Theory of Deeplearning and Frameworks
Introduction: NLP와 딥러닝의 관계
자연어처리(NLP)의 정의와 범위
자연어(Natural Language)란?
자연어란 사람들이 일상적으로 사용하는 언어를 의미한다. 즉, 사람이 사고하고 의사소통하기 위해 사용하는 실제 언어를 가리킨다. 이에 대한 정의는 여러 가지로 시도되어 왔는데, 공통적으로 강조되는 핵심은 사람의 생각과 감정을 다른 사람에게 전달하는 체계라는 점이다.
첫째, 언어는 사람들의 머릿속에 있는 생각을 다른 사람에게 나타내는 체계라고 할 수 있다. 말, 행동, 감정, 생각, 그리고 상태를 표현하는 수단이 바로 언어이다. 둘째, 언어는 자신이 가진 생각을 다른 사람에게 전달하기 위해 사용하는 방법이다. 이는 언어가 단순한 기호의 나열이 아니라, 사회적 상호작용을 가능하게 하는 수단임을 보여준다. 셋째, 언어는 사람들 사이에서 공유되는 의미의 체계이다. 즉, 특정한 집단이 합의한 약속을 통해 서로 소통할 수 있게 해준다. 넷째, 언어는 문법적으로 맞는 문장의 집합이기도 하다. 하지만 반드시 문법적 정확성만으로 정의되는 것은 아니며, 상황적·문화적 맥락 속에서 이해되는 표현까지 포괄한다. 마지막으로, 언어는 공동체 내에서 이해될 수 있는 말의 집합으로 볼 수 있다. 이는 언어가 개인의 사고 표현 수단을 넘어 사회적, 문화적 규약 속에서 의미를 가지는 체계임을 시사한다.
결론적으로, 자연어란 정보를 전달하기 위한 수단이라고 할 수 있다. 사람들은 자연어를 통해 자신의 생각과 감정을 타인과 공유하며, 이러한 과정이 사회적 상호작용과 지식의 축적을 가능하게 한다.
형식언어(Formal Language)란?
형식언어는 특정한 목적을 위해 인위적으로 설계된 언어 체계를 의미한다. 주로 수학, 논리학, 컴퓨터 과학 분야에서 사용되며, 명확성과 일관성이 핵심적인 특징이다. 자연어가 사회적 상호작용을 통해 자연스럽게 진화한 언어라면, 형식언어는 정의된 규칙과 문법에 따라 엄격하게 구성된 기호의 집합이라고 할 수 있다.
형식언어의 문법은 수학적으로 정의할 수 있으며, 문장을 생성하거나 판별하는 과정이 기계적으로 가능하다. 예를 들어, 프로그래밍 언어(C, Python, Java), 수학적 공식, 논리식, 정규표현식 등이 모두 형식언어에 해당한다. 이러한 언어는 모호성이 존재하지 않으며, 같은 표현은 항상 동일한 의미로 해석된다.
따라서 형식언어는 기계 처리에 적합하고, 프로그래밍, 컴파일러, 자동 추론, 형식 검증(Formal Verification)과 같은 영역에서 핵심적인 역할을 담당한다.
| 구분 | 자연어 (Natural Language) | 형식언어 (Formal Language) |
|---|---|---|
| 기원 | 사회적 상호작용 속에서 자연스럽게 발생·진화 | 특정 목적을 위해 인위적으로 설계 |
| 문법 규칙 | 불규칙성과 예외 많음, 맥락 의존적 | 명확하고 엄격한 문법 기반 |
| 모호성 | 다의어, 중의성, 은유 등 모호성이 내포됨 | 모호성 없음, 항상 동일한 의미로 해석됨 |
| 표현력 | 의미적으로 풍부하고 직관적 | 목적에 맞게 제한적, 수학적·논리적 정밀성 강조 |
| 처리 주체 | 인간에게 직관적, 기계 처리 어려움 | 기계 처리에 적합, 자동화 및 계산 가능 |
| 응용 분야 | 일상 언어, 문학, 의사소통, 사회적 상호작용 | 프로그래밍 언어, 논리식, 수학, 자동 추론, 검증 등 |
언어의 벽을 넘는 것은 신의 영역인가?

인류 역사 속에서 언어는 소통의 도구이자 동시에 장벽이 되어 왔다. 성경 속 바벨탑 사건은 언어의 혼잡을 상징적으로 보여준다. 사람들이 하나의 언어를 사용하며 하늘에 닿는 탑을 쌓으려 했을 때, 신은 인간의 교만을 꺾기 위해 언어를 흩뜨려 서로 의사소통할 수 없도록 만들었다는 이야기다. 이는 언어가 인간 사회를 단절시키는 결정적인 장벽이 될 수 있음을 상징적으로 드러낸다.
현대 사회에서도 언어 장벽은 국가와 문화를 가로막는 큰 장애물로 남아 있다. 그러나 인공지능의 발전은 이러한 장벽을 허물 수 있는 새로운 가능성을 제시한다. 최근의 기계 번역 시스템은 단순한 단어 치환 수준을 넘어, 문맥과 의미를 반영하여 점점 더 자연스러운 번역을 제공하고 있다. Google Translate, Papago와 같은 인공지능 번역기는 이미 일상에서 널리 활용되며, 전 세계 사람들 간의 의사소통을 실질적으로 가능하게 하고 있다.
그렇다면 언어의 벽을 넘어서는 일은 과연 신의 영역일까, 아니면 기술의 진보를 통해 인간이 성취할 수 있는 새로운 도전일까? 이 질문은 단순히 번역 기술의 정확도를 넘어, 인공지능이 인간 사회에서 어떤 역할을 맡아야 하는지에 대한 중요한 철학적 성찰을 요구한다.
-
인공지능 번역 기술이 발전하면서, 언어 다양성은 보존될까 아니면 약화될까?
인공지능 번역 기술은 언어 장벽을 허물어 다양한 언어 간의 상호 이해를 가능하게 하지만, 동시에 언어 다양성을 약화시킬 위험도 내포하고 있다. 번역의 품질이 특정 언어 쌍(예: 영어 ↔ 주요 세계 언어)에서 압도적으로 우수할 경우, 소수 언어 사용자들은 점차 다수를 차지하는 언어로 전환하려는 압력을 받게 된다. 반면, 인공지능이 소수 언어까지 학습하고 지원한다면 오히려 사라져 가는 언어를 보존하는 도구가 될 수도 있다. 결국 언어 다양성의 보존 여부는 기술 발전 그 자체보다도 사회가 기술을 어떤 방식으로 활용하고 관리하는가에 달려 있다고 할 수 있다.
-
바벨탑 사건의 교훈을 고려할 때, 언어의 통일과 다양성 중 어떤 것이 인류에게 더 바람직한가?
언어의 통일은 효율적인 의사소통과 글로벌 협력을 촉진하는 장점이 있다. 그러나 바벨탑 사건의 은유처럼, 지나친 통일은 다양성과 창의성을 저해할 수 있으며, 특정 권력 구조를 강화하는 수단이 될 위험이 있다. 반대로 언어의 다양성은 문화적 정체성을 보존하고, 사고와 표현의 폭을 넓혀 인간 사회의 풍부함을 유지한다. 따라서 인류에게 바람직한 방향은 완전한 통일도 아니고 무질서한 분열도 아니다. 효율성과 다양성의 균형을 추구하는 방향, 즉 공통 언어를 활용한 협력과 동시에 고유 언어의 보존을 병행하는 방식이 바람직하다고 할 수 있다.
-
인공지능이 언어 장벽을 허무는 과정에서, 문화적 맥락과 정체성의 손실은 어떻게 다뤄야 하는가?
언어는 단순한 의사소통 수단이 아니라, 문화와 정체성이 반영된 중요한 자산이다. 인공지능 번역기는 문법적 정확성에서는 뛰어나지만, 문화적 함의나 맥락적 뉘앙스를 온전히 전달하기 어렵다. 이 문제를 해결하기 위해서는 기술적 보완과 사회적 장치가 함께 필요하다. 예를 들어, 번역 시스템에 문화적 지식 그래프를 통합하거나, 인류학적·언어학적 데이터를 반영하는 방식이 고려될 수 있다. 더 나아가, 사용자가 번역 결과를 비판적으로 해석할 수 있도록 언어 교육과 문화 감수성 교육이 병행되어야 한다.
-
언어의 장벽을 넘는 것이 과연 신의 권한을 인간이 대신하는 행위일까, 아니면 기술적 진보로 인한 자연스러운 결과일까?
언어의 장벽을 허무는 행위를 종교적 시각에서는 신의 영역에 대한 도전으로 볼 수도 있다. 바벨탑 사건에서처럼, 언어의 혼잡은 인간의 오만에 대한 경고였다는 해석도 가능하다. 그러나 인공지능 번역 기술을 기술사적 관점에서 본다면, 이는 인류가 언어라는 복잡한 체계를 이해하고 응용해온 자연스러운 진화 과정이라고 할 수 있다. 바퀴의 발명이나 전기의 활용처럼, 언어 장벽을 넘는 기술 역시 인류가 협력과 소통을 확대하기 위해 발전시켜온 하나의 산물이다. 따라서 이 문제는 신성 모독의 영역이라기보다, 인류가 기술을 통해 사회적 한계를 어떻게 확장할 것인가라는 질문으로 이해하는 것이 더 적절하다.
자연어처리(Natural Language Processing, NLP)는 사람이 사용하는 언어를 기계가 이해하고 처리할 수 있도록 하는 기술이다. NLP의 목표는 크게 NLU(Natural Language Understanding)와 NLG(Natural Language Generation) 두 가지로 나눌 수 있다.
Natural Language Understanding (NLU)
Natural Language Understanding, 줄여서 NLU는 사람이 사용하는 언어를 단순히 기호나 텍스트로 받아들이는 것을 넘어, 그 안에 담긴 의미를 기계가 이해하도록 만드는 과정을 말한다. 예를 들어, “오늘 서울 날씨 알려줘”라는 문장은 단순한 한 줄의 문자열이지만, 사람이 듣고 이해하는 방식에는 ‘오늘’이라는 시간 개념과 ‘서울’이라는 장소, 그리고 ‘날씨를 알고 싶다’라는 의도가 함께 담겨 있다.
