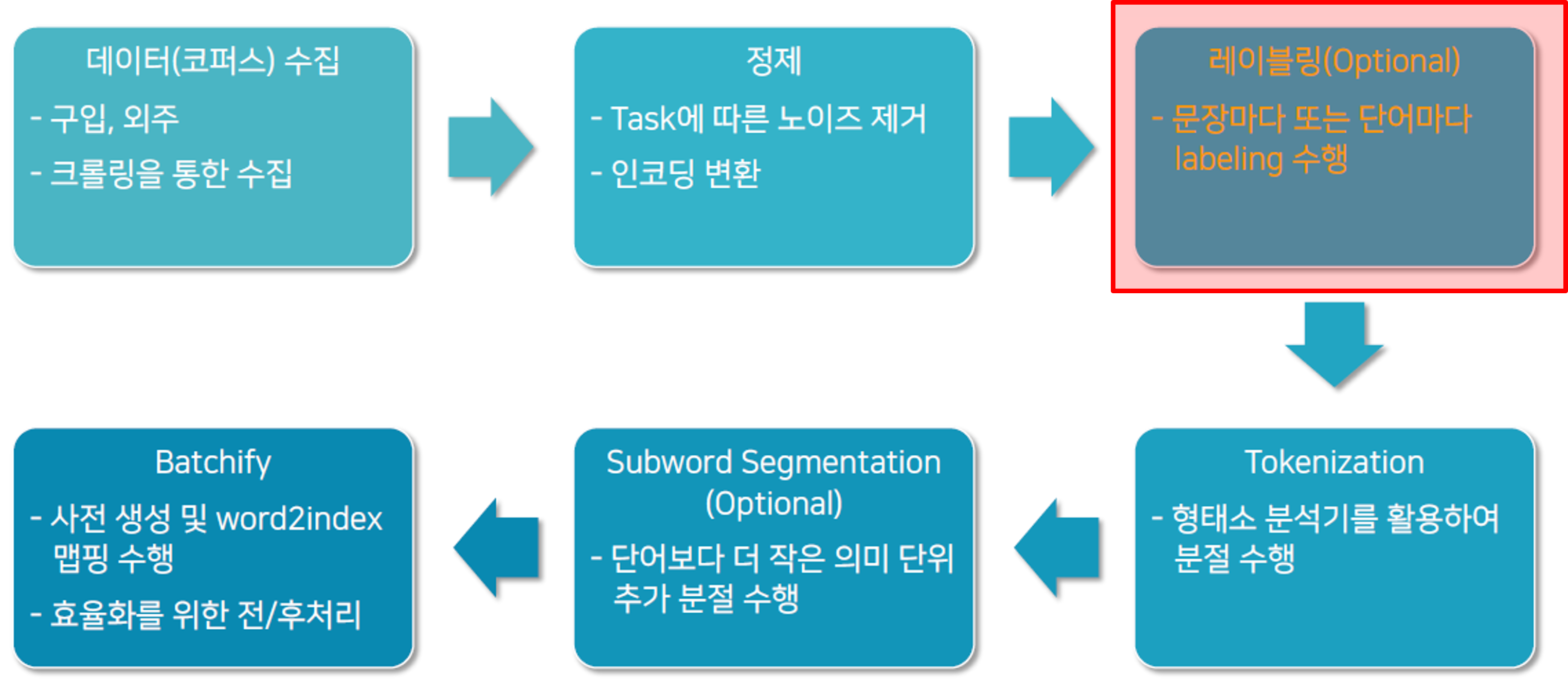
레이블링은 문장 단위와 단어 단위로 나눌 수 있다. 문장 단위에서는 각 문장에 특정 카테고리나 의미 태그를 붙이고, 단어 단위에서는 품사나 개체명(NER), 혹은 감정 태그 등을 부여한다. 이를 통해 데이터는 단순한 텍스트를 넘어서 기계가 이해할 수 있는 구조화된 정보로 변환된다.
레이블링 방식에는 크게 세 가지가 있다. 첫째, 사람이 직접 태깅하는 수작업 레이블링은 정확도가 높지만 시간과 비용이 많이 든다는 단점이 있다. 둘째, 반자동 레이블링은 기존 모델이나 규칙 기반 시스템이 태깅한 뒤 사람이 이를 검증하고 수정하는 방식으로, 효율성과 정확성을 동시에 추구할 수 있다. 셋째, 자동 레이블링은 인공지능 모델을 활용해 전적으로 기계가 태깅하는 방식으로, 대규모 데이터를 빠르게 처리할 수 있지만 정확도 면에서는 여전히 후처리가 필요하다.
레이블링은 다양한 응용 분야에서 활용된다. 예를 들어 자연어 처리 분야에서는 감정 분석을 위해 긍정, 부정, 중립과 같은 태그를 붙이고, 개체명 인식을 통해 인물이나 기관, 지명을 표시한다. 기계 번역에서는 병렬 코퍼스를 구축하는 데에도 필수적이다. 또 음성 인식에서는 발화된 문장을 실제 텍스트와 매핑하고, 이미지나 비디오 데이터에서는 장면을 설명하는 캡션을 달아주는 역할을 한다.
