Introduction to Data Science
학습목표
이 장에서는 데이터사이언스의 개념과 필요성을 이해하고, 데이터 기반 문제 해결의 전 과정을 학습한다. 또한 데이터사이언티스트의 역할과 실제 산업계 응용 사례를 통해 데이터사이언스를 어떻게 공부하고 활용해야 하는지에 대한 가이드를 제시한다.
데이터사이언스란 무엇인가
데이터사이언스는 다양한 데이터로부터 의미 있는 정보를 추출하고, 이를 기반으로 예측, 분류, 최적화와 같은 문제를 해결하는 학문이다. 통계학, 수학, 컴퓨터공학, 그리고 도메인 지식이 융합된 형태이며, 21세기 ‘가장 매력적인 직업’으로 불릴 정도로 산업 전반에 걸쳐 중요한 분야로 자리 잡았다.
데이터사이언스는 단순히 데이터를 수집하고 분석하는 것을 넘어, 실제 문제 해결과 의사결정 지원에 핵심적인 가치를 제공한다. 예를 들어, 의료 분야에서는 환자의 재입원 가능성을 예측하고, 금융 분야에서는 부도 위험을 조기 탐지하며, 유통 산업에서는 고객의 구매 행동을 분석하여 맞춤형 서비스를 제공한다.
데이터 기반 문제 해결 프로세스
데이터사이언스의 핵심은 문제를 정의하고 데이터를 기반으로 해답을 찾아내는 체계적 과정이다. 일반적으로 다음의 7단계로 요약된다.
문제 정의
데이터 분석의 첫 단계는 해결하고자 하는 문제를 명확히 정의하는 것이다. 문제 정의는 분석 방향과 목표를 결정하는 핵심 단계이며, 잘못된 정의는 잘못된 결론으로 이어질 수 있다. - 산업계 성공 사례: 통신사에서 ‘이탈 고객’을 정의하고 이를 예측하기 위한 모델을 구축하여 수익 감소 방지 - 실패 사례: 한 온라인 쇼핑몰은 ‘구매율’을 목표로 설정했으나, 실제로는 사이트 방문자의 체류 시간만 늘리는 결과로 이어져 사업적 성과 미달
데이터 수집
데이터는 웹, 데이터베이스, 센서 등 다양한 소스에서 수집된다. 수집 데이터의 품질과 신뢰성이 분석 성패를 좌우한다.
# 예시: 뉴스 기사 수집 (웹 크롤링)
import requests
from bs4 import BeautifulSoup
url = "https://news.ycombinator.com/"
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
titles = [item.text for item in soup.select(".titleline > a")]
print(titles[:5])
['Zed, a code editor written in Rust',
'Show HN: Minimal web server in Python',
'Ask HN: Best resources to learn Rust?',
'YC application tips',
'New AI breakthrough in NLP']
데이터 전처리
수집한 데이터는 결측치, 이상치, 중복값 등을 포함한다. 이를 처리하지 않으면 모델의 신뢰성이 저하된다.
# 예시: Pandas를 활용한 전처리
import pandas as pd
df = pd.DataFrame({'age': [25, None, 30, 120, 28]})
df['age'] = df['age'].fillna(df['age'].mean()) # 결측치 처리
df = df[df['age'] < 100] # 이상치 제거
print(df)
age
0 25.0
2 30.0
4 28.0
탐색적 데이터 분석 (EDA)
EDA는 데이터의 구조와 특성을 파악하는 과정이다. 히스토그램, 상관분석, 시각화를 통해 데이터의 패턴을 찾는다.
# 예시: 히스토그램 시각화
import matplotlib.pyplot as plt
values = [25, 30, 28, 35, 40, 32, 31]
plt.hist(values, bins=5)
plt.title("Age Distribution Histogram")
plt.xlabel("Age")
plt.ylabel("Frequency")
plt.show()
- 산업계 사례: 보험사에서 고객 연령별 사고율을 시각화하여 상품 가격 정책 수립
모델링
데이터를 활용해 예측, 분류, 군집화 등의 모델을 구축한다.
# 예시: 선형회귀 모델
from sklearn.linear_model import LinearRegression
import numpy as np
X = np.array([[1], [2], [3], [4]])
y = np.array([100, 150, 200, 250])
model = LinearRegression().fit(X, y)
print("예측값:", model.predict([[5]]))
- 성공 사례: 제조업에서 불량품 예측 모델을 구축하여 생산 효율성 향상
평가 및 검증
모델 성능은 정확도, F1-score, RMSE 등 지표로 평가된다. 검증을 통해 오버피팅, 언더피팅을 진단하고 개선해야 한다.