NLU는 이러한 문장에서 시간, 장소, 의도와 같은 의미 단위(semantic units) 를 식별하여 구조화된 형태로 표현하는 것을 목표로 한다. 이 과정을 통해 기계는 단순한 텍스트를 넘어 실제 세계의 맥락과 연결된 의미를 파악할 수 있으며, 사용자의 요청을 적절하게 처리할 수 있게 된다.
다시 말해, NLP가 “문자를 다루는 기술”이라면, NLU는 “문자의 의미를 해석하는 기술”이라고 할 수 있다. 따라서 NLU는 챗봇, 음성비서, 검색 엔진, 질의응답 시스템과 같은 응용 서비스의 핵심적인 기반이 된다.
주요 태스크
대표적인 문제 중 첫 번째는 의도 인식(Intent Recognition) 이다. 이는 사용자가 문장을 통해 무엇을 하고자 하는지 파악하는 과정이다. 예를 들어 “오늘 서울 날씨 알려줘”라는 발화에서는 사용자가 원하는 행동이 ‘날씨를 알고 싶다’는 것이므로, 이 문장은 날씨 질의(WeatherQuery)라는 의도로 분류될 수 있다. 의도 인식은 챗봇이나 음성 비서가 사용자의 질문을 적절한 기능이나 서비스로 연결하는 데 핵심적인 역할을 한다.
두 번째는 개체명 인식(Named Entity Recognition, NER) 이다. 이는 문장에서 인물, 장소, 시간, 조직과 같은 특정한 의미 단위를 찾아내는 작업이다. 앞의 예에서 “서울”은 장소(Location)라는 개체로 인식될 수 있다. 개체명 인식은 검색 엔진이나 추천 시스템에서 중요한 역할을 하며, 문장의 구체적 의미를 기계가 구조화하는 데 기초가 된다.
세 번째는 의미 분석(Semantic Parsing) 이다. 이는 문장을 논리적이고 구조화된 형태로 변환하는 과정이다. 단순히 의도와 개체를 찾는 수준을 넘어서, 문장 전체의 의미 관계를 파악하는 것이다. 예를 들어 “오늘 서울 날씨 알려줘”라는 문장은 Query(Location=서울, Date=오늘)과 같은 구조화된 표현으로 바뀔 수 있다. 이 단계는 데이터베이스 질의나 지식 그래프 탐색과 같은 고급 응용에서 특히 중요하다.
네 번째는 대명사 해소(Coreference Resolution) 이다. 이는 문맥 속에서 ‘그녀’, ‘그’, ‘그것’과 같은 대명사가 정확히 무엇을 가리키는지 찾아내는 과정이다. 예를 들어 “영희가 밥을 먹었다. 그녀는 배가 부르다.”라는 문장에서 ‘그녀’가 ‘영희’를 의미한다는 사실을 파악해야 올바른 이해가 가능하다.
마지막으로, 텍스트 분류(Text Classification) 역시 NLU의 대표적인 태스크 중 하나이다. 문장을 특정한 범주로 분류하는 작업으로, 대표적인 예로는 감정 분석, 주제 분류, 스팸 탐지 등이 있다. 예를 들어 “이 영화 정말 재미있다”라는 문장은 긍정적인 감정(Positive Sentiment)으로 분류될 수 있다. 이러한 분류는 소셜 미디어 분석이나 자동 리뷰 평가와 같은 실제 응용 서비스에서 널리 활용된다.
전통적 접근 vs 딥러닝 접근
NLU 연구는 오랫동안 전통적인 방법론을 중심으로 발전해왔다. 초기에는 규칙 기반(Rule-based) 접근이 주를 이루었는데, 이는 사람이 직접 문법 규칙이나 패턴을 정의하고 이를 통해 문장을 분석하는 방식이었다. 예를 들어, 특정 정규식을 만들어서 날짜나 시간을 인식하거나, 품사 사전을 활용하여 문장을 분해하는 방식이 대표적이다. 이러한 접근은 단순하고 직관적이라는 장점이 있지만, 새로운 표현이나 예외적인 문장을 처리하기 어려우며 유지보수 비용이 높다는 단점이 있었다.
이후에는 통계적 접근(Statistical Methods) 이 활발히 사용되었다. 대표적으로 N-gram 모델, 은닉 마코프 모델(Hidden Markov Model, HMM), 조건부 확률장을 기반으로 하는 CRF(Conditional Random Field) 등이 있다. 이러한 모델들은 주어진 데이터에서 확률적 규칙을 학습하여 새로운 입력에 대응할 수 있다는 점에서 규칙 기반보다 훨씬 유연했다. 하지만 여전히 단어 간 긴 의존성을 포착하기 어렵고, 사람이 직접 설계해야 하는 특징(feature engineering)이 필수적이라는 한계가 있었다.
반면, 최근의 NLU 연구는 딥러닝 기반 접근으로 전환되면서 큰 도약을 이루었다. 딥러닝 모델은 데이터를 통해 직접 특징을 학습하기 때문에, 별도의 복잡한 Feature Engineering이 필요하지 않다. 초기에는 단어 임베딩(Word2Vec, GloVe)과 RNN, LSTM 같은 신경망 구조가 사용되었고, 이후 CNN이 텍스트 패턴 인식에도 활용되었다. 특히 Transformer 구조가 제안된 이후, BERT나 GPT와 같은 대규모 사전학습 언어모델(Pretrained Language Models)이 NLU의 표준이 되었다. 이러한 모델들은 긴 문맥을 효과적으로 처리하고, 대규모 데이터를 활용하여 다양한 태스크에 범용적으로 적용될 수 있다는 점에서 기존 통계적 방법을 압도하는 성능을 보여주고 있다.
결과적으로, 전통적 접근은 규칙성과 단순한 통계에 기반한 제한적인 이해에 머물렀다면, 딥러닝 접근은 문맥적 의미를 동적으로 반영하고 확장 가능한 구조를 제공함으로써 실제 인간 수준의 이해에 가까워진 단계로 발전했다고 볼 수 있다.
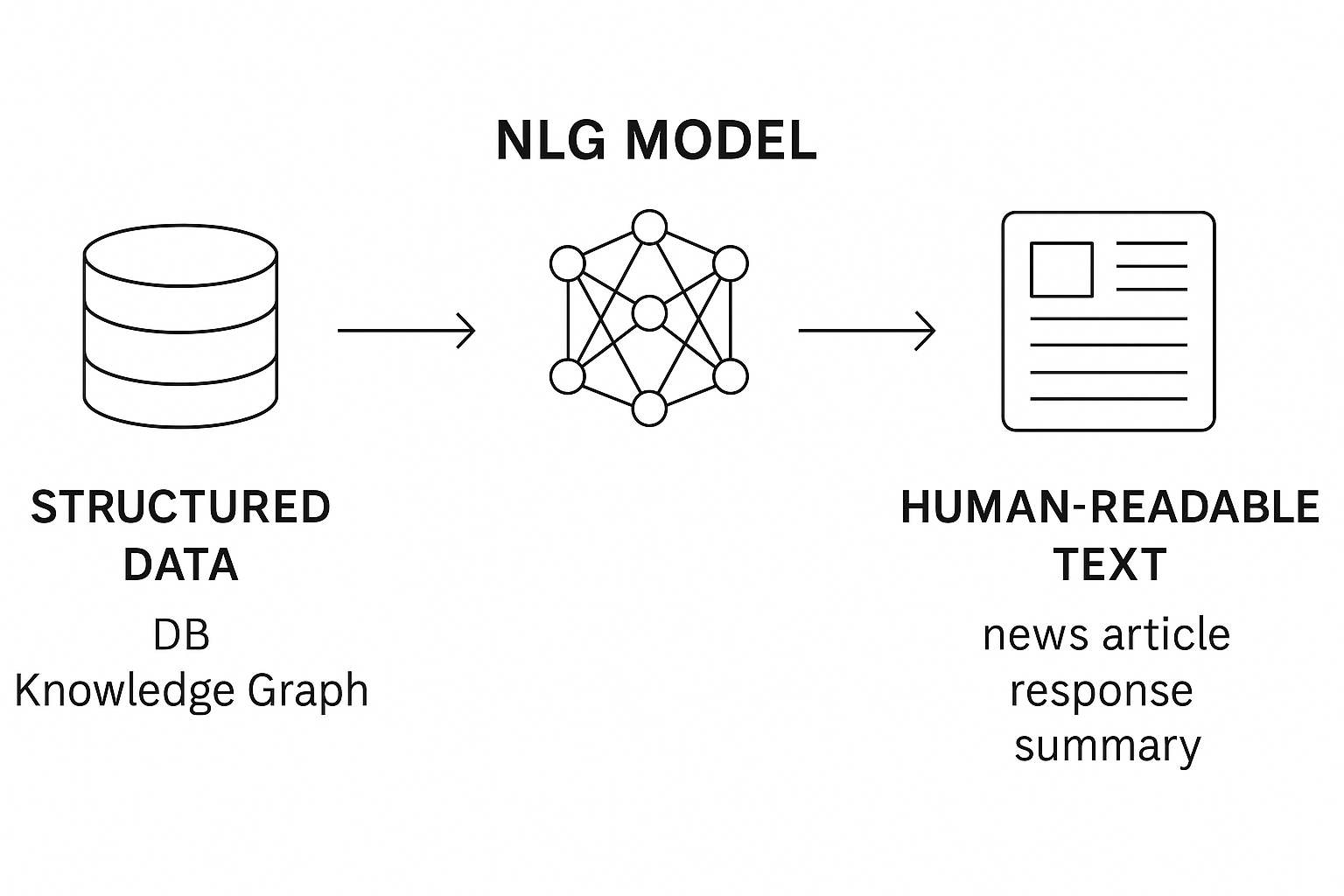
Natural Language Generation (NLG)
Natural Language Generation, 줄여서 NLG는 기계 내부의 데이터를 사람이 이해할 수 있는 자연스러운 언어로 변환하는 과정이다. NLU가 인간 언어를 기계가 해석하는 것이라면, NLG는 그 반대 방향에 해당한다. 예를 들어, 데이터베이스에 저장된 날씨 정보를 “오늘 서울의 날씨는 맑고 기온은 25도입니다.”라는 문장으로 표현하는 과정이 바로 NLG이다.
즉, NLG는 단순히 텍스트를 나열하는 것이 아니라, 맥락과 문법, 의미를 고려하여 사람이 읽기 자연스러운 문장을 생성하는 기술이다. 최근의 대화형 인공지능 서비스(예: ChatGPT, Claude, Gemini 등)는 모두 고도화된 NLG 기술을 기반으로 한다.
