Data Visualization Basics
- 강의자료 다운로드: pdf
학습목표
- Matplotlib과 Seaborn 기본 문법 학습
- 데이터의 분포(Distribution), 관계(Relationship), 시계열(Time Series) 시각화 이해
- 실제 데이터를 다양한 차트로 표현하며 데이터 패턴 파악 능력 배양
데이터 시각화 개요
데이터 시각화는 수치를 눈으로 쉽게 이해할 수 있도록 그래프로 표현하는 과정이다.
데이터 시각화는 단순히 숫자와 표를 그래프로 바꾸는 작업을 넘어, 데이터가 전달하는 본질적 의미를 쉽게 이해할 수 있도록 돕는 핵심 도구이다. 현대 사회에서 수집되는 데이터는 그 양이 방대하고 구조가 복잡하다. 이 데이터를 그대로 제시하면 사람들은 패턴과 경향을 파악하기 어렵다. 하지만 시각화 과정을 거치면 추상적 수치가 직관적인 형태로 변환되어, 누구나 한눈에 중요한 정보를 이해할 수 있다.
데이터 분석의 목표는 단순한 기술 통계에 그치지 않고, 의사결정을 지원하는 통찰(insight) 을 제공하는 것이다. 예를 들어 경영자는 매출 그래프의 추세선을 통해 판매 전략을 조정할 수 있고, 의사는 환자의 검사 결과 차트를 통해 치료 방향을 세울 수 있다. 이처럼 시각화는 분석 결과와 실제 의사결정 사이의 다리 역할을 한다.
또한 시각화는 데이터 품질을 확인하는 데에도 매우 유용하다. 이상치(outlier)가 존재하거나 결측치가 많은 데이터는 표만 보아서는 쉽게 눈치채기 어렵다. 그러나 분포 그래프나 박스플롯을 그려보면 비정상적으로 튀는 값이 곧바로 드러난다. 따라서 시각화는 데이터 정제 과정에서도 중요한 단계로 활용된다.
데이터 과학자뿐 아니라 일반 사용자에게도 시각화는 설득과 소통의 도구가 된다. 분석 결과를 보고서나 프레젠테이션으로 전달할 때, 복잡한 수식을 나열하는 대신 간단한 그래프 한 장이 더 큰 이해를 이끌어낼 수 있다. 특히 다양한 이해관계자들이 함께 의사결정을 내려야 하는 상황에서는 시각화의 역할이 더욱 두드러진다. - 단순 수치 요약 → 추세나 패턴을 놓치기 쉽다 - 시각화 → 데이터의 구조, 분포, 이상치, 경향을 직관적으로 파악 가능
대표 라이브러리
- Matplotlib: Python의 기본 시각화 라이브러리, 낮은 수준 제어 가능
- Seaborn: Matplotlib 기반, 고수준 API 제공, 통계적 시각화에 강점
Matplotlib Basics
Matplotlib은 파이썬에서 가장 널리 사용되는 시각화 라이브러리로, 데이터 과학과 인공지능 연구, 그리고 다양한 산업 응용 분야에서 기본 도구로 자리잡고 있다. 이 라이브러리는 2000년대 초반 John D. Hunter에 의해 개발되었으며, 당시 과학계 연구자들이 MATLAB의 시각화 기능을 파이썬 환경에서도 활용하고자 했던 요구에서 출발하였다. 따라서 Matplotlib은 MATLAB과 유사한 문법을 가지면서도 파이썬 생태계와 자연스럽게 통합되도록 설계되었다. 특히 출판 품질의 그래프를 생성할 수 있도록 의도된 점은 연구자와 엔지니어들에게 큰 매력으로 작용했다.
Matplotlib의 가장 큰 특징은 두 가지 사용 방식에 있다. 첫째, pyplot 모듈을 이용한 상태 기반 인터페이스는 간단한 코드로 빠르게 그래프를 그릴 수 있도록 한다. 이는 초보자가 쉽게 접근할 수 있다는 장점이 있지만, 복잡한 그래프에서는 코드 가독성이 떨어질 수 있다. 둘째, 객체 지향 방식(Object-Oriented API) 을 사용하면 Figure와 Axes 객체를 명시적으로 다루어 세밀한 제어가 가능하다. 이 방식은 코드가 길어질 수 있으나, 복잡한 그래프나 대규모 프로젝트에서는 훨씬 안정적이고 유지보수에도 유리하다.
Matplotlib은 다양한 출력 백엔드를 지원한다는 점에서도 강력하다. 단순히 화면에 그래프를 띄우는 것뿐 아니라, PNG, PDF, SVG, EPS와 같은 다양한 포맷으로 저장할 수 있어 논문이나 보고서에 적합한 고품질 이미지를 생성할 수 있다. 또한 축, 눈금, 서체, 색상, 선 두께, 마커 형태 등 거의 모든 요소를 세밀하게 제어할 수 있기 때문에 연구자들이 원하는 형태의 커스터마이징이 가능하다. 이런 이유로 Matplotlib은 단순 시각화를 넘어 출판물 제작에도 널리 활용된다.
사용자 생태계도 매우 풍부하다. Matplotlib은 NumPy, pandas, SciPy 등 파이썬 과학 연산 라이브러리와 긴밀히 연결되어 있으며, pandas의 DataFrame.plot( ) 역시 내부적으로 Matplotlib을 기반으로 한다. 더 나아가 Seaborn과 같은 고수준 시각화 도구는 Matplotlib을 확장하여 통계적 시각화를 더 쉽게 제공한다. 또한 지도 기반 시각화를 위한 Cartopy, 금융 데이터를 다루는 mplfinance 등 다양한 서드파티 라이브러리들도 Matplotlib 위에 구축되어 있다. 이처럼 넓은 사용자 생태계는 학습 자료와 예제가 풍부하게 제공되도록 하며, 신입 개발자나 학생들이 쉽게 접근할 수 있게 한다.
Matplotlib이 주로 활용되는 분야는 매우 다양하다. 과학 실험 데이터의 분석, 공학적 시뮬레이션 결과 시각화, 경영·재무 지표 보고서 작성, 교육용 시각화 예제, 그리고 웹 애플리케이션이나 대시보드 초기 설계에 이르기까지 다양한 맥락에서 사용된다. 특히 연구자들에게는 "출판 품질(publication quality)"의 그림을 만들어낼 수 있는 능력이 중요한데, Matplotlib은 이러한 요구를 충족시키는 도구로 오랫동안 사랑받아왔다.
물론 장점만 있는 것은 아니다. Matplotlib은 그만큼 세밀한 제어가 가능한 대신, 학습 곡선이 가파르다는 단점이 있다. 동일한 그래프를 그리더라도 코드가 다소 장황해질 수 있고, pyplot의 상태 기반 모델은 초보자들에게 혼란을 줄 수 있다. 또한 기본 스타일은 현대적인 미학 측면에서 부족하다고 평가되기도 한다. 다행히 plt.style.use()나 rcParams를 통해 스타일을 일괄 지정할 수 있고, Seaborn과 같은 라이브러리로 보완할 수 있다. 하지만 여전히 복잡한 레이아웃이나 다중 범례를 처리할 때는 코드가 길어지고 관리가 어려워질 수 있다.
그럼에도 불구하고 Matplotlib은 데이터 시각화 분야에서 사실상의 표준처럼 자리잡고 있다. 그 이유는 단순하다. 세밀한 제어를 통해 원하는 그림을 거의 무엇이든 만들어낼 수 있기 때문이다. 또한 오랜 시간 동안 사용자 커뮤니티가 발전해왔고, 문서와 예제가 풍부하며, 하위 호환성을 꾸준히 유지해왔다는 점도 안정성을 보장한다. 실제 프로젝트에서 빠른 탐색적 분석(EDA)에는 Seaborn을, 최종 보고서용 정밀한 그래프 편집에는 Matplotlib을 활용하는 방식이 일반적이다.
결론적으로, Matplotlib은 단순히 하나의 시각화 도구가 아니라, 파이썬 데이터 과학 생태계를 떠받치는 중요한 인프라라 할 수 있다. 학생과 연구자, 실무자 모두에게 있어 Matplotlib을 배우는 것은 데이터 시각화의 기초를 다지는 필수 과정이다. 비록 초반에는 문법이 다소 어렵게 느껴질 수 있지만, 객체 지향 방식의 API를 이해하고 나면 복잡한 그래프도 체계적으로 다룰 수 있다. 그리고 이 경험은 이후 Seaborn, Plotly, Bokeh 등 다른 시각화 라이브러리를 학습하는 데에도 튼튼한 기반이 된다.
설치
pip install matplotlib
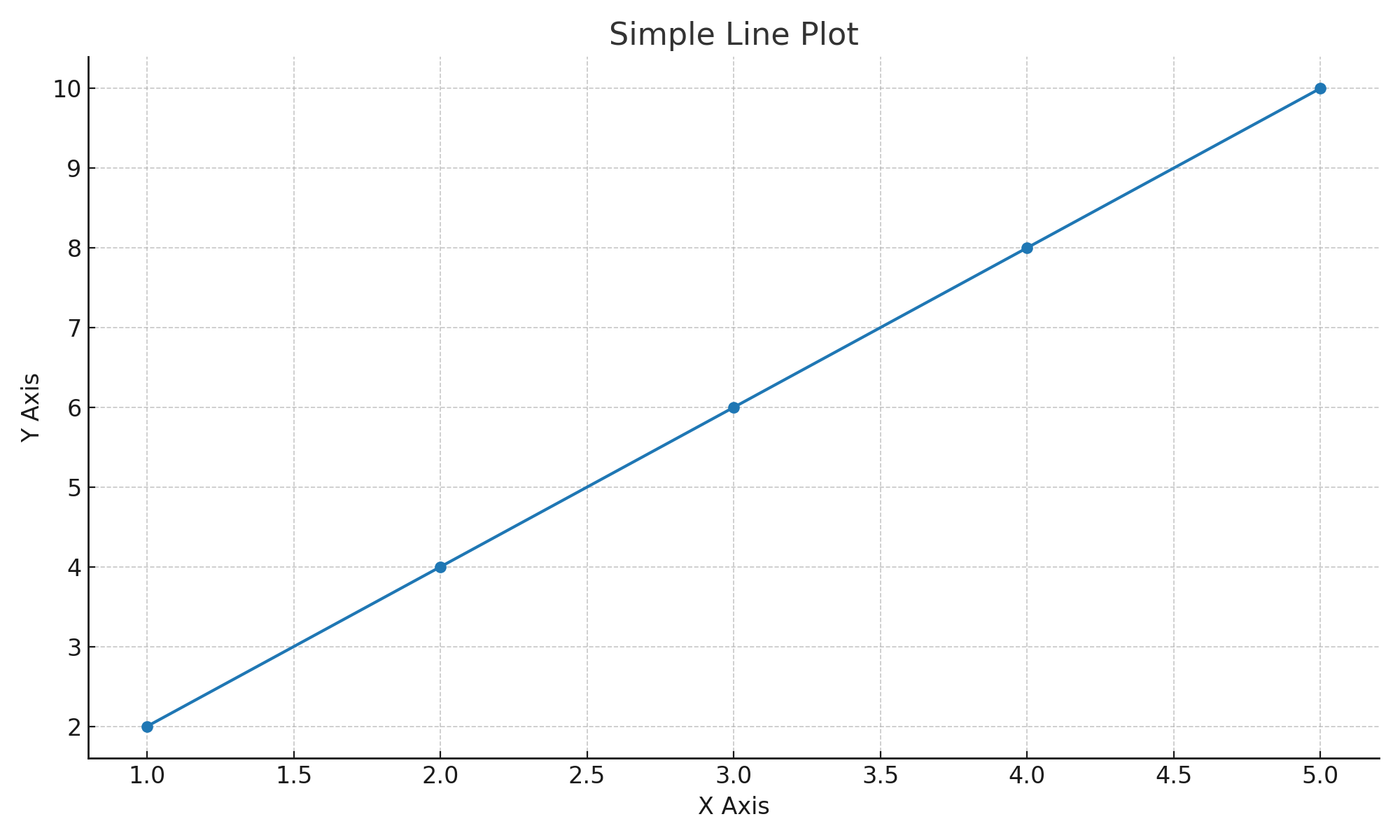
무작정 시작하기 예제 1
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
plt.plot(x, y, marker="o") # 선 그래프
plt.title("Simple Line Plot")
plt.xlabel("X Axis")
plt.ylabel("Y Axis")
plt.show()
실행 결과 선형 관계를 가진 직선 그래프가 표시된다.
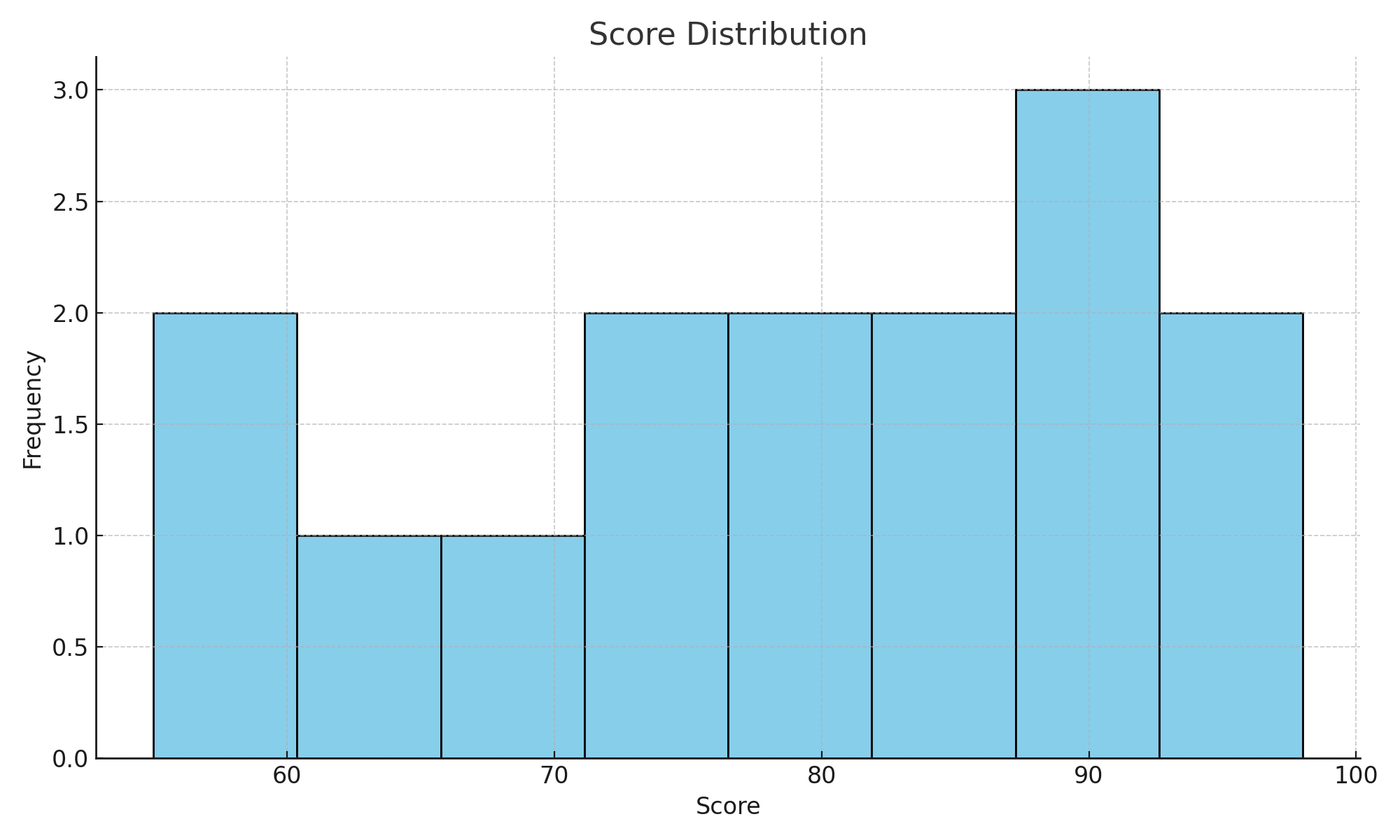
무작정 시작하기 또 다른 예제 2
시나리오: 학생들의 시험 점수를 히스토그램으로 시각화하여 점수 분포를 파악하라.
import matplotlib.pyplot as plt
scores = [55, 60, 65, 70, 72, 75, 78, 80, 82, 85, 88, 90, 92, 95, 98]
plt.hist(scores, bins=8, color="skyblue", edgecolor="black")
plt.title("Score Distribution")
plt.xlabel("Score")
plt.ylabel("Frequency")
plt.show()
실행 결과 설명 - 점수가 70~90 구간에 몰려 있음
학생 점수 분포 확인하기 편리한 시각화
- 분포의 모양을 통해 대부분 학생들이 중상위권에 분포한다는 결론을 얻을 수 있음
 \
\
첫 번째 예제: 최소 코드로 시각화(그려보기)
Matplotlib의 가장 단순한 흐름은 다음과 같다. plt.subplots()로 Figure와 Axes 를 만들고, Axes.plot()으로 데이터를 그린 다음, plt.show()로 화면에 표시한다. 이 과정에서 Figure는 전체 캔버스, Axes는 실제 데이터가 표현되는 영역임을 직관적으로 이해해야 한다.