이러한 레이블링은 전체 데이터 처리 파이프라인에서 정제(Cleaning) 이후, 토큰화(Tokenization) 이전 단계에서 수행된다. 즉, 데이터가 깨끗하게 정리된 다음, 기계 학습에 필요한 의미적 구조를 부여하는 과정이라고 할 수 있다. 따라서 레이블링은 선택적(Optional) 단계이지만, 지도 학습 기반의 딥러닝 모델에서는 모델 성능을 좌우하는 핵심 요소로 작용한다.
레이블링 전략 1
-
입수한 데이터에 Label이 없는 경우도 많다.
- 대부분의 데이터에 해당
- 돈 주고 사거나(또는 외주), 혹은 정부 제공 데이터의 경우 일부 존재
- 극악의 전처리를 거쳤더라도, Label이 없으면 무용지물 ㅠ
-
Text Classification
- INPUT: 문장
- OUTPUT: 클래스(class)
- 다양한 클래스 가능
클래스 문장 긍정 자연어처리 최고예요 ^^ 부정 이번주에 공강 이라니 슬퍼요 ㅠ 긍정 ㅎㅎㅎㅎㅎ 부정 재미없는 강의도 많아요… ... ... -
tsv 파일로 저장
- 콤마(comma)로 데이터를 분리하는 csv 형식은 부적절 (문장 내에 쉼표가 많이 있음)
- 전처리 과정에서 Tab을 제거하는 작업이 필요
클래스 \t문장 긍정 \t자연어처리 최고예요 ^^ 부정 \t이번주에 공강 이라니 슬퍼요 ㅠ 긍정 \tㅎㅎㅎㅎㅎ 부정 \t재미없는 강의도 많아요… ... \t...
레이블링 전략 2
레이블링 과정에서 가장 중요한 점은 사람이 직접 수행하는 Human Labeling을 잊지 않는 것이다.
사람이 직접 데이터를 라벨링하면 초기 성능 테스트에서 매우 강력한 도구가 된다. 실제로 사람이 수행하는 작업은 기계가 따라오기 힘든 수준의 정확성을 보여주며, 가장 높은 성능을 보장한다. 또한 엑셀과 같은 보조 도구를 활용하면 프로토타이핑 단계에서도 비교적 쉽게 라벨링을 진행할 수 있다.
학습에 필요한 데이터는 보통 수십만 문장 이상이지만, 처음부터 모든 데이터를 준비할 필요는 없다. 예를 들어 10만 문장이 필요하다면 우선 2만 문장을 라벨링해 성능을 확인한 뒤, 필요하다면 외주나 추가 작업을 통해 점진적으로 확장하는 방식이 효과적이다.
라벨링 속도를 계산해보면, 한 문장을 라벨링하는 데 2초가 걸린다고 가정할 때 1분에 약 30문장, 1시간에는 1,800문장을 처리할 수 있다. 하루 8시간 작업 기준으로는 14,400문장을 라벨링할 수 있으며, 4명이 동시에 작업한다면 하루에 약 57,600문장을 처리할 수 있다. 이런 계산을 통해 실제로 어느 정도 기간과 인력이 필요할지 구체적으로 추정할 수 있다.
한편, 최근에는 Unsupervised 방식에 대한 기대도 커지고 있다. 이는 인공지능이 스스로 라벨을 생성하여 학습을 진행하는 방식이다. 과거에는 이러한 방식이 거의 불가능했지만, 최근 AI 기술의 발전으로 인해 자동 라벨링 기법의 가능성이 점차 확대되고 있다. 물론 완전히 사람의 역할을 대체하기에는 아직 한계가 있지만, AI가 보조적인 라벨링을 수행하면서 사람과 협력하는 방식이 점차 보편화될 것으로 예상된다.
정리하면, 현재 시점에서는 여전히 사람이 직접 수행하는 Human Labeling이 가장 확실한 방법이다. 그러나 앞으로는 인공지능의 발전과 함께 자동화된 라벨링이 점점 더 중요한 역할을 하게 될 것이다.
LLM 생성 텍스트의 실전 활용
대형언어모델(LLM)이 생성한 텍스트를 증강 데이터로 활용하는 연구는 최근 빠르게 확산되고 있다. 과거에는 모델이 만들어내는 합성 데이터가 신뢰할 수 있을지 의문이 제기되었으나, 이제는 다양한 연구 결과를 통해 그 가능성이 뒷받침되고 있다. 특히 데이터 부족 문제를 해결하거나 저자원 언어, 다국어, 오탐 위험이 높은 상황에서 합성 텍스트가 중요한 역할을 할 수 있다. 또한 프라이버시 보호를 위한 대체 데이터로도 주목받고 있다.
실험적 근거를 보면, 새로운 데이터를 직접 생성하는 방식이 단순히 기존 데이터를 재작성하는 것보다 효과적이다. 예를 들어 ChatGPT와 같은 모델을 활용해 완전히 새로운 문장을 합성한 경우, 두 데이터셋에서 공통적으로 성능이 향상되었음이 관찰되었다. 특히 라벨당 10~20개 정도의 추가 샘플만 있어도 성능이 plateau(정체 구간)에 도달하는 현상이 나타났다. 또한 GPT-3 기반 합성 데이터는 클래스 불균형 문제를 완화하는 데에도 효과가 있었으며, 감정 분석과 같은 태스크에서 소수 클래스의 성능을 유의미하게 개선하는 결과를 보여주었다.