주요 태스크
-
데이터-투-텍스트 변환 (Data-to-Text Generation)
- 조화된 데이터를 자연어 문장으로 변환
- 예: 주식 시장 데이터 → “오늘 코스피 지수는 2500선을 돌파했습니다.”
-
기계 번역 (Machine Translation)
- 한 언어의 텍스트를 다른 언어로 변환
- 예: “I love NLP” → “나는 자연어처리를 좋아한다.”
-
요약 (Summarization)
- 긴 문서를 짧게 요약
- 추출적 요약(Extractive), 생성적 요약(Abstractive) 두 가지 방식 존재
-
대화 응답 생성 (Dialogue Response Generation)
- 사용자의 입력에 맞는 자연스러운 응답 생성
- 예: 사용자: “오늘 날씨 어때?” → 시스템: “맑고 기온은 25도입니다.”
-
콘텐츠 생성 (Creative Generation)
- 기사, 시, 소설, 코드 등 창의적인 텍스트를 생성
- 최근 LLM 모델들이 활발히 사용되는 영역
전통적 접근 vs 딥러닝 접근
과거의 전통적 NLG는 템플릿 기반 방식에 의존했다. 예를 들어 “오늘 [도시]의 날씨는 [기온]도입니다.”와 같은 틀(template)을 만들고, 데이터를 해당 위치에 삽입하는 방식이다. 이는 구현이 간단하지만, 다양성과 유창성이 부족하고 예외적인 상황에 대응하기 어렵다.
반면 딥러닝 접근은 신경망 기반 생성 모델을 활용한다. 초기에는 RNN과 LSTM을 사용하여 순차적으로 단어를 생성했으며, 이후 Attention 메커니즘과 Transformer 구조의 등장으로 성능이 비약적으로 향상되었다. 특히 GPT 시리즈와 같은 대규모 언어모델은 거대한 사전학습 덕분에 문법적 일관성과 의미적 풍부함을 동시에 갖춘 자연스러운 문장을 생성할 수 있게 되었다.
코드 예시: 텍스트 생성 (PyTorch, GPT-2 활용)
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
prompt = "Natural Language Generation is"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(inputs["input_ids"], max_length=30, do_sample=True, top_k=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
위 코드는 Hugging Face의 Transformers 라이브러리를 활용하여 GPT-2 모델로 텍스트를 생성하는 간단한 예제이다. 먼저 GPT2Tokenizer와 GPT2LMHeadModel을 불러와, 사전학습(pretrained)된 GPT-2 모델과 그에 맞는 토크나이저를 로드한다. 토크나이저는 입력 문장을 모델이 이해할 수 있는 토큰 단위의 정수 벡터로 변환하는 역할을 한다.
프롬프트(prompt)로는 "Natural Language Generation is"라는 문자열이 주어진다. 이는 모델이 이후에 이어질 문장을 생성하는 출발점 역할을 한다. 이 프롬프트는 토크나이저를 통해 토큰화되어 PyTorch 텐서 형태로 변환된다.
그 다음 model.generate() 함수가 호출되면서 실제 문장 생성이 이루어진다. 여기서 max_length=30은 생성되는 문장의 최대 길이를 30 토큰으로 제한하는 옵션이며, do_sample=True와 top_k=50은 생성 과정에서 무작위성을 부여하여 더 다양한 문장을 만들어내도록 설정한 것이다. 즉, 항상 같은 결과를 출력하지 않고, 확률적으로 선택된 상위 50개의 단어 후보 중 하나를 샘플링하여 다음 단어를 예측한다.
마지막으로, 생성된 토큰 시퀀스는 tokenizer.decode()를 통해 다시 사람이 읽을 수 있는 자연어 문장으로 변환된다. 이렇게 출력된 문장은 GPT-2가 학습 과정에서 습득한 언어 패턴을 기반으로 자연스럽게 이어진 텍스트가 된다.
이 예시는 단순한 코드이지만, 실제로는 프롬프트를 어떻게 주느냐에 따라 생성되는 결과가 달라지는 프롬프트 엔지니어링(prompt engineering)의 중요성을 보여주며, 또한 NLG 모델이 인간처럼 문장을 생성하는 방식을 직관적으로 이해할 수 있게 한다.
Discussion Questions
-
전통적 템플릿 기반 NLG와 신경망 기반 NLG의 가장 큰 차이는 무엇인가?
템플릿 기반 NLG는 사람이 미리 정의한 문장 구조 안에 데이터를 채워 넣는 방식이다. 따라서 단순하고 빠르게 결과를 얻을 수 있지만, 표현의 다양성과 문맥적 유연성이 부족하다. 반대로 신경망 기반 NLG는 방대한 데이터에서 문장 구조와 표현 방식을 스스로 학습한다. 이 덕분에 문법적으로 더 자연스럽고, 맥락에 맞는 문장을 생성할 수 있다. 즉, 규칙 중심의 고정된 방식에서 데이터 중심의 학습적 방식으로 진화했다는 점이 가장 큰 차이다.
-
NLG 모델이 인간처럼 자연스러운 문장을 만들기 위해 필요한 요소는 무엇일까? (문법, 맥락, 상식, 창의성)
NLG 모델이 진정으로 자연스러운 문장을 생성하기 위해서는 여러 요소가 종합적으로 작동해야 한다. 먼저, 문법적 정확성이 확보되어야 하며, 어휘와 문장 구조가 올바르게 생성되어야 한다. 두 번째로, 맥락 이해가 필요하다. 동일한 단어라도 상황에 따라 의미가 달라질 수 있으므로, 대화의 흐름이나 주제에 맞는 표현을 선택해야 한다. 세 번째로, 상식(Commonsense reasoning)이 중요하다. 예를 들어 “고양이가 피자를 먹었다”라는 문장은 문법적으로 맞지만 일반적이지 않다는 점을 구분할 수 있어야 한다. 마지막으로, 창의성 역시 필요하다. 단순히 문법적으로 올바른 문장이 아니라, 사람이 쓴 듯 자연스럽고 풍부한 표현을 생성하는 능력이 인간 수준의 NLG를 결정짓는 핵심 요소이다.
-
대규모 언어모델(LLM) 기반 NLG가 사회에 미치는 긍정적/부정적 영향은 무엇일까?
LLM 기반 NLG는 사회적으로 긍정적인 영향과 부정적인 영향을 동시에 가져온다. 긍정적인 면에서는 자동 번역, 문서 요약, 지식 검색, 대화형 인공지능 서비스 등을 통해 정보 접근성을 높이고 생산성을 향상시킨다. 연구자와 학생은 더 빠르게 지식을 습득할 수 있고, 기업은 고객 서비스 효율을 크게 개선할 수 있다. 그러나 부정적인 측면도 존재한다. 모델이 학습한 데이터의 편향(Bias)이 그대로 반영될 수 있으며, 허위 정보(Hallucination)를 사실처럼 만들어낼 위험이 있다. 또한, 대량의 자동화된 텍스트가 사회적으로 스팸, 가짜뉴스, 저작권 문제로 이어질 가능성도 있다. 따라서 LLM 기반 NLG의 활용은 그 잠재적 혜택을 극대화하면서 동시에 위험을 제어하기 위한 윤리적·법적 장치가 함께 마련되어야 한다.
딥러닝이 NLP를 변화시킨 방식
딥러닝은 자연어처리의 패러다임을 근본적으로 바꾸어 놓았다. 그 중에서도 가장 중요한 변화 중 하나는 표현 학습(Representation Learning) 이다. 과거에는 단어를 One-hot 인코딩과 같이 희소하고 고차원의 벡터로 표현했기 때문에, 단어 간의 유사성을 반영하지 못했다. 그러나 Word2Vec이나 GloVe와 같은 임베딩 기법은 단어를 조밀하고 의미적인 정보가 담긴 벡터로 변환함으로써, 단어 간의 관계를 수학적 공간에서 직접적으로 계산할 수 있게 만들었다. 이후에는 BERT, GPT와 같은 대규모 언어모델이 등장하면서, 단어를 넘어 문맥 전체를 반영한 표현 학습이 가능해졌다.
또 다른 변화는 End-to-End 학습 방식의 확산이다. 과거 전통적 NLP에서는 토큰화, 불용어 제거, 특징 추출과 같은 전처리와 Feature Engineering 과정이 반드시 필요했다. 그러나 딥러닝 기반 접근은 이러한 과정을 최소화하고, 원시 텍스트를 바로 입력으로 받아 출력까지 직접 연결하는 신경망 구조를 가능하게 했다. 이는 연구자의 개입을 줄이고, 데이터 기반으로 더 일반화된 모델을 구축할 수 있도록 하였다.
마지막으로, 딥러닝은 대규모 사전학습(Pretraining) 이라는 새로운 학습 패러다임을 열었다. 방대한 양의 텍스트 데이터를 바탕으로 언어모델을 미리 학습시킨 뒤, 특정 태스크에 맞게 미세조정(Fine-tuning)하는 방식이다. 이 접근은 다양한 자연어처리 문제에 범용적으로 적용될 수 있으며, 적은 양의 태스크별 데이터로도 높은 성능을 발휘하게 한다. 최근의 LLM들은 이러한 사전학습 기반 접근을 통해 인간 수준에 가까운 성능을 보이고 있으며, NLP의 응용 범위를 폭발적으로 확장시키고 있다.