'''간단한 2차 함수 곡선 그래프'''
import matplotlib.pyplot as plt
import numpy as np
# 데이터 준비
x = np.linspace(0, 2, 100)
y = x**2
# Figure와 Axes 생성
plt.figure()
plt.plot(x, y)
plt.title("Simple Line Plot: y = x^2")
plt.xlabel("x")
plt.ylabel("y")
# 화면 출력
plt.show()
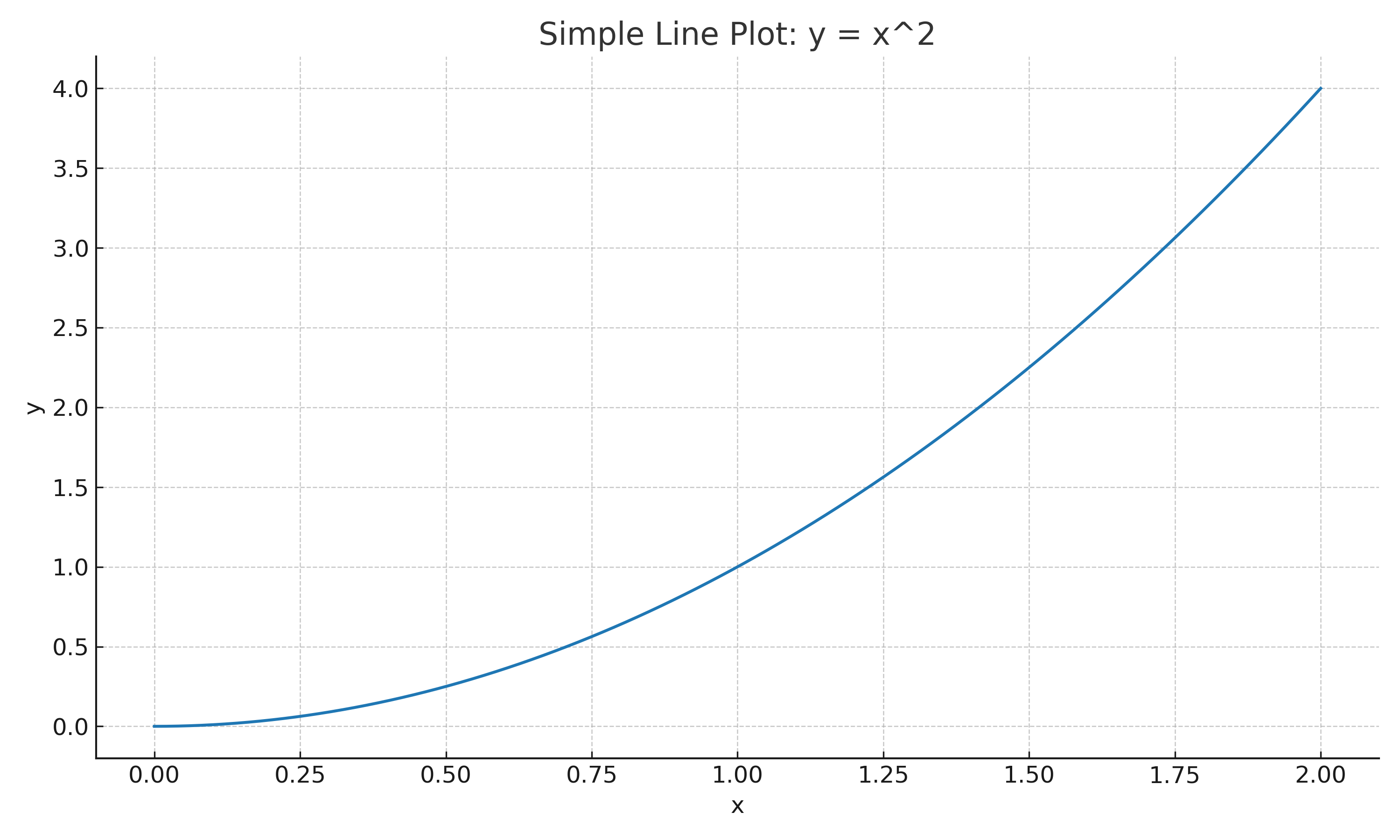
간단한 2차 함수 곡선 그래프(\(y = x^2\)) 결과
최소 예제로 시작하면, "무엇을 어디에 그리는가?"라는 질문에 대해 Figure(전체) – Axes(영역) – Artist(시각 요소) 라는 구조적 관점이 생긴다.
Figure의 구성 요소(Parts of a Figure)
Matplotlib의 그림은 계층 구조를 이룬다. 맨 위에는 Figure가 있고, 그 안에 하나 이상의 Axes가 들어간다. 각 Axes는 \(x\), \(y\)축(Axis 객체), 눈금(ticks), 레이블(labels)을 포함한다.
차트의 선(Line2D), 막대, 텍스트, 범례(legend), 컬러바(colorbar) 등 시각적 요소는 모두 Artist 로 취급된다. 이 계층을 이해하면 단순 호출을 넘어 "어떤 객체를 수정하면 원하는 결과가 나오는가?를 명확히 파악할 수 있다.
'''Figure–Axes–Axis 구조 다이어그램'''
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
import numpy as np
fig, ax = plt.subplots(figsize=(6, 4))
ax.set_xlim(0, 10)
ax.set_ylim(0, 7)
ax.axis("off")
# Figure 영역
fig_box = Rectangle((0.5, 0.5), 9, 6, fill=False, linewidth=2)
ax.add_patch(fig_box)
ax.text(0.6, 6.7, "Figure", fontsize=12, va="bottom")
# Axes 영역
axes_box = Rectangle((1.3, 1.3), 7.4, 4.6, fill=False, linewidth=2)
ax.add_patch(axes_box)
ax.text(1.4, 5.9, "Axes", fontsize=12, va="bottom")
# 축 레이블 표시
ax.text(8.5, 1.1, "x-axis (Axis)", fontsize=10)
ax.text(1.0, 5.0, "y-axis (Axis)", fontsize=10, rotation=90)
# 눈금 흉내
for t in np.linspace(1.5, 8.3, 6):
ax.plot([t, t], [1.3, 1.4])
for t in np.linspace(1.7, 5.7, 5):
ax.plot([1.3, 1.4], [t, t])
# Axes 내부 데이터 예시
xs = np.linspace(1.5, 8.5, 100)
ys = 3 + 1.2*np.sin((xs-1.5)/7.0 * 2*np.pi)
ax.plot(xs, ys)
plt.show()
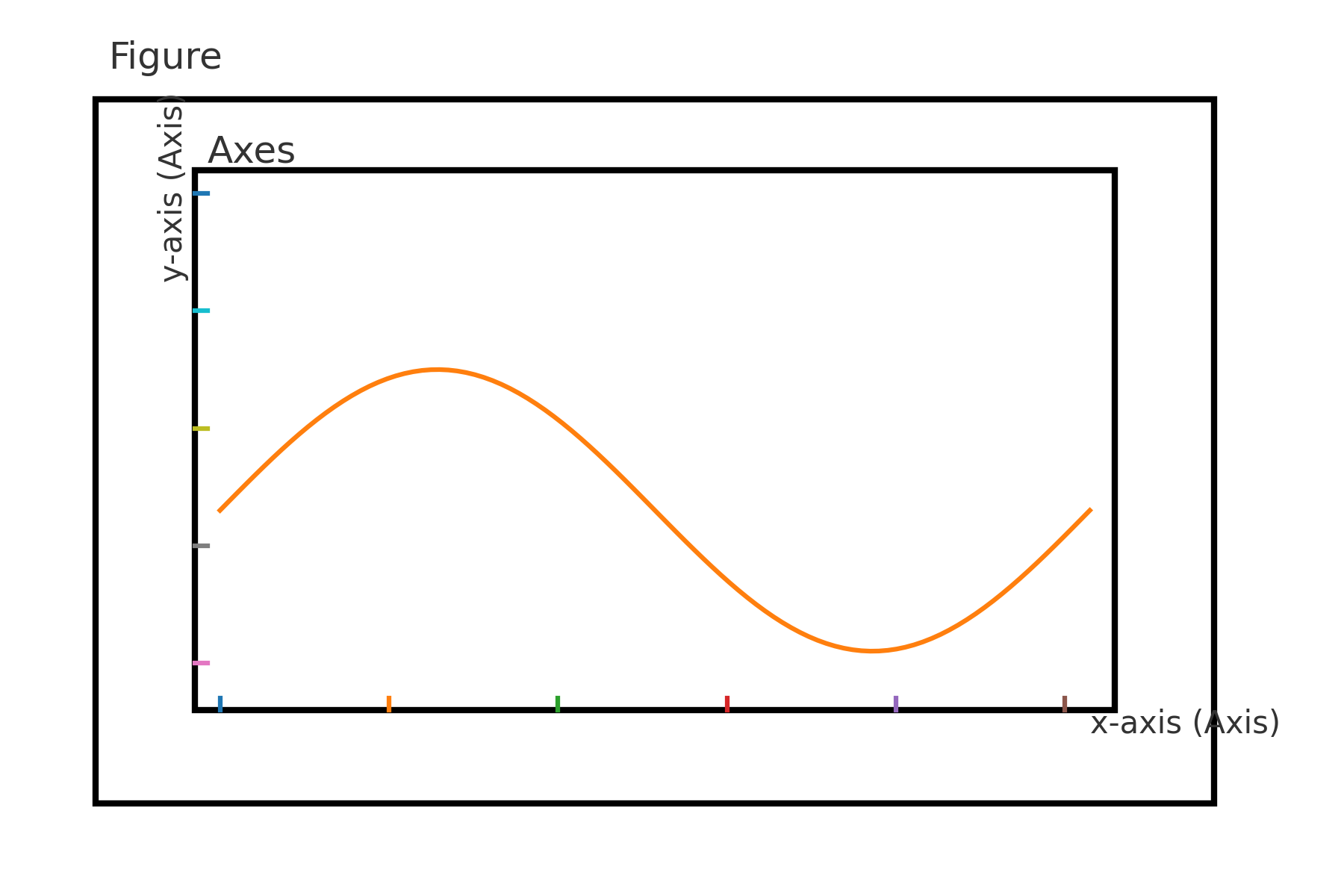
Figure–Axes–Axis의 관계를 간단 도식으로 표현
Matplotlib 그림의 핵심 구성 요소를 정리하면 다음과 같다.
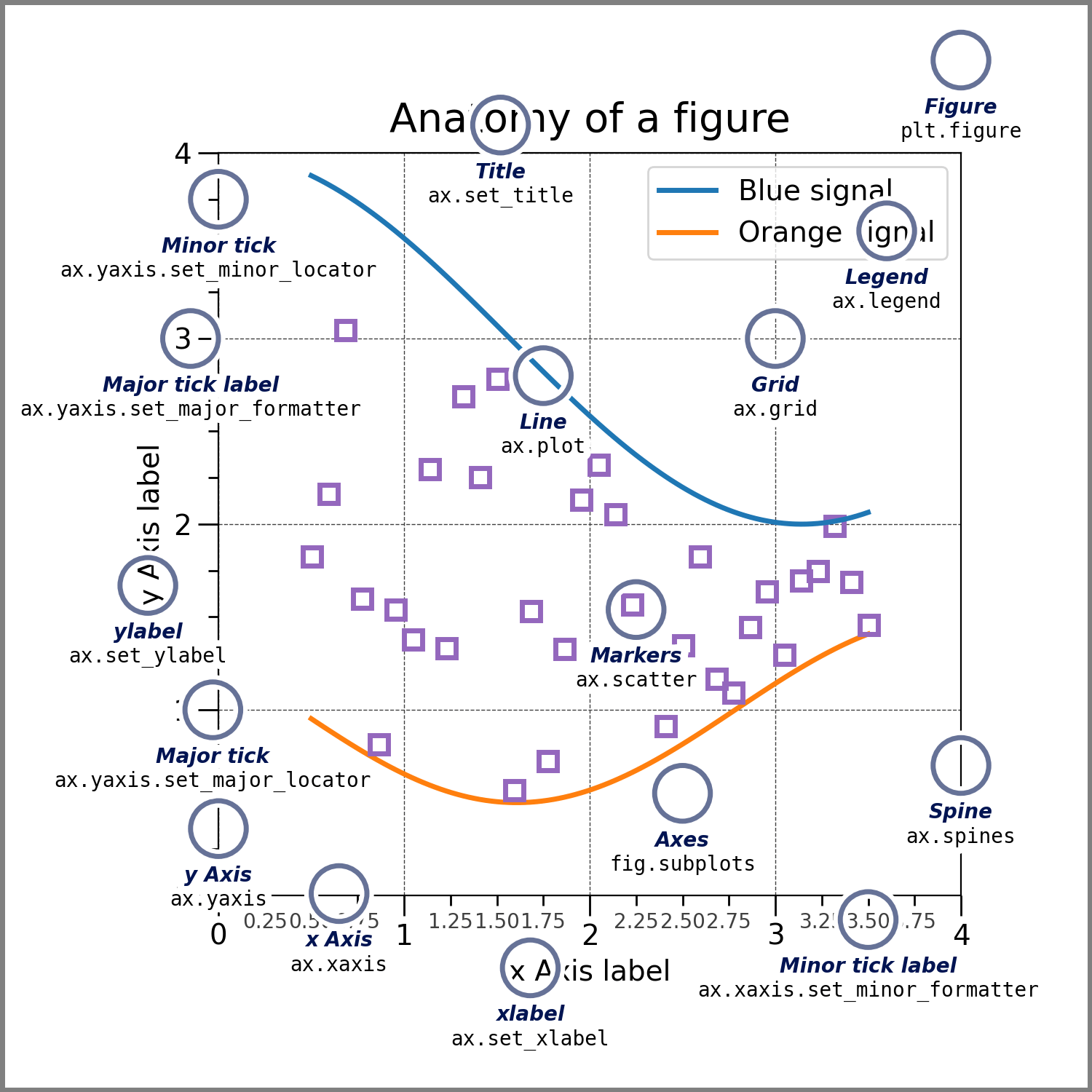
Figure
- Figure는 전체 그림을 의미한다.
- Figure는 여러 Axes와 특수한 Artist(제목, 범례, 컬러바 등)를 포함한다.
- 새로운 Figure는 plt.figure(), plt.subplots(), plt.subplots(2,2) 같은 함수로 생성할 수 있다.
- subplots()는 Figure와 동시에 Axes를 함께 만들어주는 편리한 함수다.
fig = plt.figure() # an empty figure with no Axes
fig, ax = plt.subplots() # a figure with a single Axes
fig, axs = plt.subplots(2, 2) # a figure with a 2x2 grid of Axes
# a figure with one Axes on the left, and two on the right:
fig, axs = plt.subplot_mosaic([['left', 'right_top'],
['left', 'right_bottom']])
subplots()와 subplot_mosaic은 Figure 안에 Axes 객체를 추가로 생성해주는 편의 함수이다. 하지만 원한다면 나중에 직접 Axes를 수동으로 추가할 수도 있다.
- subplots: https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.subplots.html#matplotlib.pyplot.subplots
- subplot_mosaic: https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.subplot_mosaic.html#matplotlib.pyplot.subplot_mosaic
Axes
- Axes는 데이터를 실제로 그리는 영역이다.
- 하나의 Figure 안에는 보통 두 개의 Axis(\(x\)축, \(y\)축)가 들어있고, 3D의 경우 세 개가 들어갈 수 있다.
- 각 Axes는 눈금(
tick)과 레이블(label)을 가진다. - 또한
set_title(),set_xlabel(),set_ylabel()등을 통해 제목과 축 이름을 설정할 수 있다. - 데이터 추가, 스케일 설정, 축 범위 지정 등 대부분의 플롯 설정은 Axes 객체 메서드를 통해 이루어진다.
Axis
- Axis는 \(x\)축과 \(y\)축 각각을 담당하는 객체다.
- 축의 스케일, 눈금, 눈금 레이블을 관리한다.
- 눈금 위치는 Locator 객체가 결정하고, 눈금 텍스트는 Formatter가 지정한다.
- 따라서 Axis는 데이터 범위와 레이블링을 세밀하게 제어할 수 있게 해준다.
Artist
- Artist는 Figure에서 눈에 보이는 모든 요소를 말한다.
- Figure, Axes, Axis뿐만 아니라, Text, Line2D, Patch(사각형·원 등), 컬렉션(collections), 범례, 제목 등이 모두 Artist이다.
- 그림이 렌더링될 때 모든 Artist는 canvas 위에 그려진다.
- 대부분의 Artist는 특정 Axes에 연결되며, 여러 Axes에 동시에 공유되거나 자유롭게 옮겨 다니지 않는다.
정리하면, Matplotlib의 구조는 Figure(전체 캔버스) 안에 Axes(좌표 영역)가 있고,
Axes에는 Axis(\(x\)축, \(y\)축) 있으며, 이 위에 수많은 Artist(선, 글자, 범례 등) 이 그려지는 방식이다.
Figure → Axes → Axis/Artist 라는 계층 구조를 이해하는 것이 Matplotlib을 제대로 활용하는 핵심이다.
Matplotlib 입력 데이터 구조
Matplotlib의 플로팅 함수들은 보통 numpy.array 또는 numpy.ma.masked_array를 입력으로 받는다.
혹은 numpy.asarray를 통해 배열로 변환될 수 있는 객체들도 가능하다.
그러나 pandas의 데이터 객체나 numpy.matrix와 같은 배열 유사 객체(array-like)는 의도대로 동작하지 않을 수 있다.
따라서 일반적으로는 이들을 먼저 numpy.array로 변환한 뒤 사용하는 것이 관례다.
예를 들어, numpy.matrix를 변환하려면 다음과 같이 한다
import numpy as np
b = np.matrix([[1, 2], [3, 4]])
b_asarray = np.asarray(b)
print(b_asarray)
실행 결과
[[1 2]
[3 4]]
대부분의 플로팅 메서드는 문자열로 인덱싱할 수 있는 객체도 해석할 수 있다.
예를 들어 딕셔너리(dict), 구조화된 NumPy 배열(structured array), pandas.DataFrame 등이 가능하다.
이 경우 Matplotlib은 data라는 키워드 인자를 통해 데이터셋을 전달받고, 플롯 함수에는 x축과 y축에 해당하는 열 이름을 문자열로 지정할 수 있다.
import numpy as np
import matplotlib.pyplot as plt
# 난수 생성기 시드 고정 (재현 가능성을 위해 항상 동일한 난수 생성)
np.random.seed(19680801)
# 데이터 딕셔너리 생성
data = {
'a': np.arange(50), # 0부터 49까지 정수 (x축 데이터)
'c': np.random.randint(0, 50, 50), # 0~49 사이 난수 50개 (색상 값으로 활용)
'd': np.random.randn(50) # 표준정규분포 난수 50개 (크기 값으로 활용)
}
# y축 데이터 'b' = x축 데이터 'a' + 잡음(정규분포 * 10)
data['b'] = data['a'] + 10 * np.random.randn(50)
# 'd' 값을 양수로 변환 후 100배 확대 (산점도의 점 크기로 사용)
data['d'] = np.abs(data['d']) * 100
# Figure(전체 캔버스), Axes(데이터 영역) 생성
# figsize: 그래프 크기, layout='constrained': 자동으로 여백 최적화
fig, ax = plt.subplots(figsize=(5, 2.7), layout='constrained')
# 산점도(scatter plot) 그리기
# 'a' → x축, 'b' → y축, 'c' → 점 색상, 'd' → 점 크기
ax.scatter('a', 'b', c='c', s='d', data=data)
# x축, y축 라벨 설정
ax.set_xlabel('entry a')
ax.set_ylabel('entry b')
# 그래프 출력
plt.show()
실행 결과
위 코드는 50개의 점을 가진 산점도를 출력한다.