그러나 합성 데이터 활용에는 리스크도 존재한다. 대표적인 문제가 모델 붕괴(Model collapse)인데, 합성 데이터만으로 학습을 반복할 경우 분포 꼬리 정보가 소실될 위험이 있다. 이를 해결하기 위해서는 실제 데이터를 일정 비율 이상 포함시키고 합성 데이터와 혼합하여 00035사용하는 전략이 필요하다. 이러한 접근은 성능을 유지하면서도 데이터 부족 문제를 보완하는 효과적인 방법으로 자리잡고 있다.

결국, "전면 대체"는 위험할 수 있지만, 실제 데이터와 합성 데이터를 적절히 혼합하는 방식은 이제 충분히 실용적인 전략으로 활용 가능하다. 특히 혼합 비율을 잘 조절하면 학습 안정성과 데이터 다양성을 동시에 확보할 수 있다.
인공지능 기반 합성 데이터 활용 연구
| 저널명 (SCIE) | 출판 연도 | 논문 | 다운로드 |
|---|---|---|---|
| Electronics | 2024 | Improving Text Classification with Large Language Model-Based Data Augmentation | |
| Applied Sciences | 2024 | Enhancing Imbalanced Sentiment Analysis: A GPT-3-Based Sentence-by-Sentence Synthetic Data Generation Approach | |
| Natural Language Engineering | 2024 | Improving Short Text Classification with Augmented Data Using GPT-3 | |
| Expert Systems with Applications | 2025 | Enhancing Text Datasets with Scaling and Targeting Data Augmentation to Improve BERT-Based Machine Learners | Link |
Ambiguity in Natural Languages
자연어(Natural Language)에는 모호성(Ambiguity)이 필연적으로 존재한다. 모호성이란 하나의 단어나 문장이 여러 가지 의미로 해석될 수 있는 현상을 말한다. 이는 언어가 본질적으로 맥락(Context)에 의존하기 때문이다.

어휘적 모호성 (Lexical Ambiguity)
어휘적 모호성은 하나의 단어가 여러 의미를 가질 때 발생한다. 예를 들어, 영어 단어 bank는 ‘강둑’을 의미할 수도 있고 ‘은행’을 의미할 수도 있다. 한국어에서도 배라는 단어가 ‘과일(pear)’, ‘배(ship)’, ‘신체 기관(stomach)’을 모두 의미할 수 있다. 이러한 경우 문맥이 의미를 판별하는 핵심 단서가 된다.
구문적 모호성 (Syntactic Ambiguity)
구문적 모호성은 문장의 구조에 따라 의미가 달라질 때 발생한다. 예를 들어, 문장 "I saw the man with a telescope" 는 “망원경을 가진 남자를 보았다” 혹은 “망원경으로 남자를 보았다”라는 두 가지 해석이 가능하다. 이처럼 문법 구조의 해석 방식이 달라질 수 있는 상황에서 모호성이 생긴다.
의미적 모호성 (Semantic Ambiguity)
의미적 모호성은 문장의 해석에서 문맥에 따라 여러 가지 의미가 나타날 수 있는 경우다. 예를 들어, "He is looking for a match" 라는 문장은 ‘성냥(match)’을 찾는 것일 수도 있고, ‘상대(match)’를 찾는 것일 수도 있다.
담화적 모호성 (Discourse Ambiguity)
담화적 모호성은 대화나 문맥의 흐름 속에서 지시 대상이 불분명할 때 발생한다. 예를 들어, “영희가 미나에게 전화를 걸었는데, 그녀가 전화를 받지 않았다” 라는 문장에서 ‘그녀’가 영희인지 미나인지 명확하지 않다.
자연어 처리에서의 도전 과제
자연어의 모호성은 인간에게는 맥락적 추론으로 해결 가능하지만, 기계에게는 매우 어려운 문제다. 자연어 처리(NLP) 시스템은 이러한 모호성을 해결하기 위해 대규모 데이터 학습, 통계적 언어 모델, 대형 언어 모델(LLM), 그리고 문맥 기반 표현(예: BERT, GPT 등)을 활용한다. 모호성 처리는 기계 번역, 정보 검색, 질의응답 시스템에서 특히 중요한 과제로 다뤄진다.
따라서 Ambiguity in Natural Languages는 언어 이해의 본질적인 어려움 중 하나이며, 동시에 인공지능 언어 연구의 핵심 난제라고 할 수 있다.

단어의 구성과 의미
자연언어처리(NLP)나 언어학에서 단어는 단순히 일상에서 사용하는 형태만을 의미하지 않는다. 단어는 여러 층위로 나누어 설명할 수 있으며, 보통 단어(Word), 표제어(Lemma), 의미(Sense) 세 가지로 구분된다.
단어 (Word)
- 우리가 실제 일상에서 쓰는 형태의 단위
- 예시: 갔다, 가는, 가고, 갔네
- 모양은 다르지만 모두 “가다”라는 공통된 의미를 공유
👉 Word는 문장 속에서 실질적으로 쓰이는 형태를 가리킨다.