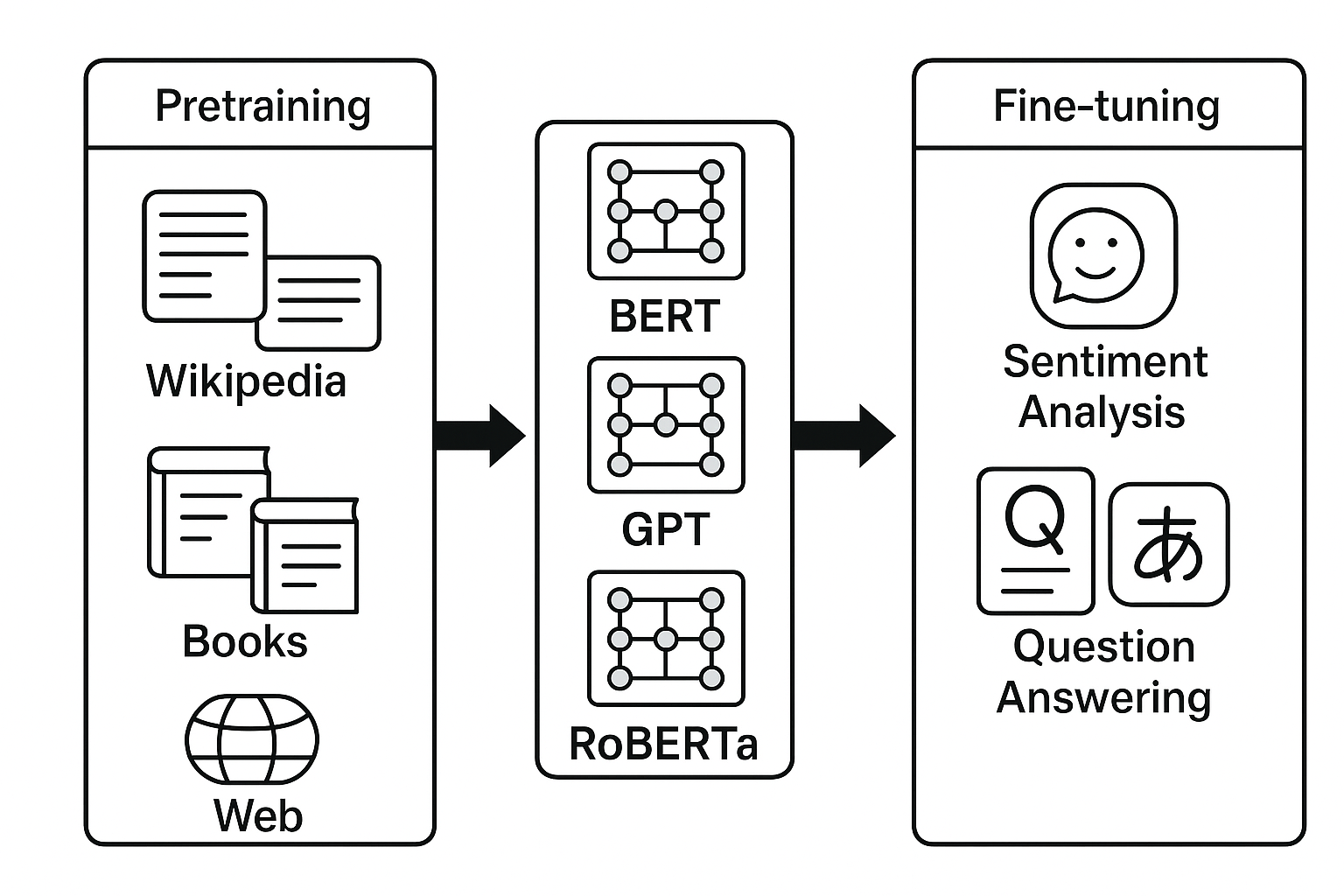
대규모 사전학습(Pretraining) 방식
대규모 사전학습(Pretraining)이란, 방대한 양의 텍스트 데이터를 활용해 언어모델을 범용적 언어 표현 학습기로 만드는 과정이다. 이후 특정 태스크(예: 감정 분석, 기계 번역, 질의응답)에 맞추어 파인튜닝(Fine-tuning) 수행하면, 훨씬 적은 데이터와 계산 자원으로도 뛰어난 성능을 얻을 수 있다.
이 접근법은 NLP의 학습 방식을 크게 바꿨다. 과거에는 각 태스크마다 별도의 모델을 설계해야 했지만, 사전학습된 모델을 공유하면서 효율성과 범용성이 동시에 확보되었다.
주요 사례
(1) BERT (Bidirectional Encoder Representations from Transformers, 2018) - 구조: Transformer Encoder 기반 - 학습 방식: Masked Language Modeling (MLM) + Next Sentence Prediction (NSP) - 특징: 문맥을 양방향(Bidirectional)으로 이해 가능 - 활용: 문장 분류, NER, 질의응답 등 다운스트림 태스크
(2) GPT (Generative Pretrained Transformer, 2018~현재) - 구조: Transformer Decoder 기반 - 학습 방식: Left-to-right Language Modeling (Auto-regressive) - 특징: 문맥을 순차적으로 예측, 텍스트 생성에 강점 - 활용: 대화형 모델, 글쓰기 보조, 코드 생성 등
(3) RoBERTa (Robustly Optimized BERT Approach, 2019) - 구조: BERT와 동일 (Encoder) - 개선점: - NSP 제거 → 학습 효율 ↑ - 더 많은 데이터, 더 긴 학습 → 성능 ↑ - 특징: BERT의 한계를 개선한 강력한 이해 중심 모델
-
Pretraining → Fine-tuning 파이프라인
-
Pretraining: 대규모 코퍼스에서 언어모델 학습
- 예: Wikipedia, BookCorpus, OpenWebText
-
Fine-tuning: 특정 태스크 데이터로 모델 조정
- 예: 감정 분석(SST-2), NER(CoNLL-2003), 질의응답(SQuAD)
이 방식은 “한 번 크게 학습하고, 여러 태스크에서 재사용”한다는 점에서 혁신적이다.
실제 코드 예시: 전통적 ML vs 딥러닝 비교
전통적 ML 기반 텍스트 분류 (Scikit-learn, TF-IDF + Logistic Regression)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
texts = ["I love NLP", "NLP is hard", "I hate homework"]
labels = [1, 0, 0]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
clf = LogisticRegression()
clf.fit(X, labels)
print(clf.predict(vectorizer.transform(["I love homework"])))
전통적인 머신러닝 기법을 활용한 텍스트 분류 방식을 살펴보자. 전형적인 방법은 TF-IDF(Term Frequency – Inverse Document Frequency) 같은 통계적 방법으로 문장을 벡터화한 뒤, Logistic Regression과 같은 선형 분류기를 적용하는 것이다.
예를 들어, “I love NLP”, “NLP is hard”, “I hate homework”라는 세 개의 문장을 각각 긍정과 부정의 레이블로 분류하는 상황을 가정해 보자. 이때 Scikit-learn의 TfidfVectorizer를 이용하여 각 문장을 희소 벡터 형태로 변환하고, 그 결과를 LogisticRegression 모델에 학습시킨다. 이렇게 학습된 모델은 새로운 입력 문장인 “I love homework”을 받아 긍정(1) 또는 부정(0)으로 분류하게 된다.
이 방식은 구현이 간단하고 적은 데이터로도 동작한다는 장점이 있지만, 문맥 정보를 잘 반영하지 못하고 단어의 순서나 의미적 유사성을 고려하기 어렵다는 한계를 가진다. 따라서 현대의 NLP에서는 이러한 전통적 접근 대신, 딥러닝 기반 방법이 점차 주류를 차지하게 되었다.
딥러닝 기반 텍스트 분류 (PyTorch, 간단한 MLP)
import torch
import torch.nn as nn
import torch.optim as optim
# 임베딩된 입력 (예시)
X = torch.rand(3, 100) # 3개 문장, 100차원 벡터
y = torch.tensor([1, 0, 0])
model = nn.Sequential(
nn.Linear(100, 50),
nn.ReLU(),
nn.Linear(50, 2)
)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(10):
outputs = model(X)
loss = criterion(outputs, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
전통적인 TF-IDF + 선형 분류기 방식과 달리, 딥러닝 기반 접근은 문장을 고정된 규칙 없이 데이터에서 직접 표현을 학습한다는 점이 가장 큰 특징이다. 예를 들어, 문장을 임베딩 벡터 형태로 변환한 뒤, 다층 퍼셉트론(MLP)과 같은 신경망을 통해 분류를 수행할 수 있다.
이 과정에서는 단순히 단어의 등장 여부만 보는 것이 아니라, 벡터 공간에서 단어 간의 의미적 유사성과 문맥적 관계까지 반영할 수 있다. 예를 들어 “I love NLP”와 “I enjoy studying NLP”는 단어가 다르더라도 의미적으로 유사하기 때문에, 딥러닝 모델은 두 문장을 비슷한 벡터 공간에 위치시킬 수 있다. 이는 전통적인 TF-IDF 방식으로는 쉽게 얻기 어려운 장점이다.
또한, 딥러닝 모델은 학습 과정에서 자동으로 특징(Feature)을 추출하기 때문에, 연구자가 일일이 Feature Engineering을 설계할 필요가 없다. 이는 특히 대규모 데이터셋에서 모델이 더 풍부한 패턴을 학습하게 하며, 다양한 태스크에 범용적으로 활용될 수 있는 기반이 된다.
Discussions
전통적 NLP와 딥러닝 기반 NLP의 본질적 차이는 무엇인가?
전통적 NLP는 사람이 직접 규칙을 정의하거나, 단어 빈도와 같은 통계적 특징을 추출해 모델에 입력하는 방식이었다. 따라서 모델의 성능은 얼마나 정교하게 특징을 설계하느냐에 크게 의존했다. 반면, 딥러닝 기반 NLP는 이러한 과정을 데이터와 신경망이 스스로 학습하는 방식으로 대체했다. 즉, 사람이 설계한 규칙 대신 신경망이 대규모 데이터를 통해 언어의 의미적 표현을 자동으로 추출한다. 이 차이는 곧 지식 공학 중심의 접근에서 데이터 중심의 접근으로의 전환을 의미하며, NLP 연구의 효율성과 성능을 동시에 끌어올린 핵심 요인이라 할 수 있다.
왜 2018년 이후 대부분의 NLP 연구가 Transformer 기반으로 전환되었을까?
2018년 Google의 “Attention is All You Need” 논문을 통해 제안된 Transformer 구조는 RNN과 LSTM의 한계를 극복하면서 NLP 연구의 판도를 바꿔 놓았다. Transformer는 자기어텐션(Self-Attention) 메커니즘을 통해 긴 문맥 정보를 병렬적으로 처리할 수 있으며, GPU 연산에 최적화되어 대규모 데이터 학습이 가능하다. 그 결과, BERT, GPT, RoBERTa 등 사전학습 언어모델이 연이어 등장하면서 NLP의 거의 모든 태스크에서 기존 방법을 압도하는 성능을 보였다. 이러한 성능상의 우위와 범용성 덕분에, 2018년 이후 NLP 연구는 사실상 Transformer를 표준 구조로 채택하게 되었다.