- a 값은 x축(entry a)에,
- b 값은 y축(entry b)에 매핑된다.
- c 값은 점의 색상(color)에,
- d 값은 점의 크기(size)에 사용된다.
- 각 점은 서로 다른 크기와 색을 가지며, 데이터프레임이나 딕셔너리 형태의 데이터셋을 직접 참조하여 시각화할 수 있음을 보여준다.
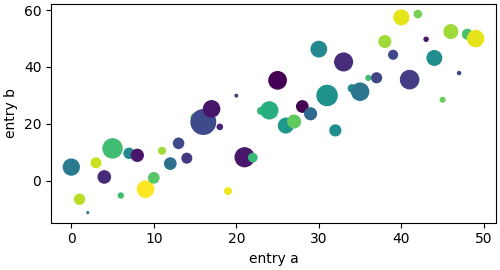
Matplotlib 코딩 스타일
Matplotlib은 크게 두 가지 방식으로 사용할 수 있다. 첫째는 명시적 인터페이스(Object-Oriented, OO 스타일) 방식이다. 이 방식에서는 Figure와 Axes를 직접 생성하고, 각 객체의 메서드를 호출하여 그래프를 제어한다. 예를 들어 fig, ax = plt.subplots()로 Figure와 Axes를 만든 뒤, ax.plot()이나 ax.set_title() 같은 메서드를 통해 구체적인 설정을 수행한다. 이러한 방식은 코드의 구조가 명확하며, 복잡한 그래프나 다중 축 레이아웃을 다루는 데 유리하다.
둘째는 암묵적 인터페이스(Pyplot 방식)이다. 이 경우 사용자는 단순히 plt.plot() 같은 함수만 호출하며, Matplotlib 내부에서 현재 활성화된 Figure와 Axes를 자동으로 관리한다. 단순한 그래프를 빠르게 그리는 데는 편리하지만, 여러 개의 그래프를 동시에 다룰 때는 코드 가독성이 떨어지고 관리가 어려워질 수 있다.
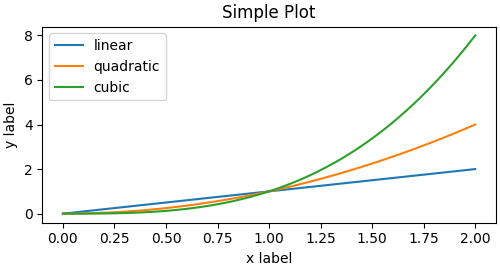
객체 지향 방식 예제
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 2, 100) # 샘플 데이터 생성
fig, ax = plt.subplots(figsize=(5, 2.7), layout='constrained')
# 서로 다른 함수 플로팅
ax.plot(x, x, label='linear') # y = x
ax.plot(x, x**2, label='quadratic') # y = x^2
ax.plot(x, x**3, label='cubic') # y = x^3
# 축과 제목 설정
ax.set_xlabel('x label')
ax.set_ylabel('y label')
ax.set_title("Simple Plot")
# 범례 추가
ax.legend()
plt.show()
위 코드는 같은 Figure와 Axes 안에 세 가지 함수를 그린다. - \(y = x\) 는 직선으로 나타나고, - \(y = x²\) 는 곡선으로, - \(y = x³\) 는 더 가파르게 증가하는 곡선으로 표시된다.
각 그래프는 서로 다른 색과 레이블을 가지며, 범례에 의해 구분된다. 결과적으로, 하나의 축 안에서 여러 데이터 시리즈를 비교하는 방법을 보여준다.
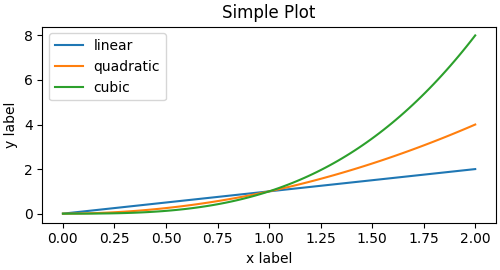
Pyplot 스타일 예시
앞서 본 객체 지향 방식(OO 스타일)과 달리, pyplot 스타일은 사용자가 Figure와 Axes를 직접 다루지 않고, Matplotlib이 내부적으로 이를 암묵적으로 생성·관리한다. 즉, plt.plot() 같은 함수를 호출하면 자동으로 현재 활성화된 Axes에 그림이 그려진다.
다음은 pyplot 스타일을 사용한 예시이다:
x = np.linspace(0, 2, 100) # Sample data.
plt.figure(figsize=(5, 2.7), layout='constrained')
plt.plot(x, x, label='linear') # Plot some data on the (implicit) Axes.
plt.plot(x, x**2, label='quadratic') # etc.
plt.plot(x, x**3, label='cubic')
plt.xlabel('x label')
plt.ylabel('y label')
plt.title("Simple Plot")
plt.legend()
실행 결과 - \(y = x\), \(y = x²\), \(y = x³\) 곡선이 한 Figure 안에 함께 표시된다. - \(x\)축과 \(y\)축 레이블, 그래프 제목, 범례가 추가되어 기본적인 비교 플롯이 완성된다.
추가 설명 세 번째 접근 방식도 존재한다.
GUI 애플리케이션에 Matplotlib을 임베딩하는 경우, pyplot을 완전히 배제하고 Figure 생성조차 직접 처리할 수 있다.
(자세한 내용은 Embedding Matplotlib in graphical user interfaces 참고)
Matplotlib 공식 문서와 예제는 객체 지향 스타일과 pyplot 스타일을 모두 사용한다.
일반적으로는 객체 지향 스타일이 권장된다. 복잡한 플롯, 큰 프로젝트, 재사용되는 함수와 스크립트에는 OO 스타일이 더 적합하기 때문이다.
그러나 pyplot 스타일은 빠른 탐색적 분석이나 대화형 작업에서는 매우 편리하다.
Artist 스타일링
Matplotlib에서 대부분의 플로팅 메서드는 Artist 객체의 스타일을 조정할 수 있는 옵션을 제공한다. 이 옵션들은 플롯 메서드(plot)를 호출할 때 인자로 직접 전달할 수도 있고, 혹은 Artist의 setter 메서드를 통해 사후에 수정할 수도 있다.
예를 들어, 아래 예제에서는 plot 함수를 이용해 선 색상(color), 선 굵기(linewidth), 선 스타일(linestyle)을 지정한다. 이후 두 번째 선에 대해서는 set_linestyle 메서드를 호출하여 스타일을 변경한다.
- set_linestyle: https://matplotlib.org/stable/api/_as_gen/matplotlib.lines.Line2D.html#matplotlib.lines.Line2D.set_linestyle
import numpy as np
import matplotlib.pyplot as plt
# -----------------------------
# 1. 데이터 준비
# -----------------------------
# 난수 시드를 고정하여 실행할 때마다 동일한 결과가 나오도록 설정
np.random.seed(19680801)
# 정규분포를 따르는 난수 100개를 누적합(cumulative sum)하여 시계열 데이터 생성
data1 = np.random.randn(100).cumsum()
data2 = np.random.randn(100).cumsum()
# -----------------------------
# 2. Figure와 Axes 생성
# -----------------------------
# 5x2.7 인치 크기의 Figure와 하나의 Axes 생성
fig, ax = plt.subplots(figsize=(5, 2.7))
# x축 값: 0부터 데이터 길이(100)까지 정수 배열
x = np.arange(len(data1))
# -----------------------------
# 3. 선 그래프 그리기
# -----------------------------
# 첫 번째 선: data1 값 시각화
# 색상: 파란색, 선 굵기: 3, 선 스타일: '--' (점선)
ax.plot(x, data1, color='blue', linewidth=3, linestyle='--')
# 두 번째 선: data2 값 시각화
# 색상: 주황색, 선 굵기: 2
# 반환값 l은 Line2D 객체로, 이후 스타일 변경에 사용됨
l, = ax.plot(x, data2, color='orange', linewidth=2)
# -----------------------------
# 4. 스타일 사후 변경
# -----------------------------
# 두 번째 선의 선 스타일을 ':' (점선)으로 변경
l.set_linestyle(':')
# -----------------------------
# 5. 그래프 출력
# -----------------------------
plt.show()
실행 결과 설명 - 번째 선은 파란색, 두꺼운 점선으로 표시된다. - 번째 선은 주황색으로 그려진 후, 스타일을 점선(:)으로 변경하였다. - 결과적으로, 동일한 데이터라도 색상, 굵기, 선 모양을 자유롭게 설정하여 가독성과 구분성을 높일 수 있다.
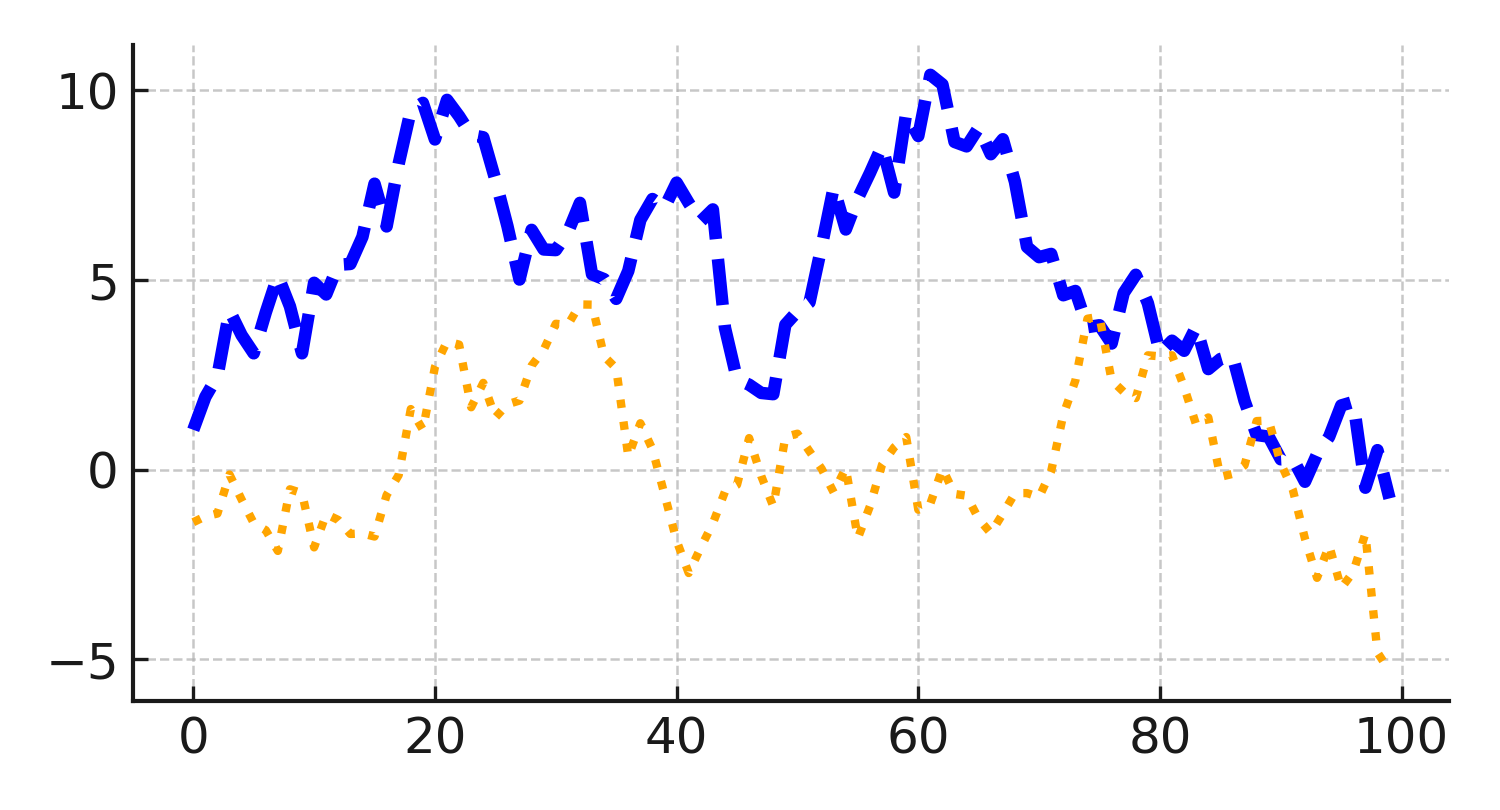
색상(Colors)
Matplotlib은 대부분의 Artist에서 사용할 수 있는 매우 다양한 색상 옵션을 지원한다. 지원되는 색상 이름과 형식은 색상 정의 문서(allowable color definitions)를 참고할 수 있다.
일부 Artist는 여러 색상을 동시에 지정할 수 있다. 예를 들어 산점도(scatter plot)의 경우, 마커 내부 색상(facecolor)과 외곽선 색상(edgecolor)을 서로 다르게 설정할 수 있다.
import numpy as np
import matplotlib.pyplot as plt
# 난수 데이터 생성
np.random.seed(19680801)
data1 = np.random.randn(100)
data2 = np.random.randn(100)
# 색상 매핑 기준 (0 ~ 1 범위)
colors = np.linspace(0, 1, 100)
# 산점도 그리기
fig, ax = plt.subplots(figsize=(5, 2.7))
scatter = ax.scatter(
data1, data2,
c=colors, # 색상 값 지정
cmap='plasma', # plasma 팔레트 적용
s=50, # 마커 크기
edgecolor='k' # 테두리 색상 (검정)
)
# 컬러바 추가
plt.colorbar(scatter, ax=ax, label="Color scale (plasma)")
plt.show()
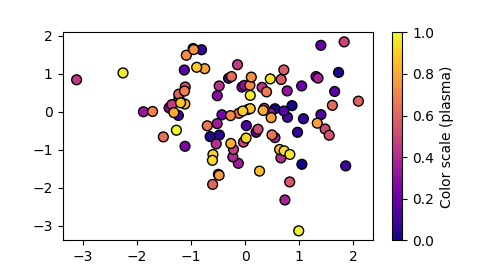
실행 결과 설명
- 각 점의 좌표는 무작위로 생성된 data1(x축), data2(y축)에 따라 배치된다.
- 각 점의 내부는 파란색(C0)으로 칠해지고, 외곽선은 검정색(k)으로 표시된다.
- facecolor와 edgecolor를 다르게 설정함으로써, 데이터의 가독성과 시각적 구분을 높일 수 있다.
- 색상은 0부터 1까지의 선형 구간 값(colors)에 따라 매핑된다.
- plasma 팔레트는 보라색에서 시작해 붉은색을 거쳐 노란색으로 이어지는 그라데이션을 제공한다.
- 따라서 작은 값은 보라색에 가까운 색으로, 큰 값은 노란색에 가까운 색으로 표현된다.
- 모든 점에는 검정색 테두리(edgecolor='k')가 추가되어 시각적으로 구분이 뚜렷하다.
- 오른쪽의 컬러바는 각 색상이 어떤 값 구간에 해당하는지 보여준다.
결과적으로, 같은 산점도라도 plasma 팔레트를 적용하면 데이터의 크기 변화를 선명하고 따뜻한 색조로 시각화할 수 있어, 값의 차이를 직관적으로 구분하기에 용이하다.
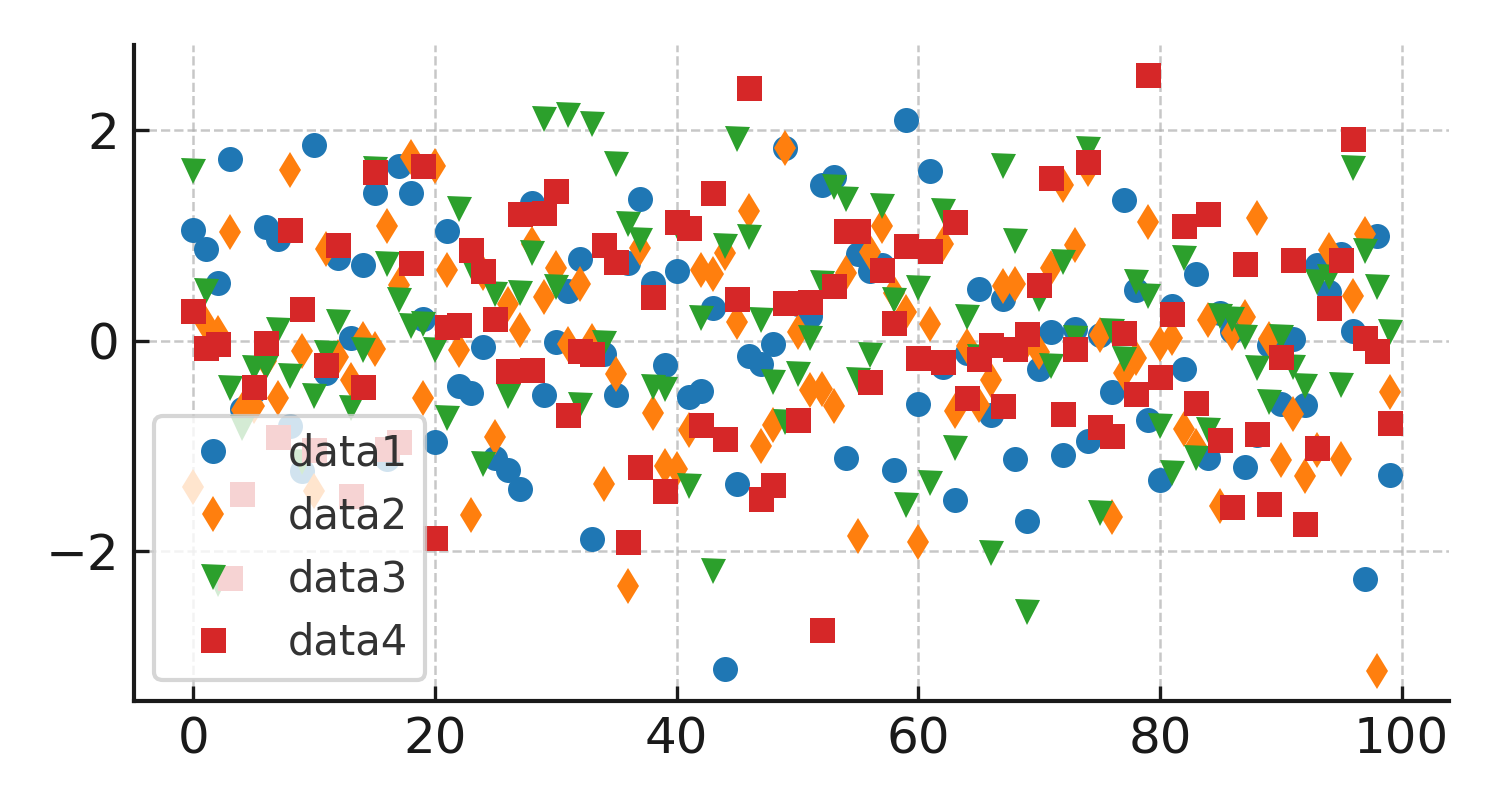
선 굵기, 선 스타일, 마커 크기
선 굵기(linewidth)는 보통 타이포그래피 포인트 단위(1 pt = 1/72 inch)로 지정된다.