from sklearn.metrics import mean_squared_error
y_true = [100, 150, 200, 250]
y_pred = [110, 140, 210, 240]
rmse = mean_squared_error(y_true, y_pred, squared=False)
print("RMSE:", rmse)
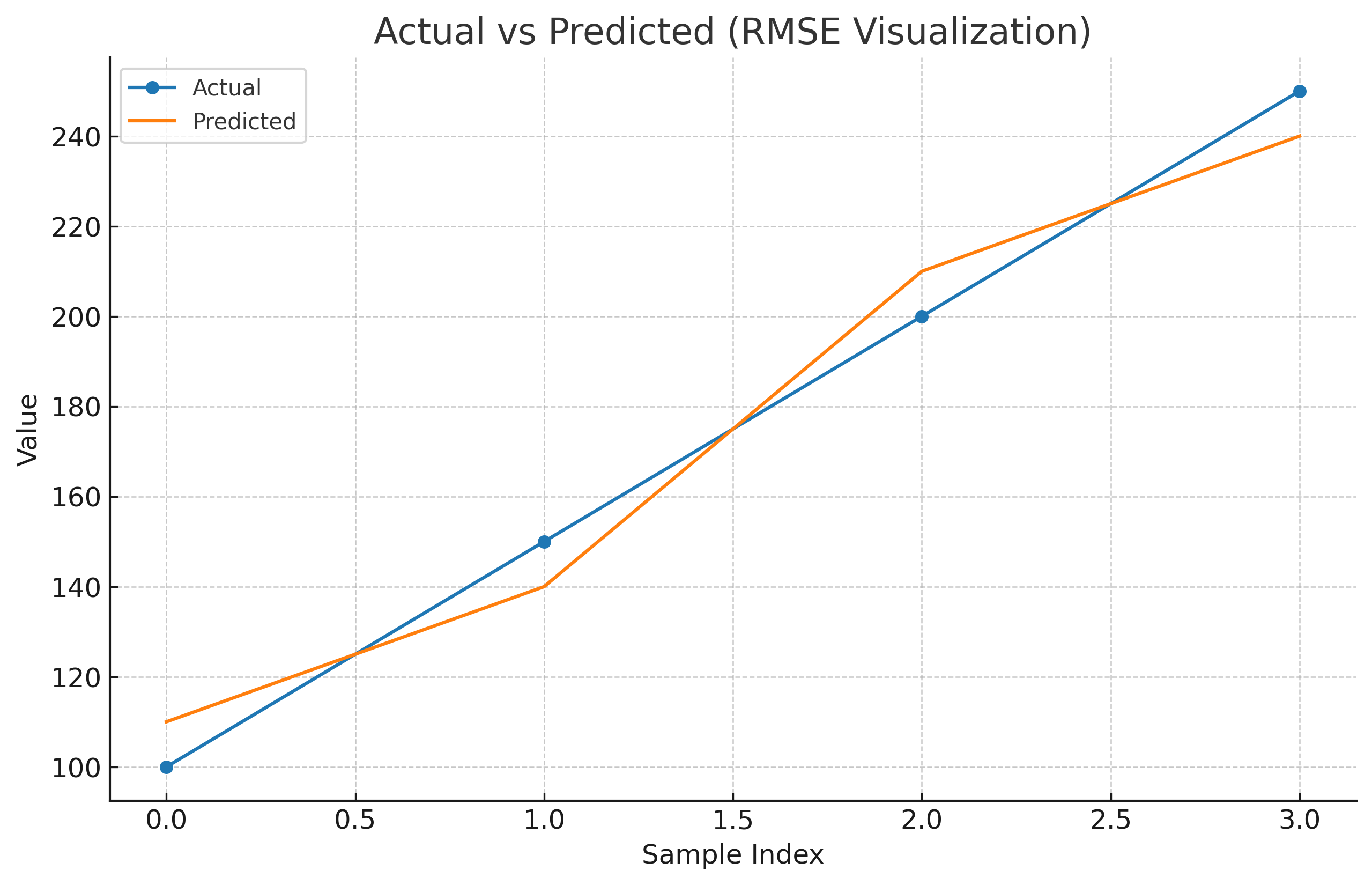
결과 해석 및 의사결정 지원
모델 결과를 단순히 출력하는 데 그치지 않고, 실제 의사결정과 전략으로 연결하는 것이 중요하다. 예를 들어, 고객 이탈 예측 모델 결과를 바탕으로 특정 고객군에 집중 마케팅을 집행할 수 있다.

데이터사이언티스트의 역할
데이터사이언티스트는 단순한 기술 전문가를 넘어 비즈니스 문제 해결자이자 데이터 기반 의사결정 지원자이다. 주요 역할은 다음과 같다.
- 데이터 수집 및 관리 수행
- 데이터 분석 및 시각화 수행
- 모델 개발 수행
- 인사이트 제공
- 의사결정 지원
- 협업 수행
데이터사이언티스트에게는 기술적 역량과 더불어 문제 정의 능력, 커뮤니케이션, 협업 능력이 요구된다.
학생을 위한 가이드라인
소프트웨어 관련 학과 학생이라면 데이터사이언스를 학습할 때 다음의 점을 유념해야 한다.
- 수학·통계 기초 학습
- 프로그래밍 능력 강화 (Python, SQL, R)
- 작은 프로젝트 경험 축적 (예: Kaggle, 공공데이터)
- 산업계 문제 분석 경험
- 협업 능력 배양
핵심 요약
- 데이터사이언스는 데이터 기반 문제 해결을 지원하는 융합 학문
- 문제 정의 → 수집 → 전처리 → EDA → 모델링 → 평가 → 결과 해석의 프로세스 수행
- 데이터사이언티스트는 기술적 전문가이자 문제 해결자로서 다양한 산업 분야에서 핵심 역할 수행
- 학생들은 수학·통계·프로그래밍 역량을 키우고 작은 프로젝트 경험을 통해 데이터사이언스 역량 축적