NLP 연구용 프레임워크(PyTorch)와 산업용 프레임워크(TensorFlow)의 역할은 어떻게 나눠질까?
PyTorch는 동적 계산 그래프와 직관적인 Pythonic 문법 덕분에 연구자와 학계에서 사실상 표준으로 자리 잡았다. 새로운 아이디어를 빠르게 프로토타이핑하고 실험하는 데 최적화되어 있어, 최신 논문 구현 대부분이 PyTorch로 공개되고 있다. 반면 TensorFlow와 Keras는 산업 현장과 대규모 서비스 배포에서 강점을 가진다. TPU 지원, TensorFlow Serving, TensorFlow Lite와 같은 배포 친화적 기능들이 제공되기 때문에 기업 환경에서 안정적으로 모델을 운영하기에 유리하다. 따라서 두 프레임워크는 연구와 산업이라는 서로 다른 목적에 따라 자연스럽게 역할이 분화되고 있다고 볼 수 있다.
수학적으로 인공지능 모델이란 무엇인가?
수학적으로 인공지능 모델이란 무엇인가?
인공지능 모델은 본질적으로 입력 \(x\)와 출력 \(y\) 사이의 관계를 함수로 근사하는 체계라고 정의할 수 있다.
가장 단순한 수학적 표현은 다음과 같다.
여기서 \(f\)는 입력을 출력으로 변환하는 함수이며, \(\theta\)는 학습 가능한 파라미터(parameter, weight)를 의미한다.
이 파라미터는 함수가 어떻게 동작할지를 결정하는 핵심 요소로, 동일한 입력 \(x\)라도 \(\theta\) 값에 따라 전혀 다른 출력 \(y\)를 생성할 수 있다.
파라미터(Parameters, \(\theta\))
파라미터는 모델 내부의 조정 가능한 값으로, 데이터를 통해 학습된다.
선형 회귀에서의 회귀계수, 신경망에서의 가중치(weight)와 편향(bias)가 대표적인 예이다.
파라미터가 달라지면 모델이 학습하는 함수의 형태 또한 달라진다.
따라서 학습은 곧 데이터를 바탕으로 최적의 파라미터를 탐색하는 과정이라 할 수 있다.
학습(Learning)
학습은 주어진 데이터 집합 \(\{(x_i, y_i)\}\)를 통해 \(f(x; \theta)\)가 실제 \(x\)와 \(y\) 사이의 관계를 최대한 잘 근사하도록 \(\theta\)를 조정하는 과정이다.
이를 위해 손실 함수(Loss Function)를 정의하고, 경사하강법(Gradient Descent)과 같은 최적화 기법을 통해 파라미터를 반복적으로 갱신한다.
여기서 \(L\)은 예측값과 실제값 간의 오차를 측정하는 함수이다.
즉, 학습은 단순히 데이터에 맞추는 것 이상의 과정이며, 일반화 가능한 함수 근사를 목표로 한다.
모델(Model)
모델이란 상황에 따라 두 가지 의미로 사용된다.
- 알고리즘적 정의: 특정 문제를 해결하기 위해 사용되는 함수적 구조 (예: 선형 회귀, 신경망, 결정트리).
- 파라미터 집합: 학습을 통해 얻어진 최적의 파라미터 값 \(\theta^*\) 자체를 가리키기도 한다.
즉, 인공지능 모델은 함수적 구조와 학습된 파라미터의 결합체라 할 수 있다.
수학적으로 볼 때, 인공지능 모델은 데이터를 통해 입력과 출력 사이의 관계를 근사하는 매개변수화된 함수이다.
학습은 이 함수의 파라미터를 최적화하여, 단순한 훈련 데이터의 재현을 넘어 보이지 않은 데이터에 대해서도 의미 있는 예측을 수행할 수 있도록 만드는 과정이다.
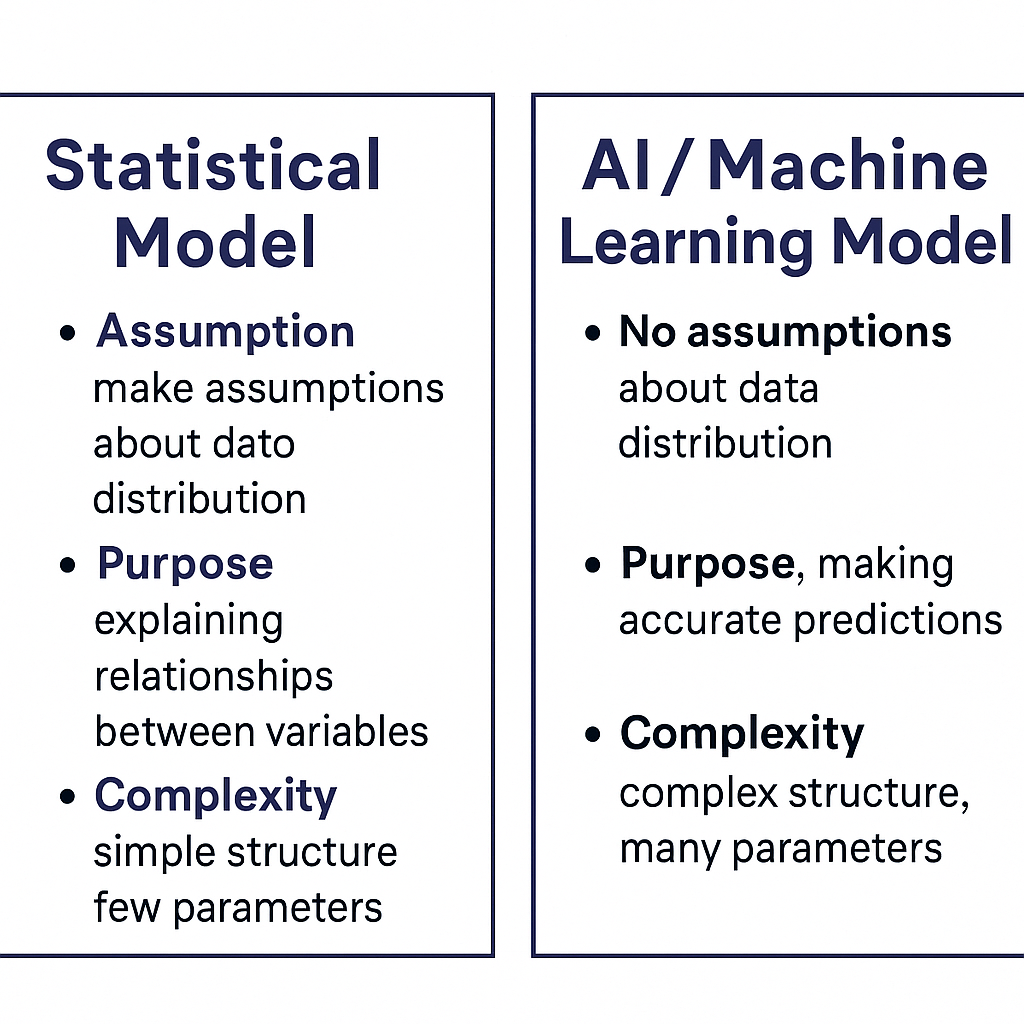
전통적 통계 모델 vs 인공지능 모델
인공지능 모델을 이해하기 위해서는 먼저 전통적 통계 모델과의 차이를 비교하는 것이 필요하다.
두 접근은 모두 데이터를 기반으로 입력과 출력 사이의 관계를 설명하지만, 가정, 목적, 복잡도 측면에서 본질적인 차이를 가진다.
전통적 통계 모델 (Statistical Models)
- 가정(Assumption)
- 데이터가 특정 확률 분포를 따른다고 가정
-
예: 선형 회귀는 \( y = \beta_0 + \beta_1 x + \epsilon \) 형태를 가정하며, \(\epsilon \sim N(0, \sigma^2)\)로 본다.
-
목적(Purpose)
- 변수 간의 관계를 설명(Explanation)하는 데 초점
-
독립 변수와 종속 변수의 영향 해석 가능
-
복잡도(Complexity)
- 단순한 수학적 구조를 사용
- 해석 가능성이 높음(Interpretability)
인공지능 모델 (AI / Machine Learning Models)
- 가정(Assumption)
- 특정 분포에 대한 가정을 두지 않음
-
대신 대규모 데이터와 비선형 함수 근사를 통해 관계를 탐색
-
목적(Purpose)
- 정확한 예측(Prediction)에 초점
-
관계 해석보다는 일반화 성능을 중시
-
복잡도(Complexity)
- 수백만 개 이상의 파라미터를 가진 복잡한 구조 사용 가능
- 해석 가능성은 낮지만, 표현력과 성능은 매우 높음
비교 요약
| 구분 | 전통적 통계 모델 | 인공지능 모델 |
|---|---|---|
| 가정 | 확률 분포 및 수학적 형태를 가정 | 분포 가정 없음, 데이터 기반 함수 근사 |
| 목적 | 변수 간 관계 설명, 해석 가능성 강조 | 높은 예측 성능, 일반화 능력 강조 |
| 복잡도 | 단순한 구조, 적은 파라미터 | 대규모 파라미터, 복잡한 네트워크 구조 가능 |
| 대표 예시 | 선형 회귀, 로지스틱 회귀, ANOVA | 신경망, CNN, RNN, Transformer 등 |
| 해석 가능성 | 높음 (계수 \(\beta\) 해석 가능) | 낮음 (블랙박스 특성) |
전통적 통계 모델은 데이터에 대한 가정을 전제로 한 해석 중심 접근이며,
인공지능 모델은 가정 없이 데이터 기반으로 패턴을 학습하는 예측 중심 접근이라 할 수 있다.
따라서 두 접근은 상호 배타적이라기보다, 문제의 성격과 목적에 따라 상호 보완적으로 활용될 수 있다.
좋은 인공지능과 기존 머신러닝의 한계
좋은 인공지능
좋은 인공지능 모델의 핵심은 일반화(Generalization) 능력에 있다.
모델이 단순히 훈련 데이터에만 잘 맞추는 것은 의미가 없다.
오히려 학습 과정에서 보지 못한 미지의 데이터(unseen data)에 대해서도 올바른 예측을 수행할 수 있어야 한다.
- 우리는 모든 경우의 수에 대한 데이터를 미리 확보할 수 없기 때문에,
결국 좋은 모델이란 새로운 상황에서도 합리적인 판단을 내릴 수 있는 모델을 의미한다.