모든 Artist 중 선(Line)을 가지는 객체에 적용 가능하다.
선 스타일(linestyle)은 실선, 점선, 파선 등 다양한 패턴을 지원한다.
마커 크기(markersize)는 사용하는 메서드에 따라 정의가 다르다.
- plot 함수에서 markersize는 점의 지름 또는 폭을 포인트 단위로 지정한다.
- scatter 함수에서 markersize는 점의 시각적 면적(area)에 비례한다.
- 마커 스타일: https://matplotlib.org/stable/gallery/lines_bars_and_markers/marker_reference.html
Matplotlib은 문자열 코드(예: 'o', 'd', 'v', 's' 등)를 사용해 다양한 마커 스타일을 제공하며, 사용자가 MarkerStyle 클래스를 이용해 직접 정의할 수도 있다.
import numpy as np
import matplotlib.pyplot as plt
# 난수 데이터 준비
np.random.seed(19680801)
data1 = np.random.randn(100)
data2 = np.random.randn(100)
data3 = np.random.randn(100)
data4 = np.random.randn(100)
fig, ax = plt.subplots(figsize=(5, 2.7))
# 각 데이터셋을 서로 다른 마커 스타일로 플로팅
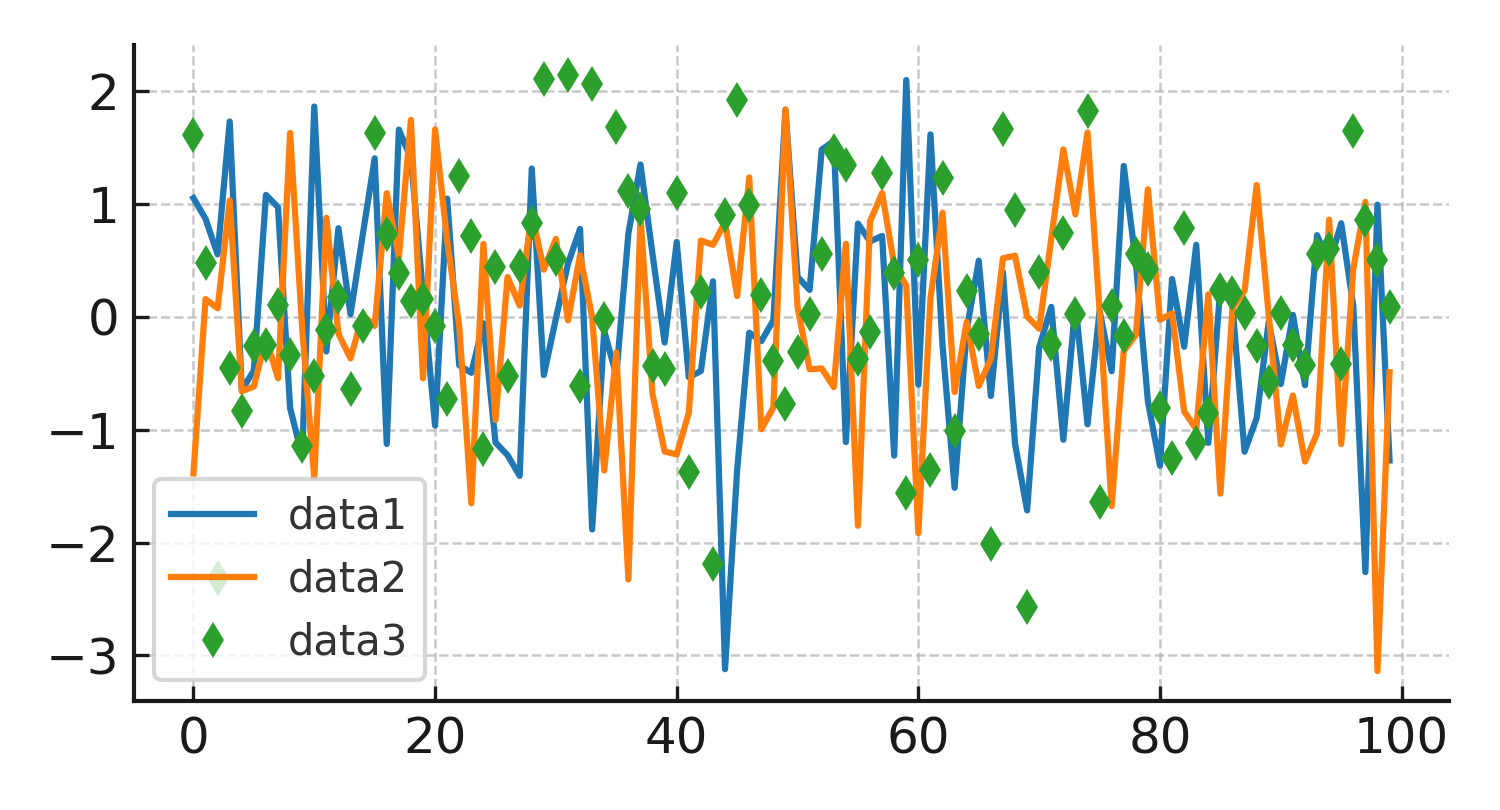
ax.plot(data1, 'o', label='data1') # 원형 마커
ax.plot(data2, 'd', label='data2') # 다이아몬드 마커
ax.plot(data3, 'v', label='data3') # 역삼각형 마커
ax.plot(data4, 's', label='data4') # 사각형 마커
# 범례 표시
ax.legend()
plt.show()
실행 결과 설명
- data1은 원형 마커 'o'로 표시된다.
- data2는 다이아몬드 모양 마커 'd'로 표시된다.
- data3은 아래쪽을 향한 삼각형 마커 'v'로 표시된다.
- data4는 네모 모양 마커 's'로 표시된다.
같은 플롯에서도 마커 종류와 크기를 다르게 지정하면 여러 데이터셋을 시각적으로 쉽게 구분할 수 있다.
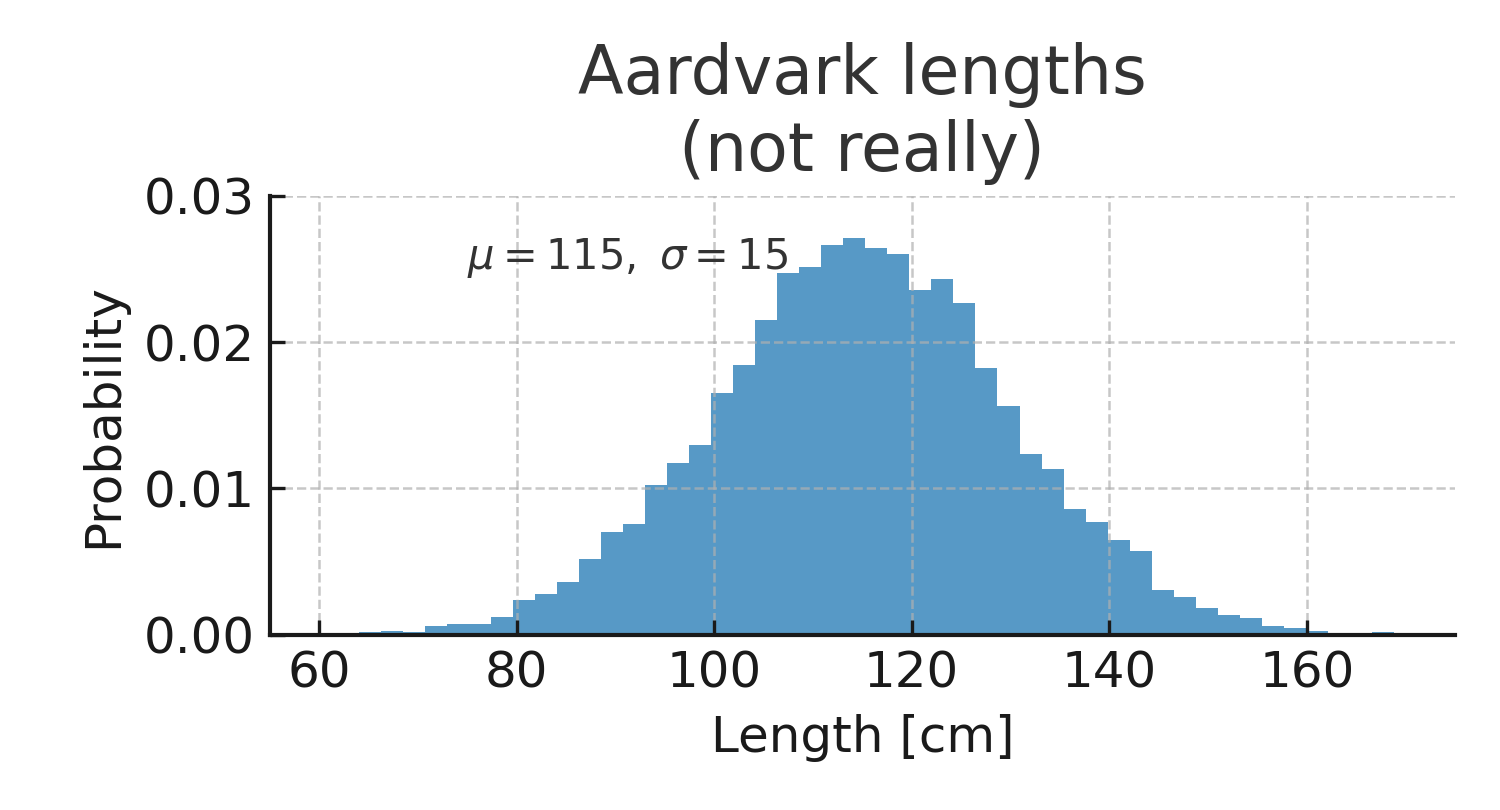
레이블과 텍스트 달기
Matplotlib에서는 그래프에 레이블과 텍스트를 추가하여 데이터의 의미를 명확하게 전달할 수 있다.
set_xlabel(), set_ylabel(), set_title() 메서드는 각각 \(x\)축, \(y\)축, 그래프 제목에 텍스트를 추가한다.
text() 함수는 플롯의 임의의 좌표에 직접 텍스트를 추가하는 데 사용된다.
import numpy as np
import matplotlib.pyplot as plt
# 데이터 생성: 평균 115, 표준편차 15를 따르는 정규분포 난수 10000개
mu, sigma = 115, 15
x = mu + sigma * np.random.randn(10000)
fig, ax = plt.subplots(figsize=(5, 2.7), layout='constrained')
# 히스토그램 그리기
n, bins, patches = ax.hist(x, 50, density=True, facecolor='C0', alpha=0.75)
# 축 레이블, 제목, 텍스트 추가
ax.set_xlabel('Length [cm]')
ax.set_ylabel('Probability')
ax.set_title('Aardvark lengths\n(not really)')
ax.text(75, 0.025, r'$\mu=115,\ \sigma=15$') # 좌표 (75, 0.025)에 텍스트 추가
# 축 범위와 격자 설정
ax.axis([55, 175, 0, 0.03])
ax.grid(True)
plt.show()
실행 결과 설명
\(x\)축에는 "Length [cm]", y축에는 "Probability"라는 레이블이 붙는다.
그래프 제목은 "Aardvark lengths (not really)"로 지정된다.
그래프 내부에 수식 형태의 텍스트 \(μ=115\), \(σ=15\)가 추가된다.
히스토그램은 평균이 \(115\), 표준편차가 \(15\)인 데이터 분포를 나타내며, 파란색 막대와 투명도(\(alpha=0.75\))로 표현된다.
축의 범위는 \(x\)축 \(55175\), \(y\)축 \(0.03\)으로 제한되며, 격자가 활성화되어 읽기 편하다.
범례(Legends)
범례는 그래프에서 여러 데이터 시리즈를 명확히 구분하는 데 중요한 요소이다. Matplotlib에서는 Axes.legend() 메서드를 이용해 손쉽게 범례를 추가할 수 있다. 범례는 선이나 마커에 붙은 label 속성을 자동으로 가져와 표시한다.
import numpy as np
import matplotlib.pyplot as plt
# 난수 데이터 생성
np.random.seed(19680801)
data1 = np.random.randn(100)
data2 = np.random.randn(100)
data3 = np.random.randn(100)
fig, ax = plt.subplots(figsize=(5, 2.7))
# 서로 다른 데이터와 레이블 지정
ax.plot(np.arange(len(data1)), data1, label='data1') # 기본 선 그래프
ax.plot(np.arange(len(data2)), data2, label='data2') # 기본 선 그래프
ax.plot(np.arange(len(data3)), data3, 'd', label='data3') # 다이아몬드 마커 사용
# 범례 표시
ax.legend()
plt.show()
실행 결과 설명 - 세 개의 데이터(data1, data2, data3)가 서로 다른 스타일로 플로팅된다. - 각 데이터셋은 label 인자를 통해 이름이 지정되고, ax.legend() 호출 시 자동으로 불러와 범례에 표시된다. - 범례는 기본적으로 그래프의 오른쪽 위에 표시되지만, 위치와 정렬은 매개변수를 통해 자유롭게 변경할 수 있다. - 이 예제에서는 data1, data2는 선 그래프로, data3은 다이아몬드 모양 마커로 표시되어 범례에 각각 다른 심볼과 함께 표시된다.
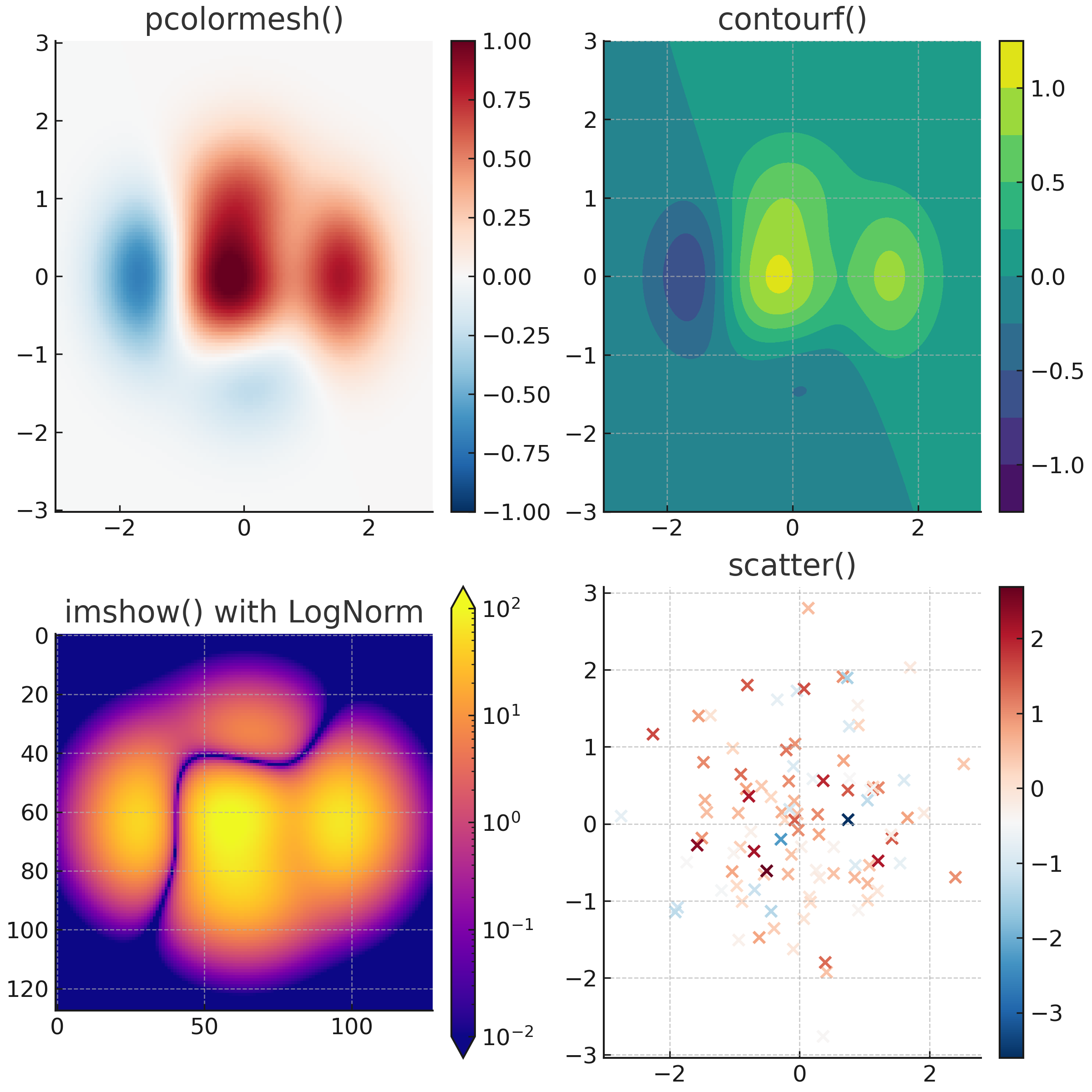
색상 맵 데이터 (Color mapped data)
데이터를 시각화할 때, 세 번째 차원을 색상으로 표현하면 더 풍부한 정보를 전달할 수 있다.