표제어 (Lemma)
- 사전에 등록되는 기본형 단어
- 여러 변형된 단어들을 대표하는 사전적 기본형
- 예시:
- 단어들: 갔다, 가는, 가고, 갔네
- 표제어: 가다
👉 Lemma는 단어들의 뿌리, 사전에서 찾을 수 있는 기본형이다.
의미 (Sense)
- 하나의 표제어(Lemma)가 가질 수 있는 구체적인 뜻
- 동일한 Lemma라도 여러 의미(Sense)를 가질 수 있다.
예시: “배”
- 과일 → “사과, 배, 포도”
- 탈 것 → “배를 타다”
- 신체 → “배가 아프다”
👉 Sense는 문맥(Context)에 따라 달라지는 단어의 실제 해석이다.
시각적 예시 – 사전 속의 "차"
- 표제어(Lemma): 차
- 의미(Sense):
- 차(茶, tea) → “차를 마신다”
- 차(車, car) → “차를 탄다”
- 단어(Word): 실제 문장 속에서 쓰이는 형태
- 예: 오늘 아침에 차를 마셨다.
- 예: 그는 차를 타고 출근했다.
👉 같은 표제어 “차”라도 맥락에 따라 전혀 다른 의미로 해석될 수 있음을 보여준다.
언어의 분류 및 특징과 예시
| 구분 | 해당 언어 | 특징 | 예시 문장 |
|---|---|---|---|
| 교착어 | 한국어, 몽골어 등 | 어간에 접사가 붙어 단어를 이루고 의미와 문법적 기능이 결정됨 | 한국어: 가다 + -습니다→ 갑니다 |
| 굴절어 | 독일어, 러시아어 등 | 단어의 형태가 변하면 문법적 기능이 결정됨 | 독일어: ich gehe (나는 간다),du gehst (너는 간다) |
| 고립어 | 영어, 중국어 등 | 어순에 따라 단어의 문법적 기능이 결정됨 | 영어: I love you ↔ You love I(어순이 달라지면 의미 변화) 중국어: 我爱你 (wǒ ài nǐ) = 나는 너를 사랑한다 |
한국어 특성 1 – 접사를 이용한 파생
접사 추가에 따라 다양한 의미가 생성된다.
- 인간이 사용하기에는 최고의 언어!
- 하지만, 컴퓨터가 처리하기에는 복잡하다.
| 순번 | 원형 | 피동 | 높임 | 과거 | 추측 | 전달 | 종료 | 결과 |
|---|---|---|---|---|---|---|---|---|
| 1 | 먹 | - | - | - | - | - | 다 | 먹다 |
| 2 | 먹 | 히 | - | - | - | - | 다 | 먹히다 |
| 3 | 먹 | 히 | 시 | - | - | - | 다 | 먹히시다 |
| 4 | 먹 | 히 | 시 | 었 | - | - | 다 | 먹히셨다 |
| 5 | 먹 | - | - | 었 | - | - | 다 | 먹었다 |
| 6 | 먹 | - | - | - | 겠 | - | 다 | 먹겠다 |
| 7 | 먹 | - | - | - | - | 더라 | - | 먹더라 |
| 8 | 먹 | - | 히 | 었 | - | - | 다 | 먹혔다 |
| 9 | 먹 | 히 | - | 었 | 겠 | - | 다 | 먹혔겠다 |
| 10 | 먹 | 히 | - | 었 | 겠 | 더라 | - | 먹혔겠다더라 |
| 11 | 먹 | - | - | 었 | 겠 | - | 다 | 먹었겠다 |
| 12 | 먹 | 히 | 시 | 었 | 겠 | 더라 | - | 먹히시었겠다더라 |
접사 조합에 따라 무수히 많은 문법적 변화가 나타나며, 이는 한국어의 복잡성과 표현력을 동시에 보여준다.
한국어 특성 2 – 단어 순서가 갖는 유연성
한국어는 교착어의 성격을 가지며, 단어에 붙는 조사(은/는, 이/가, 을/를 등)에 의해 문법적 역할이 결정된다.
이 때문에 단어 순서가 달라져도 문장의 의미가 유지되는 경우가 많다. 반면 영어와 같은 고립어적 특성을 가진 언어는 어순 자체가 의미 해석에 결정적이므로 순서를 바꾸면 의미가 크게 달라지거나 문장이 성립하지 않는다.
| 순번 | 가능한 문장 | 해석 가능 여부 |
|---|---|---|
| 1 | 나는 밥을 먹으러 간다 | O |
| 2 | 간다 나는 밥을 먹으러 | O |
| 3 | 먹으러 간다 나는 밥을 | O |
| 4 | 밥을 먹으러 간다 나는 | O |
| 5 | 나는 먹으러 간다 밥을 | O |
| 6 | 나는 간다 밥을 먹으러 | O |
| 7 | 간다 밥을 먹으러 나는 | O |
| 8 | 간다 먹으러 나는 밥을 | O |
| 9 | 먹으러 나는 밥을 간다 | 해석불가(모호성) |
| 10 | 먹으러 밥을 간다 나는 | 해석불가(모호성) |
| 11 | 밥을 간다 나는 먹으러 | 해석불가(모호성) |
| 12 | 밥을 나는 먹으러 간다 | O |
| 13 | 나는 밥을 간다 먹으러 | O |
| 14 | 간다 나는 먹으러 밥을 | 해석불가(모호성) |
| 15 | 먹으러 간다 밥을 나는 | O |
| 16 | 밥을 먹으러 나는 간다 | O |

👉 위 예시에서 알 수 있듯, 한국어는 조사가 있기 때문에 "누가" "무엇을" "한다"의 관계가 어순과 상관없이 유지된다. 하지만 모든 경우가 해석 가능한 것은 아니며, 일부 어순은 모호성을 유발한다.