기존 머신러닝의 한계
기존 머신러닝 기법은 본질적으로 낮은 차원의 데이터를 처리하기 위해 설계된 한계를 지닌다.
- 전통적인 머신러닝 모델(예: 선형 회귀, 로지스틱 회귀, SVM)은
데이터의 차원을 상대적으로 낮게 가정하거나, 커널 기법을 통해 비선형 관계를 다룬다. - 그러나 데이터의 차원이 매우 높아지면(예: 이미지, 텍스트, 음성 데이터)
성능이 급격히 저하되거나 계산 복잡성이 폭발적으로 증가한다.
커널 기법을 사용하면 어느 정도 비선형성을 포착할 수 있지만,
이는 결국 계산 자원의 제약과 확장성 문제로 이어진다.
따라서 전통적 머신러닝은 단순한 데이터셋에서는 효과적이지만,
대규모 비정형 데이터(고차원 이미지, 자연어 텍스트, 음성 신호 등)에서는 충분한 성능을 발휘하지 못한다.
- 좋은 인공지능 모델은 단순한 학습 정확도가 아니라 일반화 능력을 핵심 기준으로 한다.
- 기존 머신러닝은 차원 제약 때문에 한계가 있으며,
딥러닝은 방대한 파라미터와 계층적 구조를 통해 고차원 데이터에서 패턴을 자동으로 추출하고 일반화 능력을 강화한다. - 이는 곧 좋은 인공지능 = 일반화를 잘하는 인공지능이라는 정의로 이어진다.
전통적 머신러닝 vs 딥러닝의 일반화 접근 차이
전통적 머신러닝과 딥러닝은 모두 훈련 데이터에서 보지 못한 새로운 데이터에 대해 잘 작동하는 일반화(Generalization)를 목표로 한다.
그러나 두 접근 방식은 그 방법론과 가정에서 뚜렷한 차이를 보인다.
| 구분 | 전통적 머신러닝 (Statistical ML) | 딥러닝 (Deep Learning) |
|---|---|---|
| 가정 | 데이터가 저차원 공간에 존재하거나, 특징 공간을 명시적으로 정의할 수 있다고 가정 |
데이터가 고차원 공간에 존재하며, 네트워크가 자동으로 특징을 학습 |
| 일반화 원리 | VC 차원, Rademacher 복잡도 등 모델 복잡도 제한을 통해 일반화 달성 |
과적합 위험에도 불구하고 대규모 파라미터 + 정규화 기법으로 일반화 확보 |
| 수학적 표현 | \(\hat{f}(x) = \arg\min_{f \in \mathcal{H}} \frac{1}{n}\sum_{i=1}^n L(f(x_i), y_i) + \lambda \Omega(f)\) 가설 공간 \(H\) 내에서 손실 최소화 + 정규화 항 \(\Omega(f)\) 으로 일반화 보장 |
\(\hat{f}_\theta(x) = f(x; \theta)\), \(\quad \theta^* = \arg\min_\theta \frac{1}{n}\sum_{i=1}^n L(f(x_i; \theta), y_i)\) 파라미터 수가 크지만, Dropout, BatchNorm, Early Stopping 등으로 일반화 확보 |
| 특징 추출 | 수동적 Feature Engineering 필요 (예: SIFT, Bag-of-Words, PCA 등) |
End-to-End 학습을 통해 네트워크가 특징, 표현을 자동으로 학습 |
| 데이터 요구량 | 비교적 적은 데이터에서도 작동 가능 | 일반적으로 대규모 데이터 필요 (\(n \to \infty\)) |
| 적용 한계 | 고차원 데이터(이미지, 음성, 텍스트)에서는 성능 한계 |
고차원, 비정형 데이터에서도 뛰어난 성능 발휘 |
전통적 머신러닝은 일반화 성능을 보장하기 위해 가설 공간의 크기와 모델의 복잡도를 제한하는 방식을 따른다. 이는 주어진 데이터에 과도하게 맞추지 않고, 이론적으로 모델이 새로운 데이터에서도 잘 작동할 수 있음을 보장하려는 접근이다. 따라서 전통적 머신러닝은 확률적 가정, VC 차원, 정규화 항과 같은 통계적 학습 이론을 중심으로 발전해왔다.
반면, 딥러닝은 이러한 이론적 제약 대신 경험적 접근을 따른다. 즉, 수많은 파라미터와 복잡한 네트워크 구조를 활용하면서도, Dropout, Batch Normalization, Early Stopping 등 다양한 정규화 기법과 방대한 데이터 학습을 통해 일반화 성능을 달성한다. 이는 이론적으로 일반화가 보장된 구조라기보다, 실험과 경험을 통해 검증된 성능에 기반을 둔 접근 방식이다.
따라서 대학원 수준에서 인공지능의 일반화를 논의할 때는, 전통적 머신러닝이 의존하는 통계적 학습 이론과 딥러닝이 강조하는 표현 학습(Representation Learning)의 차이를 이해하는 것이 매우 중요하다. 이는 두 패러다임이 단순히 경쟁 관계에 있는 것이 아니라, 서로 다른 철학과 방법론을 통해 인공지능의 발전을 이끌어가고 있음을 보여준다.
표현 학습(Representation Learning)
정의와 동기
표현 학습은 입력 \(x \in \mathcal{X}\)를 정보적으로 유용한 잠재 표현 \(z=\phi(x)\in \mathcal{Z}\)로 변환하는 함수를 학습하는 과정이다.
이때 “유용성”은
(i) 다운스트림 과제에서 간단한 분류기/회귀기 \(g\) 만으로도 높은 성능을 내는가,
(ii) 잡음·변형에 불변(invariance) 혹은 등변(equivariance) 특성을 가지는가,
(iii) 전이 학습 시 표본 효율성을 높이는가 등으로 판단한다.
수학적 관점과 원리
지도 학습 관점
여기서 “좋은 표현”이란, 단순한 가설 공간(예: 선형 분류기)에서도 낮은 위험(risk)을 달성할 수 있는 \(\phi\)를 의미한다.
정보 병목(Information Bottleneck, IB)
표현 \(Z=\phi(X)\)가 목표 \(Y\)에 유용한 정보는 보존하고, 불필요한 입력 정보는 압축하도록 유도한다.
불변성(Invariance)과 등변성(Equivariance)
표현 학습에서는 입력 데이터가 변형되더라도 의미가 같다면, 모델이 이를 잘 처리해야 한다.
이때 불변성과 등변성이라는 두 가지 개념이 자주 쓰인다.
불변성 (Invariance)
- 정의: 입력이 일정한 변환을 받더라도 표현은 변하지 않는 성질.
- 설명: 모델은 데이터의 의미를 유지하면서, 불필요한 변화를 무시한다.
- 예시:
- NLP: “I love NLP”와 “I really love NLP” → 의미가 비슷하므로 임베딩이 크게 달라지지 않아야 한다.
- 이미지: 같은 개를 찍은 사진을 왼쪽으로 조금 이동하거나 밝기를 조절하더라도, 모델이 “개”라는 표현을 동일하게 유지해야 한다.
- 음성: 같은 사람이 “안녕하세요”를 조금 빠르게 말하거나 억양을 살짝 바꿔도, 화자 임베딩은 동일하게 유지되어야 한다.
즉, 불변성은 의미만 보존하고 잡음이나 불필요한 변화를 무시하는 것이다.
등변성 (Equivariance)
- 정의: 입력이 변환되면, 표현도 그 변환에 맞게 일정하게 바뀌는 성질.
- 설명: 모델은 변환 자체를 반영해서 표현 공간에서도 같은 방식으로 변화를 준다.
- 예시:
- 이미지: CNN(합성곱 신경망)은 대표적인 예다.
만약 이미지를 오른쪽으로 이동시키면, 특징 맵(feature map)도 똑같이 오른쪽으로 이동한다. - 음성: 음성을 시간축에서 약간 늦추면, 스펙트로그램 표현도 시간축 방향으로 똑같이 이동해야 한다.
즉, 등변성은 입력의 변화를 표현 공간에서도 그대로 반영하는 것이다.
정리
- 불변성: "입력이 조금 바뀌어도 표현은 그대로 유지된다."
- 등변성: "입력이 바뀌면 표현도 그에 맞게 똑같이 바뀐다."
둘 다 모델이 데이터를 더 잘 이해하고, 실제 환경의 다양한 변화를 처리할 수 있도록 돕는 중요한 개념이다.
| 구분 | 불변성 (Invariance) | 등변성 (Equivariance) |
|---|---|---|
| 의미 | 입력 데이터가 변해도 표현은 변하지 않음 | 입력 데이터가 변하면 표현도 그에 맞게 변함 |
| 역할 | 불필요한 변화(잡음, 위치·밝기 등)를 무시하고 본질적 의미만 유지 | 데이터의 구조적 변화를 표현 공간에도 반영하여 규칙성을 학습 |
| 딥러닝에서 장점 | - 일반화 성능 향상 - 잡음 제거 - 안정적 의미 표현 확보 |
- 데이터 효율성 증가 - 구조적 학습 가능 - 다양한 변환을 일일이 학습하지 않아도 됨 |
| 예시 (NLP) |
“I love NLP”와 “I really love NLP” → 의미가 비슷하면 같은 표현 | 문장의 어순 변화에 따라 구문 트리 표현도 동일한 방식으로 변환 |
| 예시 (이미지) |
개 사진이 왼쪽·오른쪽으로 이동하거나 밝기가 바뀌어도 “개”로 인식 | CNN: 이미지가 이동하면 특징 맵도 똑같이 이동 |
| 예시 (음성) |
같은 사람이 “안녕하세요”를 빠르게/느리게 말해도 같은 화자 표현 | 음성을 시간축에서 이동시키면 스펙트로그램 표현도 동일하게 이동 |
핵심 기법별 직관과 목적함수
오토인코더(AE, DAE, VAE)
- 기본 오토인코더(AE):
- 변분 오토인코더(VAE):
Word2Vec Skip-gram
아키텍처 자체는 표현 학습 기법이라기보다 표현을 만들어내는 도구
심층 신경망 (DNN)
- 설명: 다층 퍼셉트론 구조를 통해 입력을 비선형 변환하며 점차 추상적인 표현을 학습한다.
- 특징: 단순히 분류 정확도를 올리는 것뿐 아니라, 중간 레이어가 학습한 은닉 표현(hidden representation)이 다른 태스크에도 유용하게 전이될 수 있다.