Matplotlib은 이를 위해 다양한 플롯 함수들을 제공한다. 대표적으로 pcolormesh, contourf, imshow, scatter 등이 있으며, 각각 다른 방식으로 색상 정보를 활용한다.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
# -----------------------------
# 1. 데이터 생성
# -----------------------------
# X, Y: -3 ~ 3 구간을 128등분한 격자 좌표 생성
X, Y = np.meshgrid(np.linspace(-3, 3, 128), np.linspace(-3, 3, 128))
# Z: X, Y를 이용해 계산된 함수 값 (곡면 형태)
Z = (1 - X/2 + X**5 + Y**3) * np.exp(-X**2 - Y**2)
# -----------------------------
# 2. Figure와 2x2 Axes 생성
# -----------------------------
fig, axs = plt.subplots(2, 2, layout='constrained', figsize=(8, 8))
# -----------------------------
# 3. pcolormesh()
# -----------------------------
# 격자 데이터(Z)를 색상으로 채워 넣는 함수
# cmap='RdBu_r': 빨강-파랑 반전 팔레트
pc = axs[0, 0].pcolormesh(X, Y, Z, vmin=-1, vmax=1, cmap='RdBu_r')
fig.colorbar(pc, ax=axs[0, 0]) # 색상바(colorbar) 추가
axs[0, 0].set_title('pcolormesh()')
# -----------------------------
# 4. contourf()
# -----------------------------
# 등고선 기반 색상 맵
# levels=np.linspace(-1.25, 1.25, 11): -1.25~1.25 구간을 11단계로 나눔
co = axs[0, 1].contourf(X, Y, Z, levels=np.linspace(-1.25, 1.25, 11))
fig.colorbar(co, ax=axs[0, 1]) # 색상바 추가
axs[0, 1].set_title('contourf()')
# -----------------------------
# 5. imshow() + LogNorm
# -----------------------------
# 2차원 배열을 이미지처럼 표시
# LogNorm: 로그 스케일 색상 맵 → 작은 값과 큰 값을 동시에 표현 가능
pc2 = axs[1, 0].imshow(Z**2 * 100, cmap='plasma',
norm=LogNorm(vmin=0.01, vmax=100))
fig.colorbar(pc2, ax=axs[1, 0], extend='both')
axs[1, 0].set_title('imshow() with LogNorm')
# -----------------------------
# 6. scatter()
# -----------------------------
# 점 단위로 데이터 표시, 각 점은 세 번째 데이터(data3)에 따라 색상이 달라짐
data1, data2, data3 = np.random.randn(3, 100) # x, y, 색상 값
sc = axs[1, 1].scatter(data1, data2, c=data3, cmap='RdBu_r')
fig.colorbar(sc, ax=axs[1, 1])
axs[1, 1].set_title('scatter()')
# -----------------------------
# 7. 최종 출력
# -----------------------------
plt.show()
실행 결과 설명
- pcolormesh(): 격자 데이터를 색상으로 채워, Z 값의 크기에 따라 색상이 바뀐다.
- contourf(): 등고선을 색상으로 구분하여, 값의 구간별 차이를 명확히 보여준다.
- imshow() with LogNorm: 값의 범위가 넓을 때 로그 스케일 색상 맵을 사용하여 작은 값과 큰 값을 동시에 표현한다.
- scatter(): 각 점에 대해 다른 색상을 부여하여, 데이터 분포와 함께 세 번째 차원을 시각적으로 나타낸다.
3. Seaborn Basics
Seaborn은 Python의 데이터 시각화 라이브러리로, Matplotlib을 기반으로 만들어졌다.
그러나 단순히 Matplotlib의 기능을 보완하는 수준을 넘어, 데이터 분석과 통계적 시각화를 직관적이고 간결하게 구현할 수 있도록 설계되었다.
Seaborn은 기본적으로 아름답고 일관성 있는 스타일을 제공하여, 사용자가 많은 커스터마이징 작업을 하지 않아도 시각적으로 세련된 그래프를 쉽게 얻을 수 있다.
특히 Pandas의 DataFrame과 긴밀하게 연동되어 데이터 처리와 시각화 과정을 자연스럽게 연결해 준다.
- Seaborn 공식 홈페이지: https://seaborn.pydata.org/
개발 배경
Seaborn은 Michael Waskom이 개발을 주도했으며, 처음 등장한 목적은 Matplotlib의 복잡한 설정 과정을 줄이고 “통계적 데이터 시각화(statistical data visualization)” 를 직관적으로 구현하는 것이었다. 기존의 Matplotlib만으로는 회귀선, 분포 플롯, 다변량 데이터의 관계 시각화를 구현할 때 많은 코드와 세부 설정이 필요했다. Seaborn은 이러한 과정을 단순화하여 연구자, 데이터 과학자, 학생들이 빠르게 인사이트를 얻을 수 있도록 돕는다.
개발 생태계와 활용
Seaborn은 Pandas, NumPy, Matplotlib, SciPy와 밀접하게 연결된 생태계 위에서 작동한다. 즉, Python 데이터 분석 생태계의 핵심 라이브러리들과 자연스럽게 연동된다. 현재도 활발하게 유지보수되고 있으며, Kaggle, 데이터 사이언스 수업, 논문 및 보고서 작성 등 다양한 현장에서 널리 사용되고 있다. GitHub와 PyPI에서 꾸준히 업데이트되며, 학계와 산업계 모두에서 표준적인 데이터 시각화 도구로 자리잡았다.
주요 특징
- 급 통계 시각화를 위한 함수 제공 (예: 회귀선, 카테고리형 데이터 비교, 분포 히트맵)
- 본적으로 세련된 디자인과 색상 팔레트 제공
- andas DataFrame을 직접 입력받아 컬럼 이름을 변수로 인식
- 차원 데이터 시각화 지원 (pairplot, heatmap 등)
- 간단한 코드로 복잡한 그래프 구현 가능
장점
- 코드가 간결하여 초보자도 쉽게 사용 가능
- Matplotlib보다 시각적으로 세련된 기본 스타일 제공
- Pandas와 자연스러운 연동 → 데이터 처리와 시각화가 매끄럽게 연결됨
- 통계적 분석 결과를 직관적으로 시각화 가능 (예: 회귀 분석, 분포 비교)
- 다양한 색상 팔레트와 테마 지원 → 보고서, 프레젠테이션에 적합
단점
- Matplotlib에 비해 세부적인 커스터마이징은 제한적임
- 그래프가 추상화되어 있어 복잡한 커스터마이징 시에는 Matplotlib을 직접 병행해야 함
- 대규모 데이터 시각화에는 성능 제약이 있을 수 있음
- 매우 특수한 시각화(예: 3D 시각화)는 지원하지 않음
Seaborn은 Matplotlib을 기반으로 하면서도, 데이터 과학 실무자와 연구자들이 빠르고 직관적으로 통계적 시각화를 할 수 있도록 돕는 라이브러리이다. 초보자에게는 쉽고 간단한 사용성을 제공하고, 숙련자에게는 Pandas와 Matplotlib을 연결하는 강력한 도구 역할을 한다. 데이터 사이언스 수업에서 Seaborn을 배우는 것은 시각화를 넘어, 데이터 해석력과 스토리텔링 능력을 키우는 데 중요한 밑거름이 된다.
Matplotlib vs Seaborn 비교
| 구분 | Matplotlib | Seaborn |
|---|---|---|
| 개발 배경 | Python 최초의 본격적인 시각화 라이브러리로, 다양한 그래프를 저수준에서 자유롭게 커스터마이징 가능 | Matplotlib의 복잡한 설정을 단순화하고, 통계적 데이터 시각화를 직관적으로 구현하기 위해 개발 |
| 특징 | - 저수준 API 제공 - 세부 조정 가능 - 기본 스타일 단순 |
- 고수준 API 제공 - 기본 스타일 세련됨 - Pandas DataFrame과 자연스럽게 연동 |
| 사용 난이도 | 비교적 복잡, 많은 코드 필요 | 간단한 코드로 직관적인 시각화 가능 |
| 지원 기능 | - 기본 플롯 (선, 막대, 산점도, 히스토그램 등) - 3D 플롯 지원 - 완전한 커스터마이징 가능 |
- 통계 시각화 (회귀선, 분포도, 카테고리 비교 등) - Heatmap, pairplot, violinplot 등 고급 기능 |
| 장점 | - 강력한 유연성 - 복잡한 그래프도 구현 가능 - 거의 모든 시각화 가능 |
- 시각적으로 세련된 기본 결과물 - 코드가 간결 - 통계적 시각화에 최적화 |
| 단점 | - 기본 그래프가 투박함 - 설정 코드가 많아 초보자에게 어려움 |
- 커스터마이징 제약 존재 - Matplotlib과 병행해야 할 때가 있음 |
| 활용 분야 | - 연구 논문용 고급 그래프 - 커스터마이징이 필요한 복잡한 대시보드 |
- 데이터 분석 수업, Kaggle 분석 - 탐색적 데이터 분석(EDA) - 보고서, 프레젠테이션 |
Matplotlib vs Seaborn 비교 예제
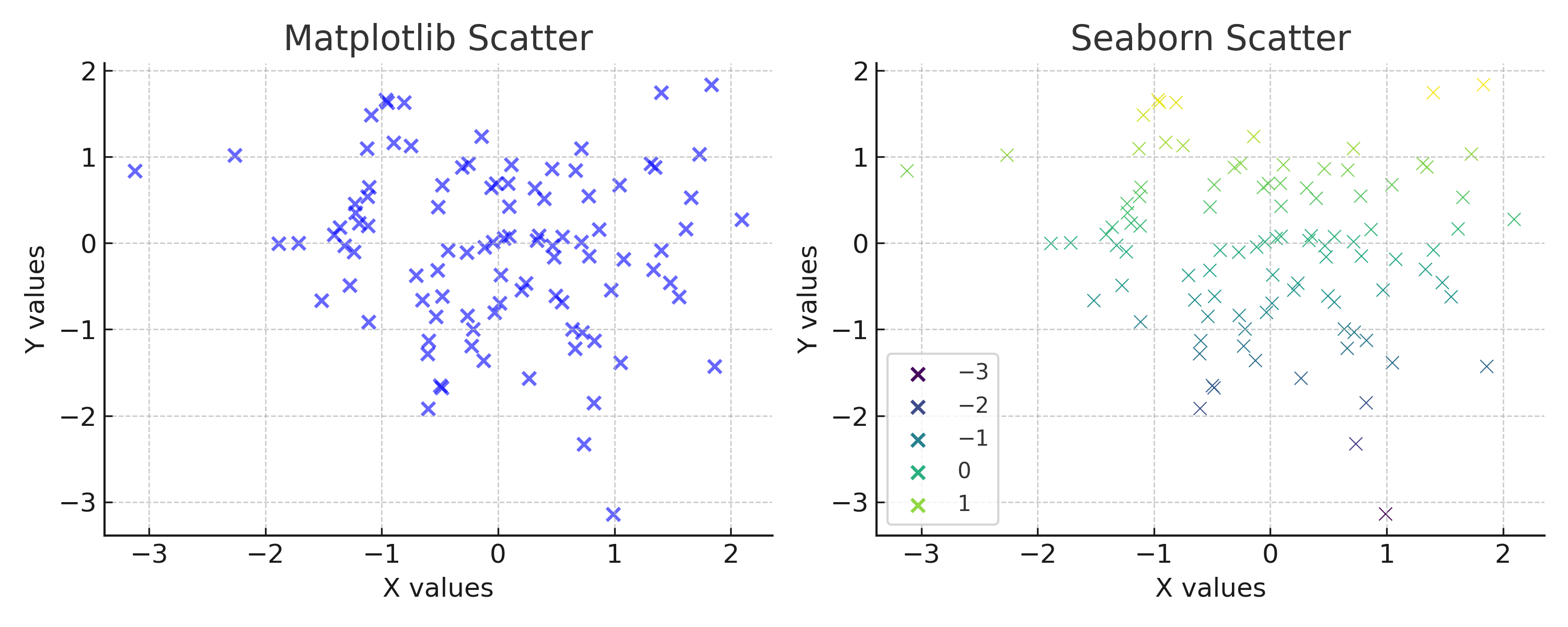
동일한 데이터셋을 산점도로 표현했을 때, Matplotlib(왼쪽)는 기본 스타일로 단순하고 직관적인 결과를 제공한다.
반면 Seaborn(오른쪽)은 색상 팔레트와 자동 스타일링을 적용하여 시각적으로 더 세련되고 데이터의 분포 차이를 강조한다.
설치
pip install seaborn
기본 문법
import seaborn as sns
import matplotlib.pyplot as plt
tips = sns.load_dataset("tips")
sns.scatterplot(data=tips, x="total_bill", y="tip")
plt.title("Total Bill vs Tip")
plt.show()
실행 결과 설명
- 식사 금액이 커질수록 팁도 늘어나는 경향을 확인 가능
- 산점도를 통해 관계의 방향성(양의 상관관계) 직관적으로 이해
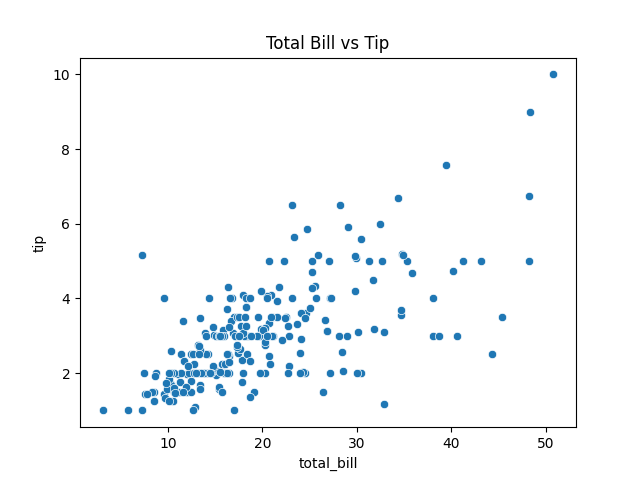
총액과 팁 관계 산점도 (가상 데이터)
중급 예제
시나리오: 요일별·시간대별 식사 비용 차이를 박스플롯으로 비교하라.
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 가상 데이터 생성
# 난수 시드 고정 → 항상 동일한 값 생성
np.random.seed(0)
days = ["Sun", "Sat", "Thur", "Fri"]
times = ["Lunch", "Dinner"]
data = []
for day in days:
for time in times:
# 각 조합에 대해 총 30개 샘플 생성
bills = np.random.normal(
loc=20 if time=="Lunch" else 25, # 정규분포의 평균
scale=8, # 정규분포의 표준편차
size=30 # 샘플 개수
)
for b in bills:
data.append({"day": day, "time": time, "total_bill": b})
df = pd.DataFrame(data)
# Boxplot 그리기
sns.boxplot(
data=df,
x="day", # x축: 요일
y="total_bill", # y축: 총 금액
hue="time", # 'time' 기준으로 색상 구분: 점심/저녁
order=days # x축 순서 지정
)
plt.title("Total Bill by Day and Time (Fake Data)")
plt.show()
실행 결과 설명
- 박스플롯의 상자, 수염, 이상치를 통해 분포의 특징을 직관적으로 파악 가능
-
박스플롯은 데이터의 분포와 이상치를 직관적으로 확인할 수 있는 대표적인 통계적 시각화 도구이다. 하나의 그래프 안에서 중앙값, 사분위수, 데이터의 범위, 그리고 이상치를 동시에 표현하기 때문에 탐색적 데이터 분석(EDA)에서 자주 사용된다.
-
중앙값(Median)
- 박스 안의 가로선이 중앙값을 나타낸다. 데이터의 절반은 이 값보다 크고, 나머지 절반은 이 값보다 작다. 분포의 중심을 파악하는 데 중요한 지표이다.
-
사분위수(Quartiles)와 박스
- 박스의 아래쪽 경계는 제1사분위수(Q1, 25% 위치), 위쪽 경계는 제3사분위수(Q3, 75% 위치)를 의미한다. 따라서 박스 자체는 데이터의 중간 50% 구간(Interquartile Range, IQR)을 보여준다. 박스가 크면 데이터가 넓게 퍼져 있고, 작으면 데이터가 모여 있다는 뜻이다.
-
수염(Whiskers)
- 박스 위아래로 뻗은 선을 수염이라고 한다. 일반적으로 Q1 - 1.5×IQR, Q3 + 1.5×IQR 범위 안에 있는 가장 작은 값과 가장 큰 값까지 이어진다. 수염은 데이터의 전반적인 분포 범위를 나타낸다.
-
이상치(Outliers)
- 수염 밖에 위치한 점들은 이상치로 표시된다. 이상치는 데이터의 변동성, 오류, 또는 특별한 패턴을 나타낼 수 있으므로 분석 과정에서 주의 깊게 해석해야 한다.
-
분포 해석
- 박스가 위로 치우쳐 있으면 데이터가 하위 값 쪽에 많이 분포한 것(왼쪽 꼬리가 김).
- 박스가 아래로 치우쳐 있으면 데이터가 상위 값 쪽에 몰려 있는 것(오른쪽 꼬리가 김).
- 중앙값이 박스의 정중앙이 아니라 한쪽으로 치우쳐 있으면 분포가 비대칭임을 의미한다.
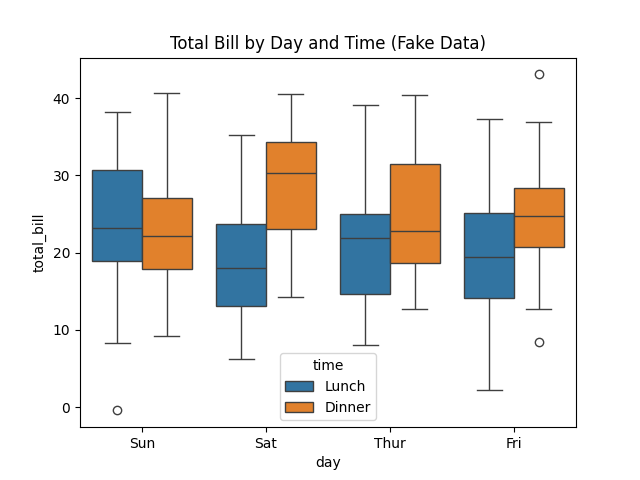
이미지: 요일·시간대별 결제 금액 박스플롯 (가상 데이터)
다양한 Seaborn 플롯 맛보기
공통 헤더 블록 (공통적으로 사용할 코드)
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Theme once
sns.set_theme(style="whitegrid")
# Reproducibility
np.random.seed(42)
n = 150
# 공통적으로 사용할 데이터
df = pd.DataFrame({
"category": np.random.choice(["A", "B", "C"], size=n, p=[0.4, 0.35, 0.25]),
"value": np.concatenate([
np.random.normal(0.0, 1.0, 60),
np.random.normal(0.5, 1.2, 50),
np.random.normal(-0.3, 0.8, 40)
]),
"group": np.random.choice(["G1", "G2"], size=n),
"feature1": np.random.normal(0, 1, n),
"feature2": np.random.normal(1, 1.2, n),
"feature3": np.random.normal(-0.5, 0.7, n),
})
# 여기에 Seaborn 플롯 별로 사용할 코드를 여기에 붙이기
# Copy & paste codes here!
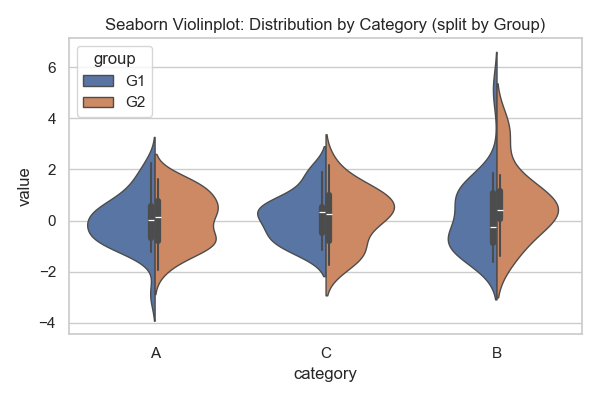
Violinplot 예시
바이올린 플롯(violinplot)은 박스플롯(boxplot)의 장점과 커널 밀도 추정(kernel density estimation)을 결합한 시각화 도구이다. 즉, 데이터의 중심값과 사분위수를 보여주는 동시에, 데이터가 어떤 모양으로 분포하는지까지 직관적으로 파악할 수 있게 한다.