영어와의 비교
영어는 SVO(주어-동사-목적어) 어순이 엄격히 고정되어 있어 순서가 달라지면 의미가 크게 달라진다.
- 예시 1:
- I eat rice. (나는 밥을 먹는다)
-
Rice eats I. (밥이 나를 먹는다 → 의미가 전혀 다르며 비문에 가까움)
-
예시 2:
- She loves him. (그녀는 그를 사랑한다)
- Him loves she. (문법적으로 틀린 문장)
👉 따라서 영어에서는 단어의 위치 자체가 문법적 기능을 결정하며, 한국어와 같은 어순 유연성은 존재하지 않는다.
한국어 특성 3 – 띄어 쓰기
한국어에서 띄어 쓰기는 매우 중요한 문법 요소이지만, 실제 사용에서는 애매모호하게 쓰이는 경우가 많다.
사람들은 대체로 띄어 쓰기를 정확히 하지 않아도 의미를 이해할 수 있기 때문에, 일상생활에서는 엄격히 지켜지지 않는 경우가 흔하다.
예를 들어, “청주시체육회와 함께하는 홈트레이닝”이라는 문구는 붙여 쓰였지만, 띄어 쓰기 규범에 따르면 “청주시 체육회와 함께하는 홈 트레이닝”처럼 띄어 써야 한다. 그러나 실제로는 두 방식 모두 의미 전달에는 큰 차이가 없다.

또한 신문 기사에서도 전 국립국어원장이 “띄어 쓰기에 자신이 없다”라는 발언을 한 사례가 보도되기도 했다. 이처럼 전문가들조차도 띄어 쓰기를 정확히 적용하는 데 어려움을 겪는다는 점은 한국어 띄어 쓰기의 복잡성과 현실적 난제를 잘 보여준다.
한국어 띄어 쓰기의 모호성은 컴퓨터가 텍스트를 처리하는 데 큰 어려움을 준다.

예를 들어 “공부하다”와 “공부 하다”는 실제로 같은 의미이지만, 기계는 이를 다르게 처리할 수 있다. 이러한 이유 때문에 자연어처리(NLP)에서는 띄어 쓰기 교정 알고리즘이나 형태소 분석기를 반드시 활용해야 한다.
한국어 띄어 쓰기는 인간에게는 관습적으로 이해 가능한 요소지만, 기계에게는 분석과 처리를 어렵게 만드는 주요 난제로 작용한다.
한국어 특성 4 – 기타 특징들
한국어는 다른 언어와 비교했을 때 몇 가지 독특한 특징을 가지고 있다. 이러한 특징은 한국어가 가진 언어적 유연성을 잘 보여주며, 동시에 학습자나 기계 번역 시스템에게는 어려움을 주기도 한다.
먼저, 의문문과 평서문이 동일할 수 있다. 영어에서는 “I have an apple.”과 “Do you have an apple?”처럼 평서문과 의문문이 명확히 구분된다. 그러나 한국어에서는 “나는 사과 가지고 있어.”와 “나는 사과 가지고 있어?”처럼 단어는 동일하지만 억양에 따라 평서문이 될 수도, 의문문이 될 수도 있다. 이는 억양이 문장의 의미 해석에 중요한 역할을 한다는 것을 보여준다.
둘째, 주어가 없어도 대화가 된다. 영어 문장은 주어가 반드시 필요하지만, 한국어에서는 맥락만으로 의미가 전달되기 때문에 주어를 생략해도 문장이 성립된다. 예를 들어, “나는 점심 먹었어.”라는 문장은 “점심 먹었어.”라고 줄여도 대화 상황에서는 충분히 이해된다. 이는 한국어의 문맥 의존성이 강하다는 특징을 드러낸다.
셋째, 한자 기반의 언어 특성도 존재한다. 같은 음을 가진 단어가 서로 다른 의미를 가질 수 있다. 예를 들어, “차(茶)”는 차 음료를 의미하고, “차(車)”는 자동차를 뜻한다. 발음은 동일하지만, 문맥이나 한자 표기에 따라 의미가 달라진다. 이러한 동음이의어 현상은 한국어 해석에서 중요한 고려 요소다.

한국어는 억양, 맥락, 한자적 의미 체계가 어우러져 풍부한 표현력을 제공한다. 그러나 동시에 외국인 학습자와 기계 번역 시스템에게는 복잡성을 증가시키는 요소로 작용한다. 이러한 특징들은 한국어가 가진 독창성과 어려움을 동시에 보여준다.
단어, 표제어, 의미의 관계
언어에서 단어, 표제어, 의미는 단순히 나눠져 있는 것이 아니라 긴밀히 연결되어 있다. 외부적으로는 다르게 보이더라도 내부적으로는 다양한 방식으로 해석될 수 있으며, 단어의 원형을 찾는 과정에서 표제어와 의미가 정리된다.