- 예시: 음성 인식에서 원시 스펙트로그램을 입력으로 받아, 은닉층에서 발음 단위(phoneme)를 잘 구분하는 표현을 형성한다.
합성곱 신경망 (CNN)
- 설명: 지역적 수용영역(receptive field)과 파라미터 공유를 통해 이미지와 같은 구조적 데이터를 처리한다.
- 표현 학습 역할: 저층에서는 모서리, 질감 같은 저수준 특징을, 고층에서는 객체·장면과 같은 고수준 표현을 학습한다.
- 예시: 이미지넷 분류 모델의 중간 레이어는 고양이 귀, 자동차 바퀴 같은 시각적 패턴을 자동으로 추출하는 표현을 만들어낸다.
순환 신경망 (RNN, LSTM, GRU)
- 설명: 시퀀스 데이터를 다루는 구조로, 시간축에서 앞선 정보를 은닉 상태에 저장하여 다음 단계로 전달한다.
- 표현 학습 역할: 단어 임베딩을 문맥과 연결해, 문장의 순차적 의미를 표현하는 벡터를 학습한다.
- 예시: 기계 번역에서 문장을 순차적으로 읽어가며, 마지막 은닉 상태를 전체 문장 표현으로 사용한다.
트랜스포머 (Transformer, BERT, GPT 계열)
- 설명: 자기 주의(Self-Attention) 메커니즘을 통해 문맥 전역의 의존성을 학습한다.
- 표현 학습 역할: 단어를 위치와 무관하게 서로 연결짓고, 깊은 층을 통해 의미적·구문적 정보를 포함하는 표현을 만든다.
- 예시: BERT는 마스크 언어 모델(MLM) 학습으로 맥락적 단어 표현을, GPT는 다음 단어 예측을 통해 생성 중심 표현을 학습한다.
표현 학습의 평가 방법
표현 학습을 통해 얻은 잠재 공간이 실제로 얼마나 유용한지를 평가하는 것은 매우 중요하다.
단순히 손실 함수가 줄어드는 것만으로는 좋은 표현을 보장할 수 없기 때문이다.
따라서 연구자들은 여러 가지 방법을 통해 표현의 품질을 검증한다.
선형 탐침 (Linear Probe)
표현 함수 \(\phi(x)\)를 고정한 뒤, 그 위에 단순한 선형 분류기를 학습시켜 성능을 측정한다.
만약 선형 분류기만으로도 좋은 성능이 나온다면, 이는 \(\phi(x)\)가 이미 데이터를 잘 분리할 수 있도록 구조화되어 있다는 의미다.
즉, 복잡한 모델 없이도 구분 가능하다면 표현이 선형적으로 분리 가능한(latent separable) 좋은 구조를 가지고 있다고 본다.
전이 성능 (Transfer Performance)
하나의 과제에서 학습한 표현을 다른 과제에 적용해 보는 방식이다.
예를 들어, 대규모 코퍼스에서 학습한 언어 표현을 감정 분류, 질의응답, 번역 등 다양한 NLP 과제에 적용한다.
전이 학습에서 좋은 성능을 보인다면, 표현이 특정 과제에 국한되지 않고 범용적(general-purpose)임을 의미한다.
프로빙 태스크 (Probing Tasks)
표현이 언어학적·구조적 정보를 얼마나 잘 보존하는지를 평가하기 위한 작은 실험들이다.
예를 들어, 문장의 시제, 주어-동사 일치 여부, 구문 구조, 의미적 속성 등을 복원할 수 있는지를 테스트한다.
이를 통해 표현이 단순히 패턴만 학습한 것이 아니라, 언어의 심층적 속성을 포함하고 있는지를 알 수 있다.
표현 유사도 지표 (Representation Similarity Metrics)
두 표현 공간이 서로 얼마나 유사한지를 정량적으로 비교하는 방법이다.
대표적인 지표로는 CKA (Centered Kernel Alignment)와 SVCCA (Singular Vector Canonical Correlation Analysis)가 있다.
이를 통해 서로 다른 모델이나 레이어가 학습한 표현이 본질적으로 같은 정보를 담고 있는지를 분석할 수 있다.
시각화 (Visualization)
마지막으로, 표현을 저차원 공간으로 투영하여 시각적으로 확인하는 방법이 있다.
주로 t-SNE나 UMAP 같은 차원 축소 기법을 사용해 표현을 2D 또는 3D로 변환한다.
이렇게 하면 데이터가 군집 형태로 잘 구분되는지, 서로 다른 클래스가 섞이지 않고 분리되는지를 직관적으로 확인할 수 있다.
물론 시각화는 정량적 기준은 아니지만, 표현 공간의 구조를 이해하는 보조 도구로 유용하다.
정리
- 선형 탐침: 표현의 선형 분리 가능성 평가
- 전이 성능: 다른 과제에 대한 범용성 평가
- 프로빙 태스크: 언어학적·구조적 정보 포함 여부 검증
- 표현 유사도 지표: 서로 다른 표현 간의 정량적 유사도 측정
- 시각화: 표현 공간의 구조를 직관적으로 이해
이러한 다양한 평가 방법을 함께 사용하면, 표현 학습의 성능을 더 신뢰성 있게 판단할 수 있다.
표현 학습의 한계와 주의점 (사례 중심)
스퓨리어스 상관 (Spurious Correlation)
모델이 진짜 중요한 특징을 학습하기보다는, 우연히 같이 등장하는 배경 정보나 잡음에 의존하는 현상이다. 예를 들어, 고양이 사진에는 잔디밭이 자주 함께 나오기 때문에, 모델이 “잔디 = 고양이”라고 잘못 학습할 수 있다. 이런 경우 모델은 새로운 환경(예: 실내 고양이 사진)에서는 제대로 작동하지 않는다.
-
NLP 사례
긍정적인 영화 리뷰에는 “great”, “excellent” 같은 단어가 자주 등장한다.
그러나 특정 장르(예: 공포 영화)에서는 “dark”라는 단어가 자주 나오는데,
모델이 이를 무조건 부정적인 표현으로 학습하면 잘못된 판단을 내린다.
즉, 문맥을 무시하고 단어 빈도에만 의존하는 문제가 발생한다. -
이미지 사례
늑대 사진은 종종 설원에서 촬영되므로, 모델이 “하얀 배경=늑대”라는 잘못된 규칙을 학습할 수 있다.
새로운 환경(초원에 있는 늑대)에서는 제대로 인식하지 못한다. -
음성 사례
감정 분류 모델이 화자의 감정이 아니라 녹음 장비 특성이나 잡음 패턴에 의존하는 경우가 있다.
특정 마이크로 녹음된 데이터만 학습하면, 실제 다른 장비에서는 잘못된 결과를 낸다.
표현 붕괴 (Collapse)
모든 입력 데이터를 거의 같은 벡터로 표현해버리는 경우다. 겉보기에는 손실이 줄어드는 것처럼 보이지만, 실제로는 의미 있는 구분 능력을 상실한 상태다. 예를 들어, 사람 얼굴을 학습하는데 모든 얼굴을 똑같은 점 하나로 매핑해버린다면, 어떤 얼굴이 들어와도 구분할 수 없게 된다. 이를 막기 위해서는 데이터 증강, 큰 배치 크기 사용, 정규화 기법, 혹은 BYOL과 같은 특수한 학습 전략이 필요하다.
-
NLP 사례
문장 임베딩을 학습할 때, 모든 문장을 거의 동일한 벡터로 매핑하는 현상이 발생할 수 있다.
겉보기에는 손실이 작아도, 실제로는 “I love NLP”와 “I hate NLP”를 구분하지 못한다. -
이미지 사례
대조 학습 기반 이미지 표현 학습에서, 모델이 모든 이미지를 같은 벡터로 인코딩해버리면
분류 능력을 상실한다. 이는 특히 양성·음성 샘플 구분이 부족할 때 자주 발생한다. -
음성 사례
화자 식별 모델이 모든 화자를 비슷한 벡터로 표현해버리면,
발화가 달라도 같은 화자로 인식한다. 이는 학습 과정에서 음성 특징을 제대로 구분하지 못했음을 의미한다.
편향(Bias) 및 프라이버시 문제
표현 속에는 학습 데이터의 사회적 편향이나 민감 정보가 그대로 반영될 수 있다. 예를 들어, 특정 언어 데이터셋에서 성별 고정관념이 강하다면, 표현 학습을 통해 얻은 임베딩 역시 그러한 편향을 내포하게 된다. 또, 개인 데이터로 학습하면 의도치 않게 개인정보가 표현에 남아 프라이버시 문제가 생길 수 있다.
-
NLP 사례
언어 모델이 성별 고정관념을 반영하는 경우가 있다.
예: “The doctor is …” 다음 단어를 예측할 때 “he”를 과도하게 선택하는 현상. -
이미지 사례
얼굴 인식 시스템이 특정 인종에 대해 오탐률이 높게 나타나는 경우.
이는 학습 데이터가 불균형하거나 편향되어 있기 때문이다. -
음성 사례
특정 억양이나 방언에 대해 모델 성능이 급격히 낮아지는 경우.
표준 발음을 중심으로 학습했기 때문에, 다양한 화자 집단을 포괄하지 못하는 문제다.
평가 편향 (Evaluation Bias)
표현 학습을 평가할 때 특정 데이터셋이나 특정 지표에만 의존하면, 실제 일반화 능력을 과대평가할 수 있다. 예를 들어, 한 데이터셋에서 높은 성능을 보였더라도 다른 환경에서는 제대로 작동하지 않을 수 있다. 따라서 표현 학습 모델은 다양한 과제와 데이터셋에서 다면적으로 평가하는 것이 중요하다.
-
NLP 사례
문장 임베딩 모델이 특정 벤치마크(예: GLUE, SuperGLUE)에서는 높은 점수를 받지만,
실제 대화체 데이터나 도메인 특화 텍스트에서는 성능이 급격히 떨어질 수 있다. -
이미지 사례
이미지 분류 모델이 ImageNet에서는 좋은 성능을 내지만,
의료 영상이나 위성 이미지에서는 제대로 작동하지 않는 경우가 많다. -
음성 사례
음성 인식 모델이 스튜디오 녹음 환경에서는 거의 완벽하게 작동하지만,
실제 소음 환경(카페, 거리 등)에서는 오류율이 크게 증가한다.