우선, 플롯의 중앙에는 박스플롯과 유사한 구조가 포함된다. 중앙 선은 데이터의 중앙값을 나타내고, 사분위 구간이 박스 형태로 함께 표시된다. 따라서 violinplot을 해석할 때는 중앙값이 어디에 위치하는지를 확인하면 분포의 중심을 알 수 있다.
박스를 감싸고 있는 바이올린 모양의 외곽은 커널 밀도 함수(kernel density function)에 기반한 분포 곡선을 의미한다. 이 곡선은 특정 값 주변에 데이터가 얼마나 많이 분포하는지를 두께로 표현한다. 두꺼운 부분은 데이터가 밀집해 있는 구간이고, 얇은 부분은 데이터가 드문 구간이다. 따라서 단순히 상자 범위만 보는 박스플롯보다 데이터의 실제 분포 형태를 더 자세히 알 수 있다.
Seaborn에서 hue 옵션과 split=True를 사용하면, 두 개의 그룹 분포를 하나의 축에서 좌우로 나누어 표현할 수 있다. 이 경우 왼쪽과 오른쪽을 비교하면서 각 그룹이 어떤 값대에 밀집해 있는지, 두 분포가 대칭적인지, 혹은 한쪽이 더 치우쳐 있는지를 손쉽게 분석할 수 있다.
요약하자면, violinplot을 해석할 때는 (1) 중앙값과 사분위수로 데이터의 중심과 변동성을 확인하고, (2) 바이올린 모양의 두께로 분포 밀집 정도를 파악하며, (3) 여러 그룹을 나란히 배치한 경우 그룹 간 분포 차이를 비교하면 된다.
seaborn.violinplot: https://seaborn.pydata.org/generated/seaborn.violinplot.html
# Code snippet -> 복사하여 공통 헤더 블록의 플롯 별로 사용할 코드 영역에 붙이기
# Violinplot: 분포 모양과 중앙값, 사분위수 표현
# split=True → hue가 두 그룹일 때 두 그룹을 한 축에 나누어 그림
# Figure와 Axes 객체 생성
fig, ax = plt.subplots(figsize=(6, 4))
# Violinplot 그리기
sns.violinplot(
data=df, x="category", y="value", hue="group", split=True,
linewidth=1.0, # 테두리 선 두께
ax=ax
)
# 제목 설정
ax.set_title("Seaborn Violinplot: Distribution by Category (split by Group)")
# 레이아웃 조정
fig.tight_layout()
plt.show()
Violinplot 실행 결과
카테고리 A, B, C별 데이터 분포를 그룹(G1, G2)으로 나누어 표현하였다. 각 바이올린 모양의 두께는 해당 값 구간에서 데이터가 얼마나 밀집되어 있는지를 나타내며, 중앙의 선은 데이터의 중앙값을 표시한다. 박스플롯보다 더 풍부한 정보를 제공하여, 분포의 형태와 그룹 간 차이를 직관적으로 비교할 수 있다.
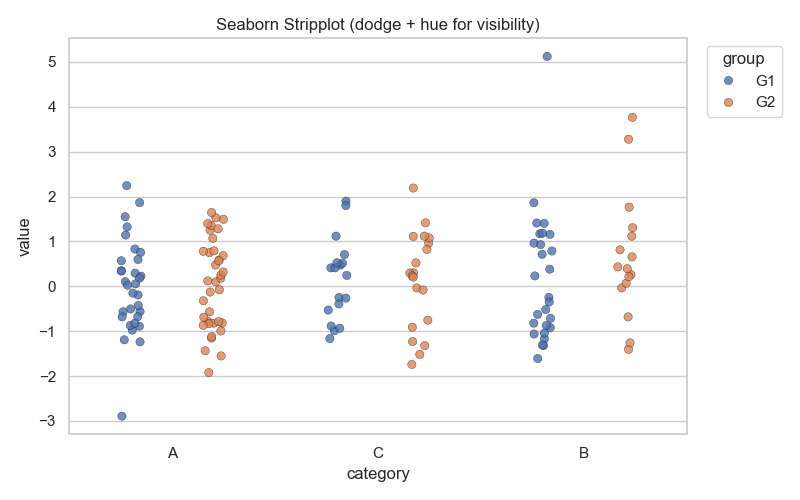
Stripplot 예시
Stripplot은 범주형 변수에 속하는 데이터들을 개별 점(point) 형태로 시각화하는 도구이다. 각 데이터가 실제 어떤 값을 가지고 있는지 그대로 표시하기 때문에, 데이터의 분포를 직관적으로 확인할 수 있다.
플롯의 가로축은 범주(category)를, 세로축은 해당 범주에 속하는 수치형 값을 나타낸다. 하나의 범주 안에 여러 개의 점이 세로 방향으로 표시되며, 이 점들이 모여서 데이터의 분포 상태를 보여준다. 점이 특정 구간에 몰려 있으면 해당 값대에서 데이터가 많이 존재한다는 의미이고, 점이 고르게 퍼져 있으면 분포가 균등하다는 의미이다.
Stripplot의 특징 중 하나는 데이터 포인트가 겹칠 수 있다는 점이다. 데이터가 많은 경우 동일한 위치에 여러 점이 겹치면서 분포가 잘 드러나지 않을 수 있다. 이 문제를 해결하기 위해 jitter 옵션을 사용하면 점들을 가로 방향으로 약간 흩뿌려 표시할 수 있다. 이때 데이터 값 자체는 변하지 않고, 시각적으로만 겹침을 줄여주는 효과가 있다.
또한 alpha 옵션을 사용해 점의 투명도를 조절하면 데이터 밀집 구간을 더 쉽게 구별할 수 있다. 값이 많은 부분은 점이 진하게 보이고, 적은 부분은 옅게 보이기 때문에 분포의 밀도를 직관적으로 해석할 수 있다.
따라서 stripplot을 해석할 때는 (1) 점들의 세로 위치를 보고 각 범주의 데이터 값의 분포 범위를 파악하고, (2) 점의 밀집 정도를 확인해 특정 구간에 데이터가 몰려 있는지 관찰하며, (3) jitter나 alpha 적용 여부에 따라 분포 해석이 더 용이해질 수 있다는 점을 이해하는 것이 중요하다.
seaborn.stripplot: https://seaborn.pydata.org/generated/seaborn.stripplot.html
# Code snippet -> 복사하여 공통 헤더 블록의 플롯 별로 사용할 코드 영역에 붙이기
# Figure와 Axes 객체 생성
fig, ax = plt.subplots(figsize=(6, 4))
# Stripplot 그리기
sns.stripplot(
data=df, x="category", y="value", hue="group",
dodge=True, # 그룹을 좌우로 분리
jitter=True, # 겹침 방지
size=6, # 마커 크기 키움
alpha=0.8, # 반투명
edgecolor="k", # 테두리로 대비 강화
linewidth=0.3, # 테두리 두께
ax=ax # ax 지정
)
ax.set_title("Seaborn Stripplot \
(dodge + hue for visibility)")
ax.legend(
title="group", # 범례 제목을 "group"으로 표시
bbox_to_anchor=(1.02, 1), # 범례 위치: 그래프 오른쪽 바깥쪽에 배치
loc="upper left" # 범례의 기준점을 왼쪽 위 모서리로 설정
# 좌표축 오른쪽 끝보다 살짝 오른쪽 (1.02),
# 그리고 맨 위 (1) 지점
)
plt.tight_layout()
plt.show()
Stripplot 실행결과
Stripplot은 범주형 데이터(category)를 기준으로 각 데이터 포인트를 개별 점으로 표현하는 시각화 방법이다. 실행 결과에서는 가로축에 범주 A, B, C가 표시되고, 세로축에는 각 범주에 속한 값(value)이 점의 위치로 나타난다. 즉, 한 점은 하나의 관측값을 의미하며, 점이 특정 범위에 많이 몰려 있으면 해당 구간에 데이터가 집중되어 있음을 알 수 있다.
이번 실행에서는 그룹(G1, G2)을 hue 옵션으로 구분하여 서로 다른 색상으로 표현하였다. dodge 옵션을 통해 각 그룹이 범주 내에서 좌우로 분리되어 나타났기 때문에, 범주별 그룹 간 분포 차이를 직관적으로 비교할 수 있다. 예를 들어, 범주 A에서 G1은 상대적으로 낮은 값에 분포하고, G2는 값이 조금 더 넓게 퍼져 있다면, 이를 통해 두 그룹의 데이터 패턴 차이를 쉽게 확인할 수 있다.
또한 jitter 옵션이 적용되어 점들이 가로 방향으로 약간 흩어져 표시되므로, 실제 값이 같은 데이터라도 겹치지 않고 보이게 된다. 이로 인해 데이터가 많은 범주에서도 값의 분포를 보다 선명하게 해석할 수 있다. 점의 크기와 투명도(alpha)는 데이터의 가시성을 높여주어 밀집된 부분과 희박한 부분을 시각적으로 구분하는 데 도움이 된다.
따라서 stripplot의 실행 결과를 해석할 때는 (1) 각 범주에서 데이터 값이 주로 분포하는 범위를 확인하고, (2) 그룹별 색상 차이를 통해 그룹 간 분포를 비교하며, (3) 점의 밀집 정도를 관찰하여 데이터의 특성과 차이를 이해하는 것이 중요하다.
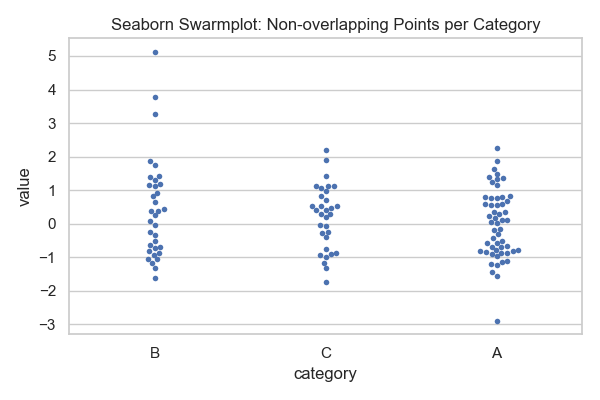
Swarmplot 예시
Swarmplot은 Stripplot과 비슷하게 범주형 데이터의 개별 값을 점으로 표시하지만, 점들이 서로 겹치지 않도록 배치된다는 점에서 차이가 있다. 즉, 데이터의 실제 값을 그대로 보여주면서도 점들이 밀집 구간에서 겹치지 않고 자동으로 퍼지도록 정렬된다.
실행 결과에서 가로축은 범주(category), 세로축은 각 범주에 속한 값(value)을 나타낸다. Stripplot에서는 데이터가 많을 경우 점들이 겹쳐 분포를 해석하기 어려운 경우가 있는데, Swarmplot은 점들을 벌집 형태처럼 배치하여 모든 데이터가 드러나도록 한다. 따라서 값의 빈도와 분포 패턴을 더 명확하게 관찰할 수 있다.
Swarmplot은 특히 데이터의 크기가 크지 않고, 각 범주의 데이터 포인트를 하나도 빠짐없이 시각화하고 싶을 때 유용하다. 예를 들어, 범주 A, B, C 각각의 값이 어떤 범위에 집중되어 있는지, 혹은 그룹 간 분포가 어떻게 다른지를 직관적으로 확인할 수 있다. 또한 hue 옵션을 사용하면 그룹별로 색상을 다르게 표시할 수 있어 범주 내 그룹 차이를 동시에 파악할 수 있다.
Swarmplot은 (1) 각 데이터 포인트를 겹치지 않게 배치하여 데이터의 개별 값을 모두 확인할 수 있고, (2) 데이터의 분포 밀집 정도를 직관적으로 이해할 수 있으며, (3) Stripplot보다 해석이 명확하다는 장점이 있다. 다만 데이터 개수가 매우 많을 경우 점이 과도하게 확산되어 해석이 어려울 수 있다는 점은 주의해야 한다.
seaborn.swarmplot: https://seaborn.pydata.org/generated/seaborn.swarmplot.html
# Code snippet -> 복사하여 공통 헤더 블록의 플롯 별로 사용할 코드 영역에 붙이기
# Figure와 Axes 객체 생성
fig, ax = plt.subplots(figsize=(6, 4))
# Swarmplot 그리기
# Swarmplot: Stripplot과 유사하지만, 점이 겹치지 않게 자동 배치
# sample(120) → 데이터 일부 샘플링 (성능 고려)
sns.swarmplot(
data=df.sample(120, random_state=0),
x="category", y="value",
size=4, linewidth=0, # 점 크기와 테두리 제거
ax=ax
)
ax.set_title("Seaborn Swarmplot: Non-overlapping Points per Category")
fig.tight_layout()
plt.show()
Swarmplot 실행 결과
Swarmplot은 범주형 데이터를 기준으로 각 데이터 포인트를 점으로 시각화하되, 점들이 서로 겹치지 않도록 자동으로 배치하는 것이 특징이다. 실행 결과에서는 가로축에 범주(A, B, C)가 나타나고, 세로축에는 각 범주에 속한 수치형 값이 점의 위치로 표현된다.
Stripplot의 경우 데이터가 많을 때 점들이 겹쳐 분포를 정확히 파악하기 어려운 경우가 있는데, Swarmplot은 점들이 서로 밀리지 않게 배치되므로 모든 개별 데이터가 화면에 드러난다. 예를 들어, 범주 A에 값이 몰려 있다면 점들이 위아래로 다소 퍼져 배치되면서 데이터가 얼마나 밀집되어 있는지 직관적으로 알 수 있다.
코드에서 사용된 df.sample(120)은 전체 데이터 중 일부를 샘플링하여 표시한 것으로, 데이터 양을 줄여 성능 문제를 완화하기 위함이다. 따라서 실제 분석에서는 더 많은 데이터를 사용할 수 있지만, Swarmplot은 데이터가 지나치게 많으면 점들이 화면에 빽빽하게 들어차 가독성이 떨어질 수 있으므로 데이터 크기에 주의해야 한다.
또한, 실행 결과에서는 점의 크기를 size=4로, 테두리를 제거하여(linewidth=0) 보다 깔끔하게 표현하였다. 이로 인해 데이터 분포를 명확히 파악할 수 있으며, 특정 범주에서 값의 퍼짐 정도나 이상치(outlier)의 위치까지 직관적으로 확인할 수 있다.
Swarmplot의 실행 결과를 해석할 때는 (1) 각 범주의 데이터가 주로 분포하는 값의 범위, (2) 데이터가 몰려 있는 밀집 구간과 퍼져 있는 희박 구간, (3) 개별 데이터 포인트의 특이 값 여부를 관찰하면 된다.
Barplot 예시
Barplot은 범주형 데이터를 기준으로 각 범주에 해당하는 수치형 데이터의 집계 통계량을 막대(bar) 형태로 시각화하는 방법이다. 가장 기본적으로는 평균값(mean)을 막대의 높이로 표시하며, 데이터의 불확실성을 표현하기 위해 신뢰구간(Confidence Interval, CI)이 함께 그려지는 경우가 많다.
실행 결과에서 가로축에는 범주(A, B, C)가 표시되고, 세로축에는 각 범주별 평균값이 막대의 높이로 나타난다. 그룹(hue 옵션)이 추가되면 각 범주 내에서 여러 그룹이 나란히 표시되어, 범주와 그룹 간의 평균 차이를 쉽게 비교할 수 있다. 예를 들어, 범주 A 안에서 G1 그룹의 막대가 더 높고 G2 그룹의 막대가 낮다면, G1 그룹의 평균 값이 더 크다는 것을 의미한다.
Barplot의 핵심 해석 포인트는 막대 높이와 신뢰구간이다. 막대의 높이는 해당 범주의 대표적인 평균값을 보여주고, 신뢰구간은 데이터의 변동성과 불확실성을 나타낸다. 신뢰구간이 겹치면 그룹 간 차이가 통계적으로 유의하지 않을 가능성이 있고, 신뢰구간이 분리되어 있으면 그룹 간 차이가 뚜렷할 수 있음을 시사한다.
또한 Barplot은 단순히 평균값뿐 아니라 합계, 중앙값 등 다양한 집계 함수(estimator)를 적용할 수 있다. 예를 들어 estimator=np.median을 지정하면 평균 대신 중앙값을 막대의 높이로 표시할 수 있다. 이를 통해 데이터의 특성과 분석 목적에 따라 유연하게 시각화를 조정할 수 있다.