1. 단어와 표제어의 연결
- 표제어 추출: 단어들의 원형을 찾는 작업
- 예: be라는 표제어(lemma)는 다양한 단어(words)로 실현된다.
- was
- are
- am
여러 단어 형태들이 결국 하나의 표제어로 귀속된다.
2. 다의어 (Polysemy)
- 하나의 표제어가 여러 의미 항목을 가짐
- 예시:
- 사람의 ‘손’ vs 일손의 ‘손’
- 즉, 하나의 표제어 → 여러 의미(Sense)로 확장된다.
3. 동음이의어 (Homonymy)
- 같은 소리를 가진 단어지만 서로 다른 표제어로 분류됨
- 예시:
- “배” → 먹는 배, 타는 배
- 사전에서는 별도의 표제어로 각각 표시
4. 실제 예시 – 소나타와 테슬라
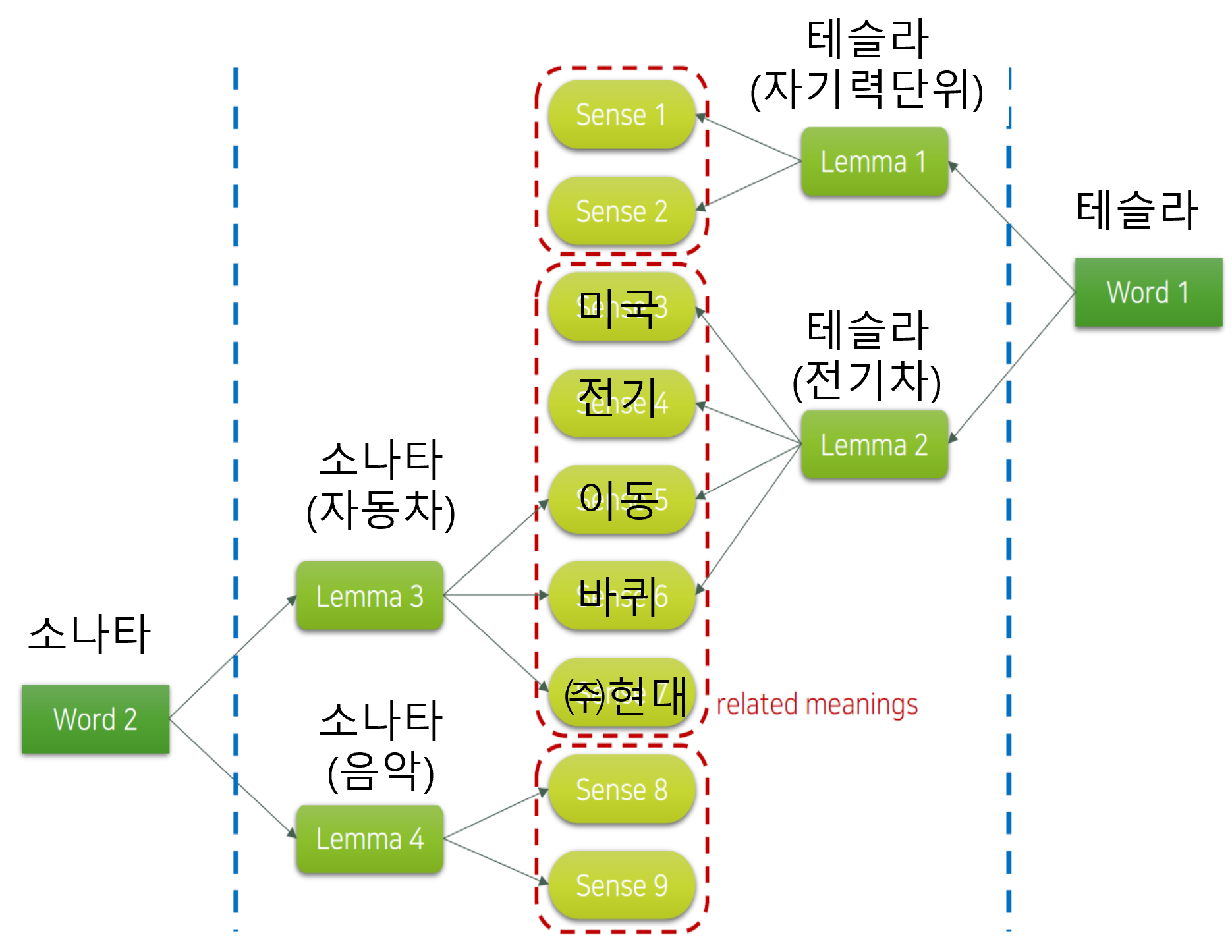 [이미지 출처: 김기현의 딥러닝을 활용한 자연어처리 입문, 패스트캠퍼스, 강의자료 중 일부 발췌]
[이미지 출처: 김기현의 딥러닝을 활용한 자연어처리 입문, 패스트캠퍼스, 강의자료 중 일부 발췌]
- 소나타:
- 자동차 이름 (Lemma 3)
- 음악 용어 (Lemma 4)
- 테슬라:
- 물리학 단위 (Lemma 1)
- 전기차 브랜드 (Lemma 2)

같은 단어(Word)라도 표제어가 다르면 완전히 다른 의미망을 형성한다.