표현 학습은 강력한 도구이지만, 스퓨리어스 상관, 표현 붕괴, 편향·프라이버시, 평가 편향과 같은 문제들이
각 도메인마다 다르게 나타난다.
따라서 연구자는 단순히 모델 성능 수치만 보는 것이 아니라,
다양한 데이터셋과 상황에서 검증하여 모델이 실제로 일반화 능력을 갖추었는지를 평가해야 한다.
간단 코드 예시 (PyTorch)
import torch, torch.nn as nn, torch.optim as optim
class AE(nn.Module):
def __init__(self, d_in=784, d_z=64):
super().__init__()
self.enc = nn.Sequential(nn.Linear(d_in, 256), nn.ReLU(),
nn.Linear(256, d_z))
self.dec = nn.Sequential(nn.Linear(d_z, 256), nn.ReLU(),
nn.Linear(256, d_in))
def forward(self, x):
z = self.enc(x)
x_hat = self.dec(z)
return x_hat, z
model = AE()
opt = optim.Adam(model.parameters(), lr=1e-3)
crit = nn.MSELoss()
x = torch.rand(128, 784) # dummy batch
x_hat, z = model(x)
loss = crit(x_hat, x)
자연어처리의 어려움
자연어는 인간에게는 직관적으로 이해 가능한 언어 체계이지만, 기계에게는 수많은 어려움을 안겨준다.
대표적인 문제로는 중의성(Ambiguity), 의역(Paraphrase), 그리고 언어의 이산성과 연속성의 차이를 들 수 있다.
중의성 (Ambiguity)
자연어에는 하나의 표현이 여러 가지 의미로 해석될 수 있는 중의성이 존재한다.
이는 문맥 정보가 부족할 때 특히 두드러진다.
- 예시:
- “나는 철수를 안 때린다.”
- 해석 1: 철수를 맞지 않았다.
- 해석 2: 철수라는 사람을 때린 적이 없다.
- 해석 3: 나는 누군가를 때린 적은 있지만, 철수는 때린 적이 없다.
이처럼 동일한 문장이 맥락에 따라 전혀 다른 의미를 가질 수 있다.
사람은 주변 대화, 상황, 상식을 통해 이를 쉽게 해결하지만, 컴퓨터는 이런 맥락적 단서(context)를 충분히 반영하지 못해 해석에 어려움을 겪는다.
- 영어 예시:
- “I was kicking her in the car that went to the park for tea.”
- 여기서 in the car가 “내가 차 안에서 발로 찼다”인지,
“그녀가 타고 있던 차 안에서 내가 발로 찼다”인지,
문맥이 없으면 해석이 모호하다.
- 여기서 in the car가 “내가 차 안에서 발로 찼다”인지,
즉, 중의성은 언어처리에서 가장 대표적인 난제 중 하나이며, 기계학습 기반 NLP 모델의 정확한 의미 파악을 방해한다.
의역 (Paraphrase)
다른 표현이지만 같은 의미를 전달하는 현상을 의역(Paraphrase)이라고 한다.
사람은 이를 쉽게 인식하지만, 기계는 두 문장이 서로 동등한 의미를 담고 있는지를 판단하기 어렵다.
예시
- "여자가 공원에서 앉아 있다."
- "여성이 공원 벤치에 앉아 있다."
- "한 여자가 공원에서 쉬고 있다."
세 문장은 모두 같은 장면을 묘사하지만, 표현 방식은 다르다.
사람은 이를 자연스럽게 같은 의미로 받아들이지만, 컴퓨터는 단어가 다르면 별개의 문장으로 인식하기 쉽다.
따라서 의역을 처리하는 능력은 문장 유사도 판단, 질문-응답, 검색 시스템 등에서 핵심적 과제이다.
언어의 이산성과 연속성
자연어의 또 다른 본질적 특징은 이산적(Discrete)인 기호라는 점이다.
단어는 사전에 기록된 개별 기호이며, 기계는 이를 0과 1의 벡터(예: One-hot 인코딩)로 표현한다.
하지만 이렇게 표현된 단어 벡터는 서로 유사성을 반영하지 못한다.
문제점
- “사랑”과 “좋아하다”는 의미적으로 가깝지만, One-hot 벡터 상에서는 전혀 다른 차원으로 표현된다.
- 단어 사전이 커질수록 벡터는 매우 희소(sparse)해지고, 계산 효율성이 떨어진다.
- “파랑”과 “핑크” 중에서 “빨강”과 가까운 단어를 찾으라는 질문을 기계가 이해하기 어렵다.
이를 해결하기 위해 단어를 연속적인 밀집 벡터(dense embedding)로 표현하는 기법이 등장했다.
Word2Vec, GloVe, BERT와 같은 임베딩 방법은 단어 간의 의미적 유사성을 연속 공간에서 잘 포착할 수 있도록 도와준다.
- 중의성: 같은 문장이 여러 의미를 가질 수 있어 문맥이 중요하다.
- 의역: 다른 문장이 같은 의미를 표현할 수 있어 문장 간 의미 유사도를 파악해야 한다.
- 이산성 vs 연속성: 단어는 본래 이산적 기호이지만, 효과적인 표현 학습을 위해 연속 벡터 공간에서 다뤄야 한다.
이 세 가지 문제는 모두 자연어처리가 사람 수준의 이해에 도달하기 위해 반드시 극복해야 할 과제들이다.
인공지능(딥러닝)을 이용한 문제 해결 절차
딥러닝을 활용하여 문제를 해결하기 위해서는 단순히 모델을 학습시키는 것을 넘어,
문제를 정의하고 데이터를 다루며, 결과를 평가·배포하는 일련의 과정이 필요하다.
이 절차는 실제 연구나 산업 현장에서 매우 중요한 역할을 한다.
문제 정의
가장 먼저 해결하고자 하는 문제를 명확히 정의해야 한다.
이 단계에서는 복잡한 문제를 작은 단위로 분해하여 단순화(simplify)하는 것이 핵심이다.
또한 입력(\(x\))과 출력(\(y\))을 어떻게 정의할지에 따라 문제의 성격이 크게 달라진다.
예를 들어, 고양이 사진 분류 문제라면 입력은 이미지, 출력은 “고양이/고양이 아님”이라는 레이블이 된다.
데이터 수집
문제 정의가 이루어지면 이에 맞는 데이터를 수집해야 한다.
데이터의 양과 질은 딥러닝 성능에 직결되므로, 이 단계는 모델 선택 못지않게 중요하다.
필요에 따라 추가적인 레이블링 작업을 수행하기도 한다.
예: 음성 인식 모델을 학습시키려면, 다양한 화자와 환경에서 녹음된 음성과 정확한 텍스트 전사가 필요하다.
데이터 전처리 및 분석
수집된 원시 데이터는 그대로 사용하기 어렵기 때문에, 전처리 과정을 거쳐야 한다.
- 형태를 가공: 예를 들어, 이미지는 크기 조정과 정규화를 거친다.
- EDA(탐색적 데이터 분석): 데이터의 분포, 이상치(outlier), 불균형 여부 등을 분석한다.
이 단계에서 데이터 품질을 확인하지 않으면, 이후 알고리즘 성능이 크게 저하될 수 있다.
알고리즘 적용
정제된 데이터를 바탕으로 적절한 알고리즘을 적용한다.
딥러닝에서는 신경망 아키텍처를 설계하고, 가설을 세운 뒤 이를 검증하는 방식으로 진행된다.
예: 이미지 인식에는 CNN, 시계열 데이터에는 RNN이나 Transformer 구조를 적용할 수 있다.
평가
모델이 잘 동작하는지를 확인하기 위해 평가 단계가 필요하다.
- 실험 설계: 학습/검증/테스트 데이터셋을 어떻게 나눌지 결정한다.
- 평가지표 설정: 분류 문제라면 정확도, 정밀도, 재현율, F1 점수 등이 대표적이다.
이 단계는 모델의 성능을 객관적으로 검증하는 과정으로, 실제 현장에서 가장 많은 논의가 이루어지는 부분이다.
배포
모델이 충분히 검증되면 실제 환경에 배포한다.
RESTful API 등을 통해 서비스를 제공하거나, 내장 시스템에 탑재하는 방식이 일반적이다.
배포 이후에도 상황에 따라 지속적인 모니터링과 유지·보수가 필요하다.
데이터 분포가 변하거나 새로운 환경이 등장하면, 모델을 다시 학습시키거나 보정해야 한다.
정리
- 문제 정의 → 데이터 수집 → 데이터 전처리 및 분석 → 알고리즘 적용 → 평가 → 배포
- 이 과정은 단순히 기술적 단계의 나열이 아니라, 현실 문제를 AI로 해결하기 위한 연구·산업적 워크플로우이다.
- 각 단계가 유기적으로 연결되어야 최종적으로 신뢰할 수 있는 AI 시스템이 완성된다.
인공지능 문제 해결: 연구 vs 산업 적용 비교
| 단계 | 연구 환경 (Research) | 산업 적용 (Industry) |
|---|---|---|
| 문제 정의 | 새로운 문제를 탐구하고 이론적 가설을 세움 | 실제 비즈니스/서비스 문제를 해결하기 위해 구체적 요구사항 정의 |
| 데이터 수집 |
공개 데이터셋, 합성 데이터 활용이 많음 | 사내 데이터, 사용자 로그, 센서 데이터 등 실사용 데이터를 확보 |
| 데이터 전처리/분석 |
실험 편의를 위한 정제, 소규모 데이터에 집중 | 대규모 데이터 처리 파이프라인 구축, 데이터 품질·보안·규제 고려 |
| 알고리즘 적용 |
최신 모델을 실험하고 성능 비교, 새로운 아키텍처 제안 | 검증된 알고리즘 적용, 성능뿐 아니라 효율성·안정성 고려 |
| 평가 | 논문 지표(Accuracy, F1, BLEU 등) 중심 | SLA (Service Level Agreement) 충족, 사용자 경험 (UX) 기반 지표 |
| 배포 | 배포는 보통 고려하지 않음, 시뮬레이션 단계에서 끝남 | REST API, 클라우드 서비스, 임베디드 시스템 등으로 실제 운영 환경에 배포 |
| 유지/보수 | 필요시 후속 연구로 이어짐 | 지속적인 모니터링, 데이터 드리프트 대응, 모델 재학습 주기 관리 |