Barplot의 실행 결과를 해석할 때는 (1) 막대의 높이로 범주별 대표 값을 확인하고, (2) 신뢰구간의 길이와 겹침 여부를 통해 데이터의 변동성과 차이의 뚜렷함을 판단하며, (3) 그룹별 막대 비교를 통해 범주 내 그룹 간 관계를 이해하는 것이 중요하다.
seaborn.barplot: https://seaborn.pydata.org/generated/seaborn.barplot.html
# Code snippet -> 복사하여 공통 헤더 블록의 플롯 별로 사용할 코드 영역에 붙이기
# Figure와 Axes 객체 생성
fig, ax = plt.subplots(figsize=(6, 4))
# Barplot 그리기
sns.barplot(
data=df, # 사용할 데이터프레임 (df)
x="category", # x축에 표시할 변수 (범주형 변수)
y="value", # y축에 표시할 변수 (수치형 변수)
hue="group", # 범주 그룹을 나눌 변수 (막대를 그룹별로 색상 분리)
estimator=np.mean, # y값에 대해 어떤 통계량을 계산할지 지정 (기본값은 평균 np.mean)
ci=95, # 신뢰구간(confidence interval) 설정 (여기서는 95% CI)
ax=ax # 그릴 matplotlib Axes 객체 (subplot에 그릴 때 사용)
)
ax.set_title("Seaborn Barplot: Mean with 95% CI by Category/Group")
plt.show()
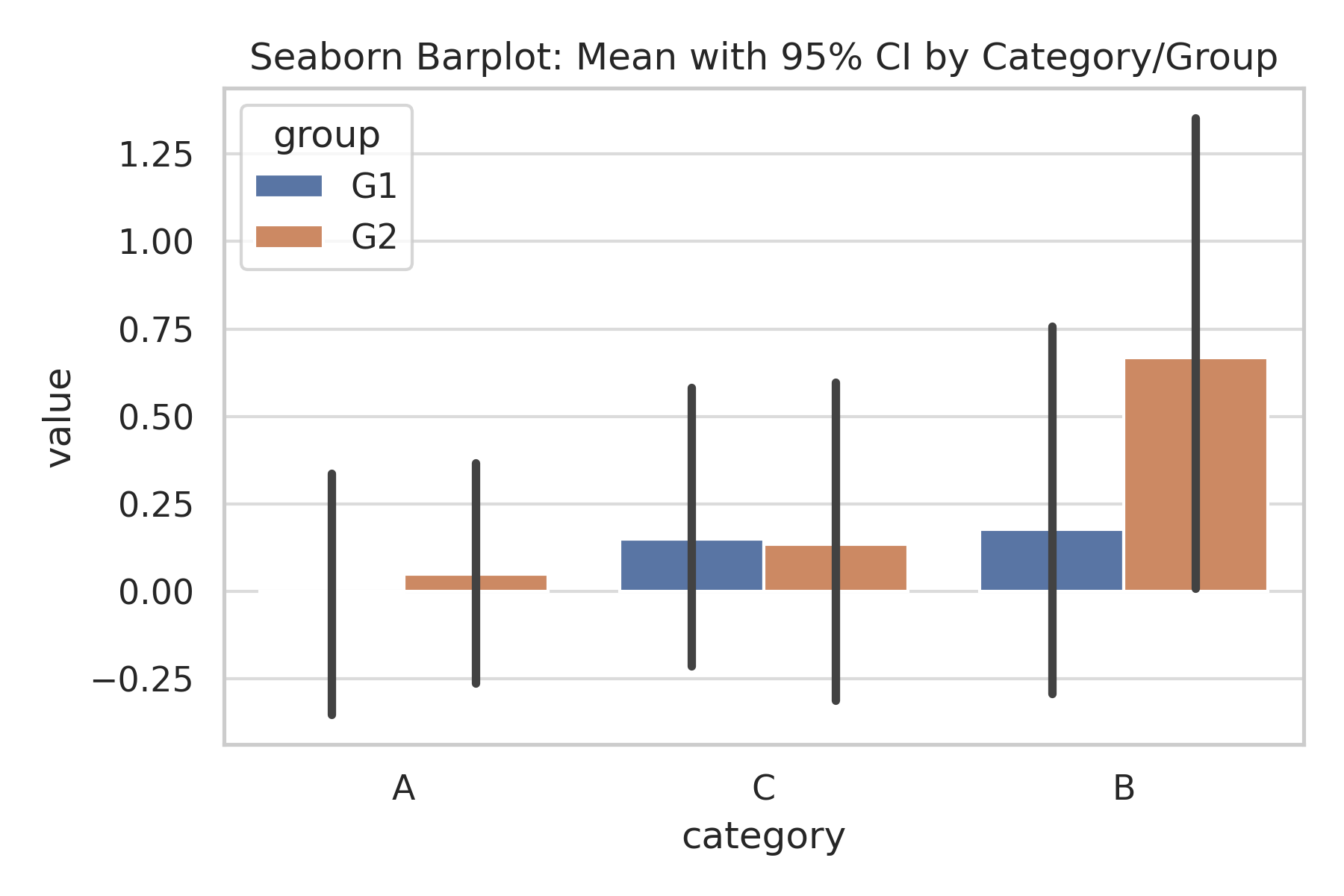
Barplot 실행결과
Barplot은 범주형 데이터에 대해 각 범주별 대표값을 막대 형태로 시각화하는 방법이다. 실행 결과에서는 가로축에 카테고리 A, B, C가 표시되고, 세로축에는 각 카테고리에 속한 값들의 평균이 막대의 높이로 나타난다.
이 그래프에서는 그룹(G1, G2)이 색상으로 구분되어 있으며, 같은 범주 내에서 두 그룹의 평균값을 비교할 수 있다. 예를 들어, 카테고리 B에서는 G2 그룹의 막대가 G1 그룹보다 높게 나타났는데, 이는 G2 그룹의 평균값이 더 크다는 것을 의미한다.
또한 각 막대 위에 표시된 검은색 세로선은 95% 신뢰구간(Confidence Interval, CI)을 나타낸다. 신뢰구간이 길다는 것은 데이터 변동성이 크다는 뜻이며, 짧을수록 평균값이 더 안정적임을 의미한다. 두 그룹의 신뢰구간이 서로 겹치는 경우에는 평균 차이가 통계적으로 뚜렷하지 않을 수 있고, 신뢰구간이 겹치지 않는다면 그룹 간 차이가 보다 명확할 가능성이 크다.
실행 결과를 해석할 때는 (1) 막대의 높이로 범주별 평균값을 파악하고, (2) 그룹 간 막대 높이 차이를 통해 그룹별 경향을 비교하며, (3) 신뢰구간의 길이와 겹침 여부를 확인하여 데이터의 변동성과 차이의 유의성을 함께 고려하는 것이 중요하다.
Countplot 예시
Countplot은 범주형 데이터에서 각 범주가 등장하는 빈도(횟수)를 막대 그래프로 표현하는 방법이다. 막대의 높이는 각 범주에 속하는 데이터의 개수를 의미하며, 데이터의 실제 값이 아니라 단순히 빈도를 기준으로 한다는 점에서 Barplot과 차이가 있다.
실행 결과에서 가로축은 범주(category), 세로축은 빈도(count)를 나타낸다. 예를 들어, 범주 A의 막대가 가장 높다면 데이터셋에서 A가 가장 자주 등장한다는 의미이다. 반대로 범주 C의 막대가 낮다면 해당 범주의 데이터가 적다는 것을 보여준다.
또한 hue 옵션을 지정하면 범주 내에서 그룹별 데이터 분포를 나란히 보여줄 수 있다. 이를 통해 단순히 전체 빈도뿐 아니라, 각 범주가 그룹에 따라 어떻게 분포되어 있는지도 비교할 수 있다. 예를 들어, 범주 B 안에서 G1 그룹의 막대가 G2 그룹보다 높다면, 범주 B에서는 G1 그룹 데이터가 더 많이 존재한다는 것을 알 수 있다.
Countplot은 특히 데이터셋의 범주형 변수의 분포를 한눈에 파악하거나, 클래스 불균형(class imbalance) 여부를 확인할 때 유용하다. 데이터 전처리 단계에서 범주별 데이터 수를 점검하거나, 분류 문제(classification)에서 학습 데이터가 불균형한지 확인하는 데 자주 활용된다.
Countplot 실행 결과를 해석할 때는 (1) 막대의 높이를 통해 각 범주의 빈도를 비교하고, (2) 그룹이 지정된 경우 그룹 간 상대적 비율을 살펴보며, (3) 데이터셋 내 범주의 불균형 여부를 확인하는 것이 핵심이다.
seaborn.countplot: https://seaborn.pydata.org/generated/seaborn.countplot.html
# Code snippet -> 복사하여 공통 헤더 블록의 플롯 별로 사용할 코드 영역에 붙이기
# Figure와 Axes 객체 생성
fig, ax = plt.subplots(figsize=(6, 4))
# Countplot 그리기
sns.countplot(
data=df, # 사용할 데이터프레임 (df)
x="category", # x축에 표시할 변수 (범주형 변수, 카테고리별 빈도를 계산)
hue="group", # 그룹 변수 (각 카테고리별로 그룹을 나눠 색상 구분)
ax=ax # 그릴 matplotlib Axes 객체 (subplot에 그릴 때 사용)
)
ax.set_title("Seaborn Countplot: Category Frequency")
ax.set_xlabel("Category")
ax.set_ylabel("Count")
plt.show()
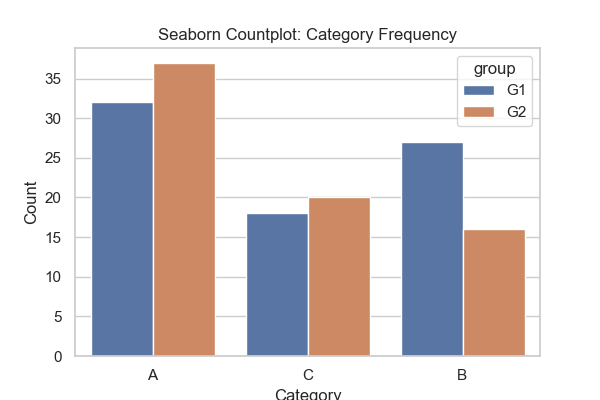
Countplot 실행 결과
Countplot은 범주형 데이터의 빈도를 막대 그래프로 표현하는 시각화 기법이다. 실행 결과에서는 가로축에 범주(category: A, B, C), 세로축에 빈도(count)가 표시되어 있으며, 각 범주별로 데이터가 얼마나 많이 존재하는지 한눈에 파악할 수 있다.
여기서는 hue 옵션을 통해 그룹(G1, G2)을 색상으로 구분하였다. 그 결과, 같은 범주 내에서도 그룹별 데이터 빈도를 비교할 수 있다. 예를 들어, 범주 A에서는 G2 그룹의 데이터가 G1 그룹보다 조금 더 많이 나타났으며, 범주 B에서는 G1 그룹의 데이터가 G2 그룹보다 많음을 확인할 수 있다. 범주 C는 두 그룹이 비교적 비슷한 빈도로 나타나지만, 여전히 G2 그룹이 소폭 우세하다.
Countplot을 해석하면, 범주별 전체 빈도 분포뿐만 아니라 그룹 간 데이터 불균형까지 동시에 확인할 수 있다. 데이터셋이 특정 범주나 그룹에 치우쳐 있는지 확인할 때 유용하며, 특히 분류 문제를 다루는 머신러닝에서 클래스 불균형 여부를 사전에 탐색하는 데 효과적이다.
Heatmap 예시
Heatmap은 데이터 행렬을 색상으로 시각화하여 각 값의 크기를 직관적으로 비교할 수 있는 기법이다. 특히 상관관계 행렬(correlation matrix)을 시각화할 때 자주 사용되며, 데이터 간의 관계를 한눈에 파악하는 데 유용하다.
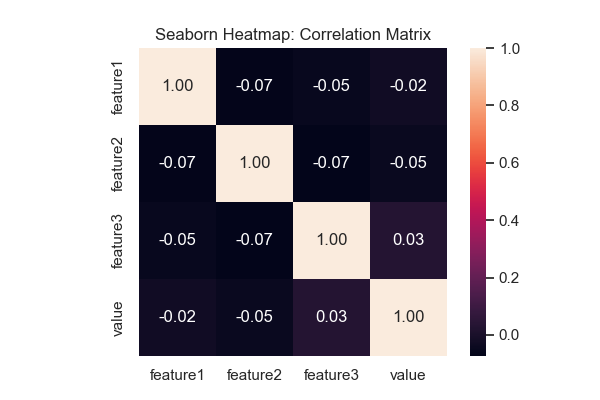
Heatmap의 기본 아이디어는 숫자 값의 크기를 색의 농도나 색상 범위로 표현하는 것이다. 값이 클수록 진하거나 특정 계열의 색상으로 표시되고, 값이 작을수록 연하거나 반대 계열의 색상으로 표현된다. 이렇게 하면 단순히 수치를 나열하는 표보다 패턴과 경향성을 쉽게 파악할 수 있다.
실행 결과에서 가로축과 세로축은 변수명을 나타내고, 각 셀은 두 변수 간의 상관계수를 색상으로 표시한다. 예를 들어, 값이 1에 가까울수록 강한 양의 상관관계를 의미하며, -1에 가까울수록 강한 음의 상관관계를 뜻한다. 값이 0에 가까운 경우에는 두 변수 간에 뚜렷한 선형 관계가 없음을 의미한다.
Heatmap은 데이터 분석 과정에서 변수 선택, 다중공선성(multicollinearity) 탐지, 변수 간 관계 이해에 매우 효과적이다. 예를 들어, 다중회귀 분석이나 머신러닝 모델링 전에 변수 간 상관관계를 파악하여 불필요하거나 중복된 변수를 제거하는 데 도움을 줄 수 있다. 또한, 색상으로 직관적인 해석이 가능하기 때문에 프레젠테이션이나 보고서에서 데이터의 패턴을 쉽게 전달할 수 있다.
Heatmap은 수치 데이터의 관계를 색상으로 시각화하여 데이터 간의 패턴, 상관관계, 분포 특성을 효과적으로 파악할 수 있게 해주는 강력한 도구이다.
seaborn.heatmap: https://seaborn.pydata.org/generated/seaborn.heatmap.html
# Code snippet -> 복사하여 공통 헤더 블록의 플롯 별로 사용할 코드 영역에 붙이기
# Figure와 Axes 객체 생성
fig, ax = plt.subplots(figsize=(6, 4))
# 상관계수 행렬 계산: 각 변수(feature1, feature2, feature3, value) 간의 상관관계
# 상관계수: -1.0 ~ 1.0 사이 실수값
corr = df[["feature1", "feature2", "feature3", "value"]].corr()
# Heatmap 그리기
sns.heatmap(
corr, # 입력 데이터 (상관계수 행렬)
annot=True, # 각 셀에 숫자(상관계수 값)를 표시
fmt=".2f", # 소수점 둘째 자리까지 표시
square=True, # 각 셀을 정사각형으로 표시
ax=ax # matplotlib Axes 객체 (subplot에 그릴 때 사용)
)
ax.set_title("Seaborn Heatmap: Correlation Matrix")
plt.show()
Pairplot 예시
Pairplot은 여러 수치형 변수 간의 관계를 한눈에 확인할 수 있도록 도와주는 시각화 기법이다. Seaborn의 sns.pairplot 함수는 데이터프레임을 입력받아, 변수 쌍마다 산점도를 그리고 대각선에는 각 변수의 분포를 나타내는 그래프(히스토그램 또는 커널 밀도 그래프)를 배치한다. 이를 통해 단일 변수의 분포와 변수 간 상관 관계를 동시에 파악할 수 있다.
실행 결과에서 각 셀은 두 변수 간의 관계를 나타내며, 점의 패턴이 직선 형태로 뻗어 있다면 두 변수 간에 강한 선형 관계가 있음을 의미한다. 반면 점들이 무작위로 흩어져 있으면 뚜렷한 선형 관계가 없다고 해석할 수 있다. 대각선에 표시된 히스토그램은 각 변수의 값이 주로 어느 범위에 분포하는지를 보여주어 데이터의 분포 특성을 이해하는 데 도움을 준다.
Pairplot은 특히 탐색적 데이터 분석(Exploratory Data Analysis, EDA) 단계에서 많이 활용된다. 예를 들어, 머신러닝 모델링 전에 변수들 간의 다중공선성(multicollinearity) 가능성을 점검하거나, 변수 간 관계가 선형인지 비선형인지 확인하는 데 유용하다. 또한 hue 옵션을 활용하면 그룹별 색상을 다르게 표시하여 범주형 변수에 따른 데이터 분포 차이도 쉽게 파악할 수 있다.
Pairplot은 (1) 각 변수의 분포를 개별적으로 확인할 수 있고, (2) 변수 쌍 간의 관계를 시각적으로 탐색할 수 있으며, (3) 그룹 구분을 통해 범주형 변수와의 연관성까지 파악할 수 있는 강력한 시각화 도구이다.
seaborn.pairplot: https://seaborn.pydata.org/generated/seaborn.pairplot.html
# Code snippet -> 복사하여 공통 헤더 블록의 플롯 별로 사용할 코드 영역에 붙이기
# 분석할 변수만 선택
sub = df[["feature1", "feature2", "feature3"]]
# Pairplot 그리기
# - 변수 쌍별로 산점도(scatter plot)를 그림
# - 대각선(diagonal)에는 히스토그램(histogram)을 표시
# - corner=True → 하삼각형 부분만 표시 (중복 제거)
# - corner=False → 상삼각형과 하삼각형 모두 표시 (모든 변수 쌍)
g = sns.pairplot(
sub, # 시각화할 DataFrame (수치형 변수만 선택)
diag_kind="hist", # 대각선에 표시할 그래프 종류 ("hist" 또는 "kde")
corner=False # 변수 쌍을 모두 표시할지 여부 (False면 전체, True면 절반만)
)
# 제목 추가
g.figure.suptitle("Seaborn Pairplot: Feature Relationships", fontsize=14)
# 여백 조정 (top을 줄여 제목 공간 확보)
g.figure.subplots_adjust(top=0.92)
plt.show()
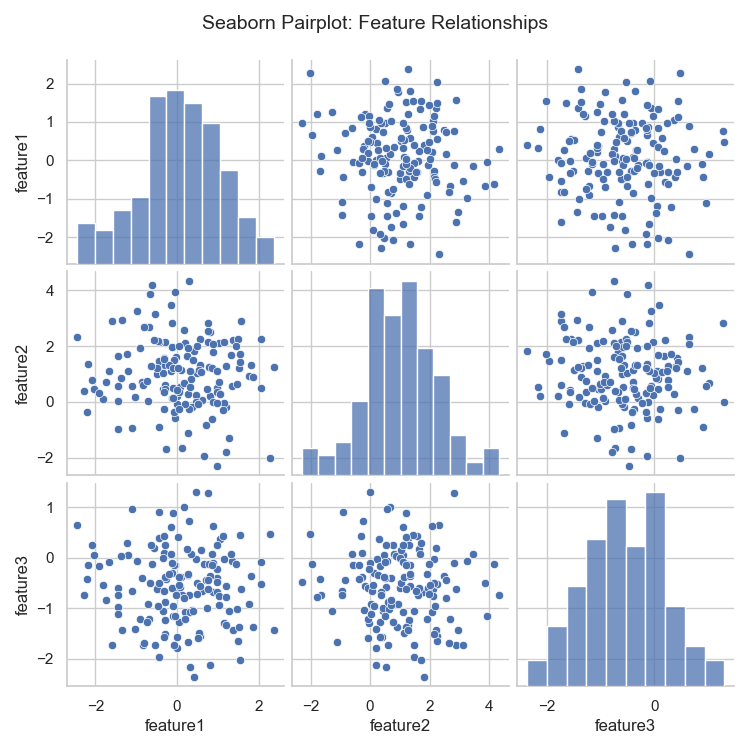
Pairplot 실행 결과
대각선에 위치한 히스토그램을 보면 각 변수의 분포 형태를 확인할 수 있다. 예를 들어, feature1은 평균이 0에 가까운 정규 분포 형태를 띠며, feature2는 평균이 1 부근에서 분포가 넓게 퍼져 있다. feature3은 평균이 -0.5 근처에서 분포하는 것을 알 수 있다.