5. 의미의 확장 관계
- 하나의 표제어에 여러 의미(Sense)가 파생
- 예: 테슬라(전기차)와 관련된 의미들 → 미국, 전기, 이동, 바퀴, 현대자동차 등
- 이는 related meanings로 묶여 서로 연결성을 가진다.
Tokenization
자연어 처리를 수행할 때 분절(Tokenization)은 텍스트를 의미 있는 단위로 나누는 가장 기초적인 단계이다. 이 과정은 크게 문장 분리(Sentence Segmentation)와 어절/단어 분리(Tokenization)로 나눌 수 있다.
Sentence Segmentation
문장을 학습 가능한 단위로 나누기 위해 문장 단위로 분리하는 과정을 말한다. 단순히 마침표(“.”)를 기준으로 분리하면 문장 내에서 마침표가 다른 의미로 사용될 때(예: U.S., 3.14 등) 오류가 발생한다. 따라서 보다 정교한 방법이 필요하다. 예를 들어, Python의 nltk.tokenize 모듈에서 제공하는 sent_tokenize 함수는 영어 텍스트를 기반으로 하며, 한국어도 비교적 잘 처리할 수 있다.
from nltk.tokenize import sent_tokenize
아래 예시처럼 긴 문장을 마침표 기준으로 잘못 나눌 수 있으므로 문맥을 고려한 분리가 필요하다.
-
원문:
North Korea's state mouthpiece, the Rodong Sinmun, is also keeping -
잘못된 분리:
North Korea 's state mouthpiece , the Rodong Sinmun , is also keeping
Tokenization
토크나이제이션은 문장을 다시 단어 단위(token)로 분리하는 작업이다. 목적은 여러 개의 단어들을 일관되게 나누어 학습 가능한 형태로 변환하는 것이다. 이렇게 함으로써 불필요하게 큰 vocabulary 크기를 줄이고, 희소성(sparseness)을 낮추어 모델 학습을 용이하게 만든다.
특히 한국어는 교착어이기 때문에 접사의 조합에 따라 다양한 의미가 파생된다. 또한 띄어쓰기 문제도 존재하는데, 다행히 한국어 화자는 대체로 잘 이해할 수 있지만 기계 학습 모델에는 큰 도전 과제가 된다.
이러한 이유로 형태소 분석기(POS, Part-of-Speech Tagger)를 활용해 토큰 단위로 문장을 분해하는 것이 필요하다. 형태소 분석을 통해 어휘의 품사와 문법적 역할을 파악하면 학습 데이터의 품질을 높이고, 문맥 기반의 의미 분석도 가능해진다.
👉 즉, 분절(Tokenization)은 자연어 처리에서 가장 기초적이지만, 언어적 특성(예: 한국어의 접사, 띄어쓰기 모호성)에 따라 구현 난이도가 크게 달라진다.
형태소 분석기 종류
형태소 분석기는 언어의 특성과 분석 목적에 따라 다양한 종류가 존재한다. 아래 표는 한국어, 일본어, 중국어에서 사용되는 대표적인 형태소 분석기와 그 특징을 정리한 것이다.
| 언어 | 분석기 이름 | 언어 | 특징 |
|---|---|---|---|
| 한국어 | Mecab | C++ | 일본어 Mecab을 wrapping. 속도가 가장 빠름 |
| 한국어 | KoNLPy | 복합 | 설치와 사용이 편리하나, 일부 tagger의 경우 속도가 느림 |
| 일본어 | Mecab | C++ | 속도가 가장 빠름 |
| 중국어 | Stanford Parser | Java | 미국 스탠퍼드에서 개발 |
| 중국어 | PKU Parser | Java | 북경대학교에서 개발 |
| 중국어 | Jieba | Python | 가장 최근에 개발. Python으로 제작되어 시스템 구성에 용이 |
- 한국어 Mecab은 일본어 Mecab을 wrapping하여 만든 것으로, 속도 면에서 가장 우수하다. 실제 연구에서도 성능 최적화를 위해 가장 많이 활용된다.
- KoNLPy는 Python 환경에서 편리하게 사용할 수 있도록 설계되었으며, 다양한 형태소 분석기를 통합 제공한다. 다만 일부 tagger의 속도가 느리다는 단점이 있다.
- 일본어 Mecab은 일본어 형태소 분석기 중 가장 빠른 성능을 자랑하며, 한국어 Mecab의 기반이 되었다.
- Stanford Parser는 영어와 중국어 모두에 활용 가능한 범용적인 분석기로, 문법 구조까지 고려하는 정밀 분석을 수행할 수 있다.
- PKU Parser는 중국 북경대학교에서 개발한 것으로, 학술 연구 목적으로 많이 사용된다.
- Jieba는 Python 기반의 최신 중국어 분석기로, 설치가 간단하고 시스템 통합에 용이하여 산업계에서도 많이 활용된다.