비대각선 셀에 그려진 산점도는 두 변수 간의 관계를 나타낸다. 점들이 특정 방향으로 뚜렷한 선형 패턴을 보이지 않고 전반적으로 흩어져 있는 것으로 보아, 이 데이터셋에서는 변수들 간에 강한 선형 상관관계가 존재하지 않는다고 해석할 수 있다. 만약 점들이 대각선 형태로 밀집되어 있었다면 강한 양의 상관관계, 역대각선 형태였다면 음의 상관관계를 의미했을 것이다.
시계열 데이터 시각화
Seaborn 내장 데이터를 활용한 시계열 시각화
Dataset
Seaborn이 기본 제공하는 내장 데이터셋인 flights를 활용하여 시계열 데이터를 시각화하였다. flights 데이터셋은 1949년부터 1960년까지의 월별 항공 여객 수를 기록한 자료로, 항공 수요의 장기적인 증가 추세와 계절적인 변동성을 동시에 관찰할 수 있다는 특징을 가진다.
시각화 목표
시각화의 목표는 단순히 연도별 총 승객 수를 확인하는 데 그치지 않고, 연도별 월별 변화 패턴과 월별 장기적 추세를 각각 확인하는 것이다. 이를 통해 한 해 안에서 계절별 증감 흐름이 어떻게 나타나는지, 그리고 특정 월이 여러 해에 걸쳐 어떤 증가 추세를 보이는지를 직관적으로 이해할 수 있다.
접근 방법
먼저 flights 데이터를 long-format 상태에서 선 그래프를 작성하였다. 여기서는 X축을 월(month), Y축을 승객 수(passengers)로 두고, 연도(year)를 색상으로 구분하여 표현하였다. 이를 통해 각 연도의 월별 증감 패턴을 비교할 수 있었다. 이어서 데이터를 wide-format으로 변환하여, 연도를 X축으로 두고 각 월(month)을 하나의 시계열로 표시하였다. 이 방식은 특정 월이 여러 해에 걸쳐 어떤 추세를 보이는지를 파악하는 데 유용하다. long-format 시각화는 “연도별 계절 패턴 비교”, wide-format 시각화는 “월별 장기 추세 분석”에 초점을 두며, 동일한 데이터를 다른 시각으로 해석할 수 있음을 보여준다. 시계열 데이터를 분석할 때 데이터 포맷의 선택이 해석 결과에 큰 영향을 미친다는 점을 확인할 수 있다.
샘플 코드
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Seaborn 내장 데이터 불러오기
flights = sns.load_dataset("flights") # 항공 승객 수 데이터
# flights 데이터를 wide-format으로 변환
flights_wide = flights.pivot(
index="year", # 행 인덱스: 연도
columns="month", # 열: 월
values="passengers" # 값: 승객 수
)
# 변환 결과 예시:
# DataFrame은 각 열이 한 달을 나타내며, 행은 연도별 승객 수를 기록
# "월별 데이터의 연도별 흐름"을 동시에 파악
# month January February March ... November December
# year
# 1949 112 118 132 ... 104 118
# 1950 115 126 141 ... 114 140
# ...
# subplot 2행 1열 배치
fig, axes = plt.subplots(2, 1, figsize=(12, 10))
# (1) Long-format 데이터 시각화
# 시계열 데이터 시각화
# relplot: "relationship plot"의 줄임말
# 산점도나 선 그래프를 그릴 때 사용되는 Seaborn의 범용 함수
sns.lineplot(
data=flights, # 사용할 데이터프레임 (flights: 1949~1960 항공 여객 데이터)
x="month", # X축: 월(month) → 1월 ~ 12월
y="passengers", # Y축: 승객 수(passengers)
hue="year", # 색상 구분: 연도별(year)로 색을 다르게 표시
marker="o", # 데이터 지점마다 동그란 마커(o)를 추가하여 값이 더 잘 보이게 함
ax=axes[0], # 첫 번째 subplot(axes[0])에 그래프 그리기
)
axes[0].set_title("Monthly Air Passengers by Year (Long-format)")
axes[0].set_xlabel("Month")
axes[0].set_ylabel("Passengers")
axes[0].tick_params(axis="x", rotation=45)
axes[0].grid(True)
# (2) Wide-format 데이터 시각화
sns.lineplot(
data=flights_wide,
dashes=False, # 각 월별 시계열 구분이 명확하게 보이도록 설정
ax=axes[1]
)
axes[1].set_title("Air Passengers Trend by Month (Wide-format)")
axes[1].set_xlabel("Year")
axes[1].set_ylabel("Passengers")
axes[1].grid(True)
# 레이아웃 조정
plt.tight_layout()
# 화면에 출력
plt.show()
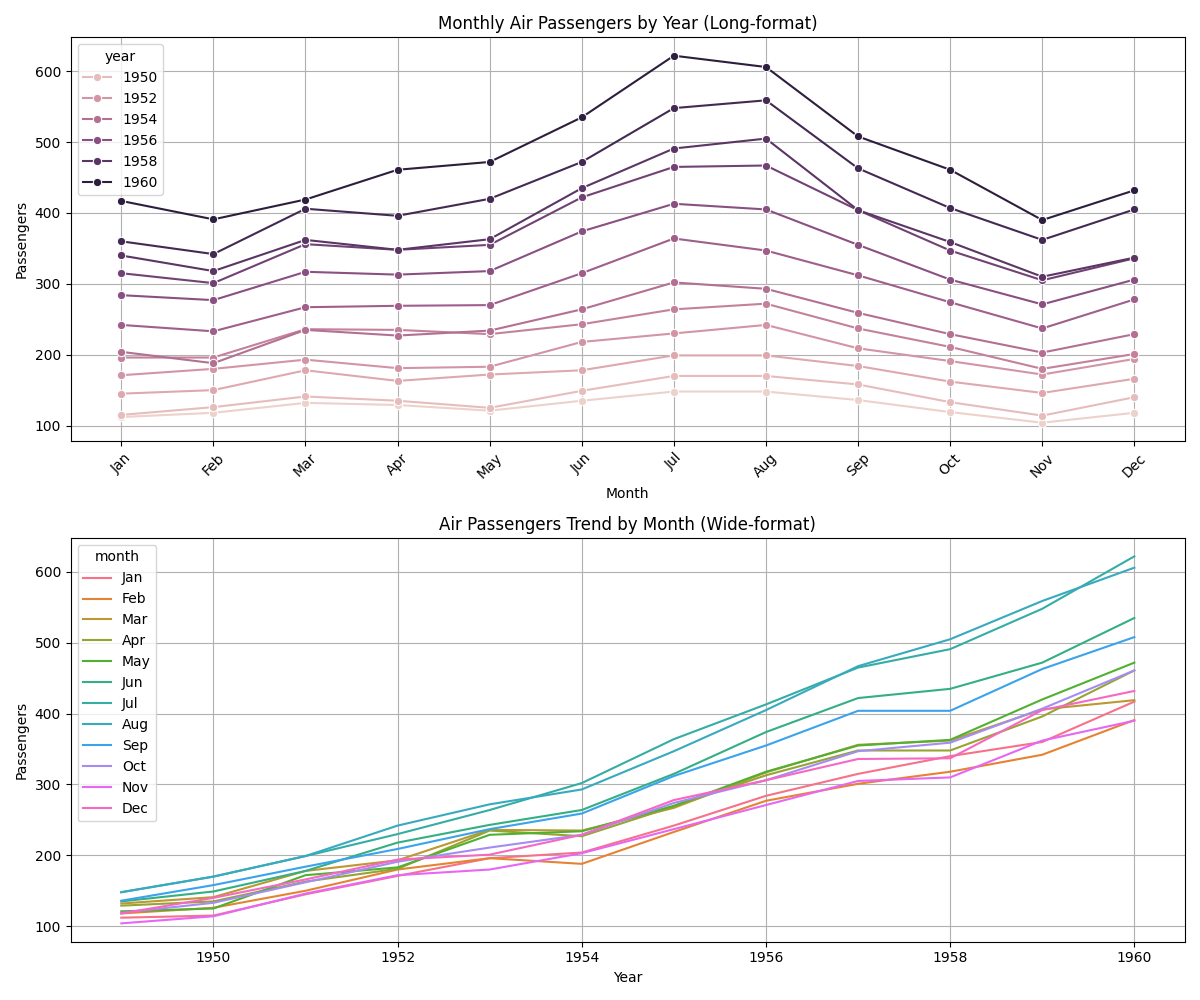
실행 결과 해석
첫 번째 그래프는 Long-format 데이터를 사용하여 연도별 월별 변화를 비교하였다. X축은 1월부터 12월까지의 월, Y축은 해당 월의 승객 수를 나타내며, 색상으로 각 연도를 구분하였다. 이 그래프를 통해 특정 해의 월별 계절 변동을 한눈에 볼 수 있다. 예를 들어, 대부분의 해에서 여름철인 7월과 8월에 여객 수가 크게 증가하고, 연말에는 다시 감소하는 계절성(Seasonality) 이 뚜렷하게 나타난다. 또한 시간이 지남에 따라 전체적으로 여객 수가 꾸준히 증가하는 추세(Trend) 를 확인할 수 있다.
두 번째 그래프는 Wide-format 데이터를 사용하여 월별 장기 추세를 연도별로 파악하였다. X축은 연도, Y축은 승객 수이며, 각 선은 특정 월을 나타낸다. 이 그래프에서는 각 월의 여객 수가 해마다 점차 증가하는 모습을 확인할 수 있으며, 특히 7월과 8월은 다른 달보다 항상 높은 수준을 유지하여 성수기임을 보여준다. 반대로 1월과 2월은 상대적으로 낮은 값으로 나타나 비수기를 시사한다.
두 시각화는 동일한 데이터를 서로 다른 관점에서 보여주고 있다. Long-format 그래프는 연도별 월별 비교에 적합하고, Wide-format 그래프는 월별 장기적 흐름을 파악하는 데 유용하다. 따라서 두 그래프를 함께 활용하면 항공 승객 데이터의 계절성과 추세를 동시에 분석할 수 있다.
사용자 데이터 활용 예제
Dataset
여러분이 수집했다고 가정한 일별 웹사이트 방문자 수 데이터를 활용한다. 데이터는 2025년 3월 1일부터 3월 30일까지 30일간의 방문자 수를 기록한 것이며, 시계열 형태의 데이터를 기반으로 한다. 실제 환경에서는 로그 분석이나 웹 트래픽 수집 도구를 통해 데이터를 확보하지만, 본 예제에서는 학습 목적을 위해 샘플 데이터를 직접 정의하였다.
시각화 목표
단순히 일별 방문자 수만 확인할 경우, 하루하루의 변동이 크기 때문에 장기적인 흐름을 파악하기 어렵다. 따라서 일별 방문자 수와 더불어 7일 이동평균(rolling mean)을 함께 시각화하여, 단기적인 변동은 완화시키고 전반적인 추세(Trend)를 확인하는 것을 목표로 한다. 이렇게 하면 특정 기간의 증가 또는 감소 경향을 직관적으로 파악할 수 있으며, 단순한 이상치(outlier)와 실제 추세를 구분하기 쉬워진다.
접근 방법
먼저 Pandas를 이용해 날짜(date)를 인덱스로 갖는 DataFrame을 구성하고, 방문자 수(visitors) 데이터를 입력한다. 그 다음, .rolling(7).mean() 메서드를 통해 7일간의 이동평균값을 계산하고 새로운 열(7d_avg)에 저장한다. 마지막으로 Matplotlib을 이용해 두 개의 선 그래프를 동시에 시각화한다. 파란색 선은 실제 일별 방문자 수를, 주황색 굵은 선은 7일 이동평균을 나타내며, 두 그래프를 비교함으로써 데이터의 단기적 변동과 장기적 추세를 동시에 관찰할 수 있다.
샘플 코드
import pandas as pd
import matplotlib.pyplot as plt
# 샘플 시계열 데이터 생성
dates = pd.date_range("2025-03-01", periods=30)
# 일반적으로 데이터를 수집하는 과정을 거쳐야 하지만, 우리는 있다고 가정함.
visitors = [100,120,115,130,150,140,160,155,170,180,
175,190,200,210,220,230,225,240,250,260,
270,265,280,290,300,310,305,320,330,340]
df = pd.DataFrame(
{
"date": dates,
"visitors": visitors
}
).set_index("date")
# 이동평균 계산
# "visitors" 열에서 7일 이동평균(rolling mean)을 계산하여 새로운 열 "7d_avg"에 저장
# - df["visitors"] : 웹사이트의 일별 방문자 수 데이터
# - .rolling(7) : 현재 행을 기준으로 이전 6일 + 현재일까지 총 7일 구간의 데이터를 묶음
# - .mean() : 묶인 7일 구간의 평균을 계산
# 각 날짜별로 그 날을 포함한 7일간의 평균 방문자 수가 "7d_avg" 열에 기록됨
df["7d_avg"] = df["visitors"].rolling(7).mean()
# 시각화
plt.plot(df.index, df["visitors"], label="Daily Visitors")
plt.plot(df.index, df["7d_avg"], label="7-day Moving Avg", linewidth=2)
plt.title("Website Visitors Trend")
plt.xlabel("Date")
plt.ylabel("Visitors")
plt.legend()
plt.show()
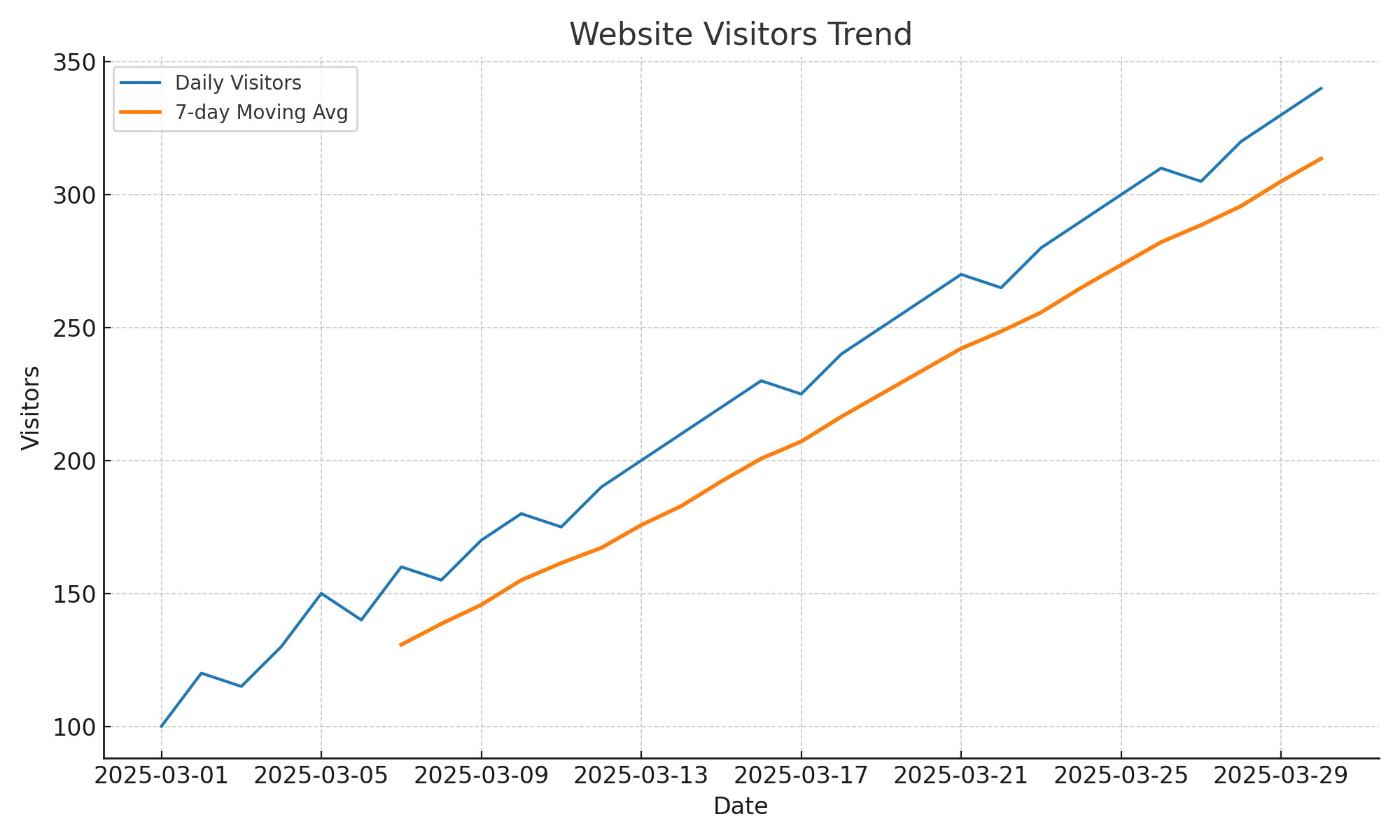
실행 결과 해석
웹사이트 방문자 수 데이터를 시계열로 표현한 그래프이다. 파란색 선은 일별 방문자 수(Daily Visitors)를 나타내며, 일정한 증가 추세를 보인다. 하지만 개별적인 일별 수치는 단기적인 변동성(상승과 하락)을 포함하고 있다. 이에 비해 주황색 선은 7일 이동평균(7-day Moving Avg)으로, 일별 변동을 완화하고 장기적인 추세를 부드럽게 보여준다. 이동평균은 초반부에는 데이터가 부족해 늦게 시작되며, 시간이 지남에 따라 점차 일별 방문자 수의 전반적인 증가 경향을 안정적으로 반영한다. 따라서 이 그래프는 단기적 변동과 장기적 추세를 동시에 비교할 수 있도록 해주며, 웹사이트 성장 패턴을 명확히 파악하는 데 도움을 준다.