Tokenization & Detokenization 환경 구축
Mecab 설치 (로컬 PC CLI 환경에서 사용)
- 참고 블로그:
설치 가이드 바로가기
Python 코딩을 위한 설치
-
github에서 자신의 파이썬 버전과 OS에 맞게 다운로드
-
가상환경이 Python 3.8 이상이라면, 3.7 이하로 추가 생성 필요 (3.7까지만 지원됨 ㅠㅠ)
conda deactivate
conda create --name [가상환경 이름] python=3.7
source activate [가상환경 이름] # git bash 환경에서 실행 시
conda activate [가상환경 이름] # powershell 환경에서 실행 시
- 파이썬 코딩용 mecab 설치 ← 다운로드 받은 파일 활용
pip install mecab_python-0.996_ko_0.9.2_msvc-cp37m-win_amd64.whl
- 사용법
import MeCab
mecab = MeCab.Tagger()
print(mecab.parse('맥밥이 정상적으로 설치되었습니다.'))
- 실행 결과
맥 NNG,*,T,맥,*,*,*,*,*
밥 NNG,*,T,밥,*,*,*,*,*
이 JKS,*,F,이,*,*,*,*,*
정상 NNG,*,T,정상,*,*,*,*,*
적 XSN,*,T,적,*,*,*,*,*
으로 JKB,*,F,으로,*,*,*,*,*
설치 NNG,행위,F,설치,*,*,*,*,*
되 XSV,*,F,되,*,*,*,*,*
었 EP,*,T,었,*,*,*,*,*
습니다 EF,*,F,습니다,*,*,*,*,*
EOS
여전히 NLP 연구에서 형태소 분석기가 필요한가?
형태소 분석기, 여전히 필요한가?
최근 NLP 연구는 LLM 중심으로 전환되면서, 대부분의 경우 서브워드 토크나이저(BPE, SentencePiece 등)를 활용한다. 이 과정에서 띄어쓰기나 어절 문제를 상당 부분 해결할 수 있게 되었으며, 대규모 학습 데이터와 딥러닝 모델의 표현력 덕분에 전통적 형태소 분석의 필요성은 크게 줄어들었다.
그럼에도 불구하고…
- 언어학적 연구: 문법 연구와 언어 자원 구축을 위해 형태소 단위의 정밀한 분석은 여전히 필수적이다.
- 도메인 특화 작업
- 법률, 의학 텍스트 → 정밀한 의미 단위 추출 필요
- 저자원 언어 처리 → 데이터 효율성을 높이기 위해 형태소 분석이 여전히 유리
- Hybrid 접근: 일부 연구에서는 형태소 분석과 서브워드 토큰화를 함께 사용하는 방식이 성능 개선에 기여한다.
결론
- 일반 NLP 과제에서는 LLM 서브워드 토크나이저만으로도 충분히 처리할 수 있다.
- 그러나 특수 도메인이나 저자원 환경에서는 형태소 분석기가 여전히 중요한 가치를 가진다.
리눅스 환경에서 한글 및 Mecab 설치와 활용
리눅스 한글 패키지 설치

설치 방법
# ubuntu 터미널에서 한글 입력이 안되는 경우
$ apt install language-pack-ko
$ locale-gen ko_KR.UTF-8
$ locale # locale 확인
$ vi /root/.bashrc # 맨 아래에 다음 내용 추가 (sudo 권한 필요할 수 있음)
export LANG=ko_KR.UTF-8
export LC_ALL=ko_KR.UTF-8
Mecab 설치 (리눅스 – 우분투)
Ubuntu CLI 활용을 위한 설치
참고 블로그:
# Optional dev: Docker container 환경에서도 적용 가능.
apt update
apt install wget
wget https://bitbucket.org/eunjeon/mecab-ko/downloads/mecab-0.996-ko-0.9.2.tar.gz
tar xvfz mecab-0.996-ko-0.9.2.tar.gz
cd mecab-0.996-ko-0.9.2
./configure
make
make check
make install
ldconfig
mecab --version
Mecab-ko-dic 설치 (리눅스 – 우분투)
wget https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-2.1.1-20180720.tar.gz
tar xvfz mecab-ko-dic-2.1.1-20180720.tar.gz
cd mecab-ko-dic-2.1.1-20180720
./configure
make
make install
CLI 환경에서 Mecab 사용
echo '아버지가 방에 들어가신다' | mecab
실행 결과
아 NNG,*,F,아,*,*,*,*
버지 NNG,*,T,버지,*,*,*,*
가 JKS,*,F,가,*,*,*,*
방 NNG,장소,T,방,*,*,*,*
에 JKB,*,F,에,*,*,*,*
들어 VV,*,F,들어,*,*,*,*
가 VV,*,F,가,*,*,*,*
신다 EP+EC,*,F,신다,Inflect,EP,EC,*,*
EOS
참고
- 파이프(pipe) 명령어 | : 앞 명령어의 실행 결과를 다음 명령어 입력으로 전달
Mecab을 이용한 문장 Tokenization
- mecab의 -O wakati 옵션 활용
$ echo '아버지가 방에 들어가신다' | mecab -O wakati
# 실행 결과
아버지 가 방 에 들어 가 신다
- 파일 입력 사용
$ mecab -O wakati < tokenization_toy_example.txt
재지향(redirection) 명령 >, >>, <, <<: 연산 결과를 다른 장치로 보내는 명령
Tokenization 관련 유용한 명령어
- cut: 파일에서 특정 필드 추출
$ cut -f n 파일명
- head: 파일의 앞부분 일부 출력
$ head -f n 파일명